
Product recommendation using RAG on Dgraph
In this blog post, we will use Dgraph database to store retail products information (Amazon products data ...
Learn more

An introduction to Dgraph core concepts through hands-on.
The hands-on examples are a way to better understand each concept by experiencing directly with Dgraph. They are not a substitute for product documentation.
You can start in seconds by provisioning a Dgraph Cloud instance
In the Dgraph Cloud console, click Launch new backend.
For this blog, we will work without schema (more on this in the next episode) : in the Dgraph cloud console, click Settings and set Schema mode to flexible.

Ratel is a graphical data visualization tool. On your cloud instance access “Ratel” in the left Menu.
You can perform all steps using a local Learning Environment with a Dgraph instance, and Ratel UI running in docker containers.
Dgraph is all about interconnected data. The W3C uses the term “Semantic Web” to refer to the Web of linked data and RDF is one the Semantic Web Standards for data interchange. The RDF 1.1 introduced a very simple yet powerful representation allowing structured and semi-structured data to be mixed, exposed, and shared across different applications. Its main focus is to name the relationships between things as well as the two ends of the link (this is usually referred to as a “triple”). Dgraph is using a simplified version of the standard. It is so simple that it takes the form of a line of text with 4 elements and a final dot, all separated by a space. It is important to understand how powerful and transformative this simple approach is as it is one of the underlying principles of Dgraph.
Let’s look at an example.
<_:jedi1> <character_name> "Luke Skywalker" .
<_:leia> <character_name> "Leia" .
<_:sith1> <character_name> "Anakin" (aka="Darth Vador",villain=true) .
<_:sith1> <has_for_child> <_:jedi1> .
<_:sith1> <has_for_child> <_:leia> .
The 4 elements of the notation are
Those lines could be read as
character_name “Luke Skywalker”,character_name “Leia”,character_name “Anakin”. The character_name of ‘sith1’ has a characteristic ‘aka’ equal to “Darth Vador” and “villain” equal true.has_for_child with the thing referred to as ‘jedi1’.has_for_child with the thing referred to as ‘leia’.Comments
We can see those simple lines as a list of facts. They represent certain information and knowledge (at one point in time it was even a revelation).
We will save those facts directly in Dgraph.
As you can store facts aka knowledge in Dgraph as a graph, the term “knowledge graph” is sometimes used.
We have used the term thing for the subject because nothing is enforcing a specific semantic for the subject. As a generic term, we prefer node or entity rather than thing.
The notation _:jedi1. It is called a blank node in the RDF specification. It is a temporary identifier of the node. It means that we don’t have a better way to reference the node we are talking about, but as we need to reference the same node in the next lines, as subject or object, we just refer to it as <_:jedi1> in this group of lines.
The object part may be an entity <:sith1> <has_for_child> <:jedi1>. In that case it’s natural to see the predicate as a relationship.
The object part may be a literal value. <_:jedi1>
Let’s play with Dgraph
In Ratel Console, Select Mutate tab

Mutate data in Ratel
and enter
{
set {
<_:jedi1> <character_name> "Luke Skywalker" .
<_:leia> <character_name> "Leia" .
<_:sith1> <character_name> "Anakin" (aka="Darth Vador",villain=true).
<_:sith1> <has_for_child> <_:jedi1> .
<_:sith1> <has_for_child> <_:leia> .
}
}
and hit RUN.
Check the JSON response tab:
{
"data": {
"code": "Success",
"message": "Done",
"queries": null,
"uids": {
"jedi1": "0x1",
"leia": "0x2",
"sith1": "0x3"
}
},
...
Dgraph has successfully saved the facts and it also tells us that it has given unique identifiers for the blank nodes that we have provided. We can use those identifiers to add or change facts about the entities.
Just copy the jedy1 identifier ( 0x01 in this case) And run another mutation.
{
set {
<0x01> <eye_color> "blue".
}
}
It’s time to retrieve information from Dgraph using a query.
{
characters(func:has(character_name)) {
character_name @facets
eye_color
has_for_child { character_name }
}
}
This query can be understood as
character_name.character_name of the found entities with all the attached characteristics (facets).eye_color so give me that info too.has_for_child predicate. If it exists it links to another entity and I want to know the character_name of that entity.Select Query and copy-paste the request and hit RUN.
Select the Graph tab to display the result … Et voilà.
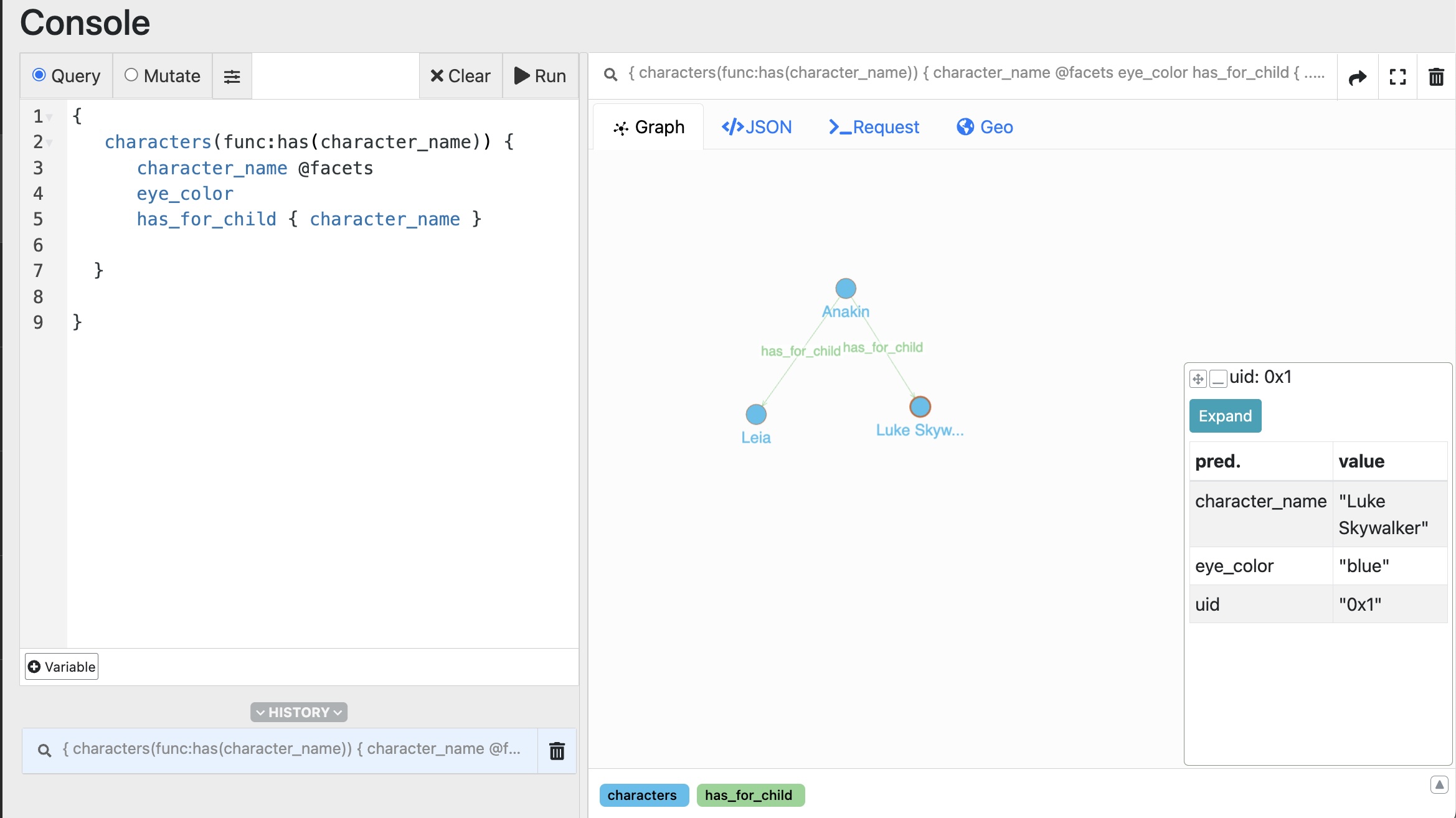
Triples represented as a Graph.
Your first graph shows 3 entities and two relations.
If needed, move the nodes in the visualization to better see the relation name.
Select Luke to display the panel with the attributes for this node.
As you are curious, click on the JSON tab, it displays a JSON format of the query response :
{
"data": {
"characters": [
{
"character_name": "Luke Skywalker",
"eye_color": "blue"
},
{
"character_name": "Leia"
},
{
"character_name|aka": "Darth Vador",
"character_name|vilain": true,
"character_name": "Anakin",
"has_for_child": [
{
"character_name": "Luke Skywalker"
},
{
"character_name": "Leia"
}
]
}
]
}
,...
We will dig into that later but the most remarkable point here is that the response has exactly the structure of the query. It makes it a very powerful tool for client applications as they always know the structure of the response even with dynamically created queries. This capability is referred to as being “declarative” : we declare what we are interested in.
Questions
What happened to my identifier _:jedi1 ?
<_:jedi1> was a temporary identifier. It is valid in the context of the transaction: all RDF lines in the same transaction referencing <_:jedi1> are referencing the same entity. Dgraph has generated a unique id for it and it was returned when we submitted the mutation. The ‘jedi1’ identifier is not saved by Dgraph.
You can easily decide to add a triple to the transaction to save the “fact” that jedi1 is an identifier for you.
So simply add
<_:jedi1> <identifier> "jedi1" .
Note: the convention is to use “xid” for external id as the predicate.
What if I run the mutation again ?
If you submit the mutation
{
set {
<_:sith1> <character_name> "Darth Vador".
<_:jedi1> <character_name> "Luke Skywalker" .
<_:sith1> <has_for_child> <_:jedi1> .
}
}
Again, Dgraph will see temporary identifiers and so will generate new entities with new internal ids for them. You may want to avoid creating duplicate information. In this case you will have to check the existence of the entities, using the external id or any criteria, before adding the information. This is done with an upsert mutation.
entities having attributes and relations between the entities.nodes and edges : the kind of drawing we do when we sketch relations between things.References
https://www.w3.org/TR/n-quads/
Photo by cottonbro studio
