
At the beginning are the triples
An introduction to Dgraph core concepts through hands-on.
The hands-on examples are a way to better under ...
Learn more

In this blog, we will introduce the concept of “Entity Resolution” and its relevance. We will discuss three aspects of Entity Resolution: Data Standardization, Duplicate Detection, and Data Merging. Finally, we will use Dgraph to model a “Person” entity, add some example data and demonstrate Dgraph’s capabilities that support Entity Resolution on the Person entity.

Entity Resolution typically requires specialized processing steps. These include data standardisation, duplicate detection, and data merging. We will go through a brief description of each process to understand the context.

Data Standardization involves tight control of the values associated with certain attributes. For example, you may want to operate a clean reference list of countries and state names from an ISO standard, as opposed to a free-flow entry of these attributes. This ensures that the information stored is not ambiguous. You may apply a policy where any customer data not containing a country name from the clean reference list gets rejected. This forces usage of high-quality data, which in turn results in higher confidence of data stored in the database.
In the process of data standardization, you try to match the existing value of an attribute to a clean list. When a suitable match is found, you “hook” or connect the attribute to this clean list, making it available for any subsequent processes. In this blog series, we will demonstrate how you can take an ISO value for a country and use it to standardize customer data.
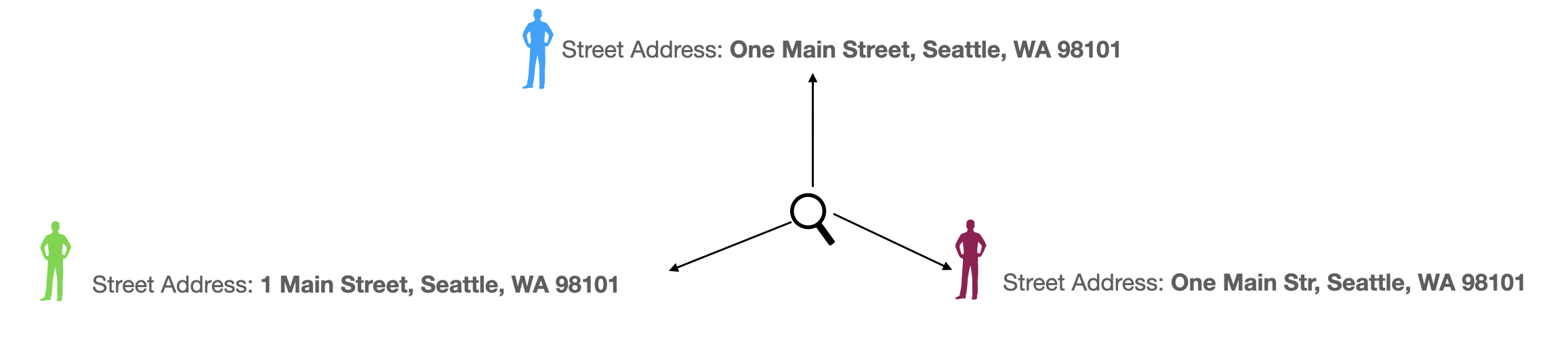
This process is critical in uniquely identifying an entity. In distributed systems, there is often a lack of a single unique “ID” attribute that can disambiguate and uniquely identify an entity. Thus, every entity needs to be frequently compared with other entities in the system to identify and establish uniqueness. In other words, if the attributes of an entity are not the same as any other entity within the current system, you can declare it as unique, at least in that particular system.
You can pick which attributes are critical in the makeup of an entity. For example, a name and address might be essential for a person or organization, whereas a text description could be critical for products.
Due to human error or other unavoidable circumstances, there may be slight spelling variations in a name or address. As a result, when comparing attributes, you cannot go by approaches that involve exact matches exclusively. This is why the duplicate detection mechanism usually takes a more flexible approach to achieve matches. These include fuzzy text matching, and probability-based duplicate detection approaches, etc. Dgraph provides text indices that allow strong and fuzzy text comparisons. These indices let you perform matches at scale and on-demand.

Once you have identified duplicates, you will find that these duplicates might have the same values for their attributes while others may have different values - some duplicates have an empty attribute value. It’s often not straightforward to understand how to resolve available values of attributes into a single golden copy. For example, the lastest timestamp may prove the deciding factor in mobile numbers, while an insured address may be preferable as a residence address.
The process of data merging is all about identifying a unique golden value for a given attribute while detecting potential conflicts, determining the right mechanism (last updated, source of an attribute, etc.) to break the deadlock, and finally, saving this value for the attribute. The final set of attributes is often called a “golden record.” Additionally, the decision-making mechanism needs to be auditable so that business processes down the line have confidence in using the golden record attributes.
Dgraph provides a sophisticated query language and data structures that allow us to “construct” this golden record from candidates. We can do this in a manner that is entirely expressible in the form of a graph and visible to stakeholders. These features make activities in this complicated process transparent and command higher confidence in the data.
Let us now demonstrate how Dgraph can help with a simple scenario. Here are the schema and the mutation to set up the example.
<country>: uid @reverse .
<countryName>: string @index(term) .
<duplicated>: [uid] @count .
<name>: string @index(exact, trigram) .
<otherNames>: [string] @index(exact) .
<streetName>: string @index(trigram) .
<tag>: string @index(exact) .
type <Country> {
name
otherNames
}
{
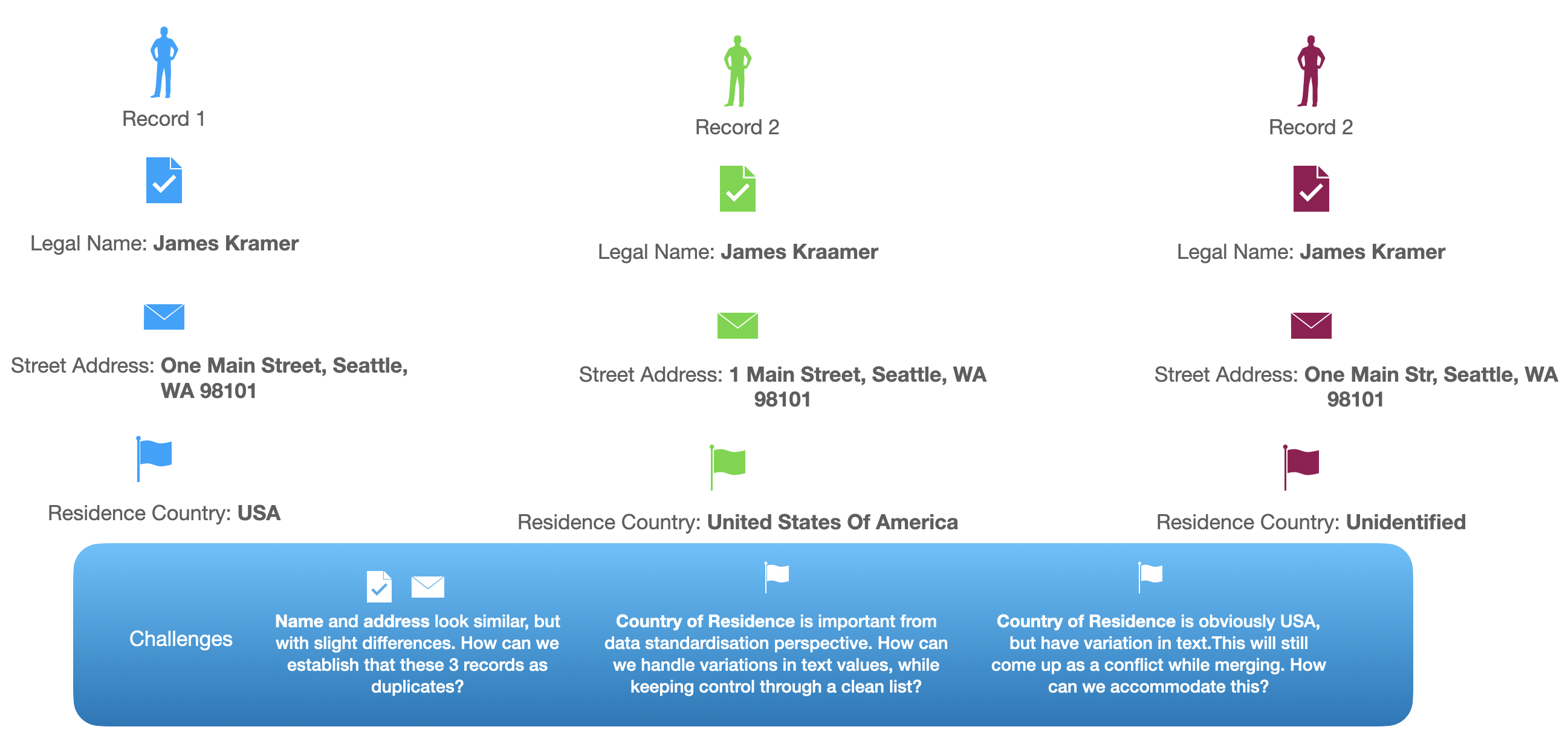
set{
_:p1 <dgraph.type> "Person" .
_:p1 <name> "James Kramer" .
_:p1 <streetName> "One Main Street, Seattle WA 98101" .
_:p1 <countryName> "USA" .
_:p2 <dgraph.type> "Person" .
_:p2 <name> "James Kraamer" .
_:p2 <streetName> "1 Main Street, Seattle WA 98101" .
_:p2 <countryName> "United States Of America" .
_:p3 <dgraph.type> "Person" .
_:p3 <name> "James Kramer" .
_:p3 <streetName> "One Main Str, Seattle WA 98101" .
_:p3 <countryName> "Unidentified" .
_:usa <dgraph.type> "Country" .
_:usa <name> "USA" .
_:usa <otherNames> "United States Of America" .
_:usa <otherNames> "U.S.A." .
_:usa <otherNames> "U.S." .
_:usa <otherNames> "US" .
}
}
streetName), and a country name for a Person is provided.Country type which will store country names as per ISO code with allowed aliases (otherNames).Person records as per the scenario discussed are created.USA is created as a valid 3-character abbreviation for the Country type, as well as allowed aliases.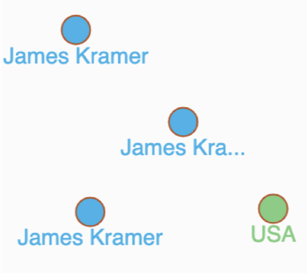
The picture above shows how the data looks in Ratel, a web UI built by Dgraph that helps to explore Dgraph elements including schema, data and cluster visually. Please note that these nodes are distinct and no relationship between them has been asserted.
Let us now begin processing of the data stored in Dgraph. As part of our process, we will first standardize the data; then, we will detect duplicates, and finally figure out the conflicts and resolution mechanisms involved in merging.
As a first step, we want to link the country attribute (countryName) of the Person records with the corresponding Country node.
upsert{
query{
qCountryOfPerson(func: uid(0x1) ) {
cn as countryName
}
qMatchWithISOCountry(func: type( Country)) @filter( eq(name,val(cn))
OR eq(otherNames,val(cn)) ){
standardCountryUID as uid
standardName as name
}
}
mutation @if( gt(len(standardName),0) ) {
set{
uid(cn) <country> uid(standardCountryUID) .
}
}
}
Result of this upsert query is visualized in Ratel as below.
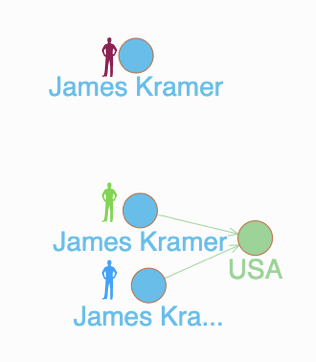
upsert query is executed for each Person entity by passing in its uid. The countryName attribute is compared with either the 3-character ISO code (name) or any of the allowed aliases (otherNames).Country is confirmed by the @if check.Country node exists, the Person nodes are linked.Person nodes again, and this time we’ll find that two of the nodes which had the appropriate ISO code or an approved alias are now connected to the corresponding country node. In other words, we can say that the person’s country value is now standardized.This standardization will prove beneficial for several other business processes down the line. There will be no need to remember ad-hoc representations of country names, and all querying can be driven off these standards-based Country nodes.
We can now go person by person and tag duplicates. In the query below, a person (uid 0x1) is being matched with others in the system on the streetName attribute.
upsert{
query{
qGetStreetNameOfPerson(func: uid(0x1)){
snSource as streetName
snName as name
}
q1(func: type(Person)) @filter(match(streetName,val(snSource),4)
and match(name,val(snName),2)) {
snTarget as streetName
}
v as var(func: eq(tag,"0x1-match"))
}
mutation @if( gt(len(snTarget),0) ) {
set{
uid(v) <duplicated> uid(snTarget) .
uid(v) <duplicated> uid(snSource) .
uid(v) <tag> "0x1-match" .
}
}
}
The view from Ratel after the duplicate detection has run for this person is as below.
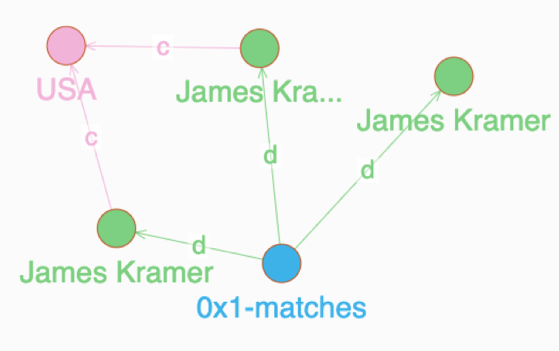
uid 0x1 points to one of the Person nodes. This node is matched on name and streetName attributes with other Person nodes in the system.match function checks for street name similarities within a distance of four characters. We also do a similar check for the name attribute within a distance of two characters. Please refer to the Dgraph documentation on fuzzy matching for more information here.With duplicates now tagged, we can then move on to the task of merging attribute values into a single golden record. This task involves selecting a particular value for each attribute from the duplicates and nominating it as the final golden attribute value. This set of golden attributes is often called a golden record and will be used in all downstream business processes such as spend analytics, fraud detection, reporting, etc. Let us assume that the uid 0x5 is the parent node of tagged duplicates for the person James Kramer.
{
qConflictOnCountry(func: uid(0x5)) @normalize{
duplicateCount: count(duplicated)
duplicated{
c as count(country)
countries as country
}
countryValuesAvailable: sum(val(c))
}
qUniqueCountries(func: uid(countries)) {
uniqueCountryNodes: count(uid)
uniqueCountryNodeName: name
}
}
Query Response:
{
"data": {
"qConflictOnCountry": [
{
"duplicateCount": 3,
"countryValuesAvailable": 2
}
],
"qUniqueCountries": [
{
"uniqueCountryNodes": 1
},
{
"uniqueCountryNodeName": "USA"
}
]
}
}
The task of merging can be simple or complex, depending on the attribute involved. In our case, selecting a street name may be as simple as picking the first one amongst the duplicates. This is because we used the street name as an attribute for detecting duplicates. However, this is not the case for the country attribute. Remember that while two of the records had a clean country node attached, one of them had none. You can see this by running the query qConflictOnCountry. Out of three duplicate nodes, only two nodes have valid country data available.
In this case, we may apply a conflict resolution business rule that states: “If the valid countries available in the duplicate converge to any single value, we will pick this value as a golden record”. This business rule is translated into the query qUniqueCountries. We can see that indeed there is one unique country node, and the value is USA. This can now be used as the final golden value for the person’s Country attribute.
A collection of such conflict detection and resolution rules can be proposed for each attribute to complete the merging activity, and the final set of attributes for the Person can be defined.
In this blog post, you learned the intricacies involved in Entity Resolution. Dgraph fully supports executing the business processes involved. In this walkthrough, we used Dgraph’s capability to store, dynamically link, and traverse nodes to achieve each process’s needs. Finally, Dgraph is a fast, transactional database, which allows such scenarios to be executed in an on-demand manner. This set of diverse capabilities, now also available as a fully managed service (https://dgraph.io/cloud), will help you achieve your goals of higher confidence in data, customer intimacy, and effective fraud detection.
Interested in getting started with Dgraph? You can get started here. Please say hello to our community here; we will be glad to help you in your journey!
