
Dgraph v21.12: Zion - The Last City Standing
We are excited to announce Dgraph v21.12 Zion release. Zion release has MAJOR performance optimizations, ...
Learn more

The blog post by ZDNet made it to HackerNews front page. Do engage in discussion there, and show us love by giving us a GitHub star.
I’m really excited to announce that Dgraph has raised $11.5M in Series A funding. This round is led by Redpoint Ventures, with investment from our previous lead, Bain Capital Ventures, and participation from all our existing investors – Blackbird, Grok and AirTree. With this round, Satish Dharmaraj joins Dgraph’s board of directors, which includes Salil Deshpande from Bain and myself. Their guidance is exactly what we need as we transition from building a product to bringing it to market. So, thanks to all our investors!
And thanks to all our users who continue to believe that databases haven’t peaked their capabilities. That a different approach is possible and can help make their lives significantly easier as data and queries grow in size and complexity.
This blog post is a detailed, expanded version of my pitch to investors showing the need for a technology like Dgraph and why I think it can play a much bigger role in the future. If you just want the deck, you can jump to the end of this blog post.
The graph database space is not as “sexy” as the relational database space.
While every venture which changes the hairstyle of the SQL horse gets money thrown at them, investing in the graph car is a way more judicious call. It requires recognition of the fact that datasets are getting more complex while databases serving them have stayed largely the same for the last 20 years, causing companies to stick graph solutions on top of relational databases with spit and tape.
It is tempting to brush off the graph problem as a niche. But, when you see the same problem being solved at many different companies with millions of dollars being spent, the word niche doesn’t come to mind. A look at the state of these solutions is enough to give an idea for the need of a scalable graph database. Here are some excerpts taken from published information about graph efforts being done at companies along with relevant links.
… allowed developers to read and write the objects (nodes) and associations (edges) in the graph, and direct access to MySQL was deprecated for data types that fit the model. TAO implements a graph abstraction directly, allowing it to avoid some of the fundamental shortcomings of a lookaside cache architecture. TAO continues to use MySQL for persistent storage, but mediates access to the database and uses its own graph-aware cache. — Facebook TAO
As Airbnb moves towards becoming an end-to-end travel platform, it is increasingly important for us to deliver travel insights … To scale our ability to answer these travel queries, we needed a systematic approach to storing and serving high-quality information about entities … and the relationships between them … spent the past year building a knowledge graph — Airbnb Knowledge Graph
Having to write SQL and interact with MySQL directly impacted developer productivity. In the same vein, schema evolution was brittle and error-prone. Edgestore is a service and abstraction over thousands of MySQL nodes that provides users with strongly consistent, transactional reads and writes at low latency. Objects in Edgestore can be Entities or Associations … Associations describe how different Entities relate to each other — Dropbox Edgestore and again
“who’s following both of these users?” These features are difficult to implement in a traditional relational database. Our goals were: Write the simplest possible thing that could work. FlockDB is a database that stores graph data, but it isn’t a database optimized for graph-traversal operations. — Twitter FlockDB
However, building systems that provide such recommendations presents a major challenge due to a massive pool of items, a large number of users, and requirements for recommendations to be responsive to user actions and generated on demand in real-time. Here we present Pixie, a scalable graph-based real-time recommender system that we developed and deployed. — Pinterest Pixie
What do these queries have in common? Deep, complex join structure. Large fan-out and Skew. What do we need? Fast and efficient joins. Without Graph, client handles Query, moves data to client’s query processor. Limited number of entities can be fetched due to client’s network bandwidth limitation, cannot execute large fan-out queries. Latency for multi-hop queries can be prohibitive due to too many roundtrips to data tier. Limited opportunities for query optimization. — LinkedIn Liquid
In addition to these, I have written about Google’s efforts about graphs here and there’s a presentation by Uber here.
All of the above are Silicon Valley companies. Let’s make a simple extrapolation to judge how much money is being thrown at this problem. A senior backend engineer would on average cost 250K in the bay area (base salary, bonus, equity, medical, perks). Assuming that on average these projects each have 10 engineers working on them (backend and devops), it costs the company around $2.5M a year to build a new graph system.
We are talking about an entirely new graph system. In most cases, this new system is a database, built on top of a SQL DB. Having done this before, I can safely say that building a graph database on top of another database, is like building a SQL database on top of CSV files. You get some of the functionality quickly, but you don’t get any of the guarantees. And the rest of the functionality (speed, indices, transactions) would drag out the engineering efforts until you have almost built an actual database, something that most likely you were trying to avoid by using an existing one.
The typical design pattern here is building a graph layer on top of many MySQL database instances. It has obvious advantages: Horizontal scalability, flexible schema, simpler data models and graph operations. But it comes with a lot of downsides. So, what doesn’t work?
Performance: This is a big killer. The performance of a graph layer would never match what’s possible when the database and storage itself is optimized for graph operations. In addition, a typical graph query can have a large fan-out of millions of intermediate results. Having to repeatedly query and retrieve all that data from DB to the graph layer significantly affects query latency and throughput.
Indexing: Indexing is the real power that databases bring to the user. They make queries search for information fast. The typical storage model used by TAO and others is to store a graph edge as a row in the DB. This model does not inform the meaning of the predicate to the DB. For example, an edge containing a date can’t be indexed differently from an edge containing a string or a node. The indexing logic which would understand graph edges would need to be handled outside by the layer.
Transactions: While a SQL DB can provide transactions, hundreds of isolated SQL instances can’t provide transaction across them. This affects correctness particularly when many edges form a subgraph, which could be located across different instances, causing them to be updated by different transactions (we’ll touch upon NewSQL databases later).
Correctness: If indices are not being managed by the database (and additionally, transactions don’t cover data and index manipulation together), then any given read can be inconsistent. For example, a user can show as having written a comment, but the list of comments on the post might not reflect that user or might not show the correct comment count. In fact, (I would bet that) a sophisticated Jepsen bank test should immediately fail on any of the graph layer databases built. All that correctness logic would need to be handled by the application, which means more custom code in the backend.
Replication: An eventually consistent replication per DB instance (as provided by MySQL) married with the serialization of a subgraph across many instances would produce nondeterministic snapshots, to say the least.
All of these problems are hard to solve. In certain situations, it might be okay to just ignore those problems, but that decision inherently causes the solution to be too custom to be generally adopted by other companies or even worse, other use-cases within the same company.
Some of these issues can be alleviated by using a NewSQL database, which provides horizontal scalability with distributed transactions. However, even a NewSQL database implementing a graph layer would not solve the performance and indexing issues. And performance as a requirement itself changes solutions dramatically.
If most consumer facing companies would not spend a penny on building a new SQL database, then why would they spend millions of dollars on building a new graph database? Truth be told, the existing graph database offerings are not as mature. Many of these companies mentioned above, did try to find a scalable, fast graph database that can meet their needs. They couldn’t.
At the time, we didn’t have a production-ready graph database — Airbnb
At the time, no off-the-shelf solution met all our requirements — Dropbox
Ultimately, they abandoned the search and built something in-house. But that approach only works for a select few.
Most companies do not have the capability or the desire to spend millions of dollars on building a custom graph database. Yet, they do have the same needs as experienced by these above mentioned companies — horizontal scalability, performance, multiple data silos or models which need to be served together, treating relationships just as importantly as the data itself, avoiding denormalization and data duplication, flexible schema, and simplifying their backends by making the database do more than just arranging things in rows and columns.
Furthermore, as with building any new system, particularly a database, it takes years of effort to wrinkle out all the issues and make it work in a general enough way that it can be applied to multiple use-cases. Even then, the results are not a given. Projects get “sunset”: Twitter FlockDB lays abandoned since its initial launch. So, making that large engineering bet to build a graph layer, which might not work out, is a serious decision.
That’s exactly what inspired the creation of Dgraph.
Dgraph is built to provide low-latency, high throughput query execution even with arbitrary depth joins and large fan-outs over massive datasets. And instead of being a hastily put custom solution on top of SQL, Dgraph is designed from scratch to execute well on both graph style joins and traversals, and SQL style selects.
Dgraph solves all five problems listed above. It provides horizontal scalability, performance, index consistency, transactional guarantees, correctness and synchronous replication: all the things which a database must have to allow applications to predict database behavior and simplify logic. We have spent years of effort into ensuring that it would NOT lose data or break transactional guarantees under varied edge cases and would continue to function despite experiencing network partitions, disk failures, and machine failures. In fact, Dgraph is the only graph database to have been Jepsen tested (and passes them in all recent releases).
Most other graph databases or layers are built as sidekicks. There’s a primary DB which stores the data and then there’s a graph system which gives the ability to run some specific operations.
That was never the vision for Dgraph.
While the graph market itself is slated to grow 100% each year and enough to generate profits for any vendor, we always designed Dgraph to be a general purpose database with a graph backend. In essence, it is designed to hold the source of truth and it is being used to do so by both our open source and paid users, including Fortune 500 companies.
The power of Dgraph lies in both providing a flexible schema and the ability to run complex queries fast effortlessly. We couldn’t have expressed these benefits when compared to other DBs better than one of the Dgraph users building a sport social media platform:
In our experience of using NoSQL databases such as MongoDB, we enjoyed the ability to just insert data and immediately make queries to the database without the need to define quite a rigid schema, though in the long run, as our applications get complex, the toll was the inability to make complex queries with the frequent need of multiple joins. The case against a SQL database was the database management and administration of schemas gets cumbersome, especially for a small team without dedicated DBAs. We frequently encounter problems between syncing schemas between different environments, e.g: SIT, UAT, PROD. Another big issue regarding SQL databases is horizontal scaling. Open sources databases we have experience in such as PostgreSQL, does not have a builtin/native support for horizontal scaling methods such as sharding (though there are third-party extensions that add sharding capability like Citus). These are issues that Dgraph is proactively solving.
Dgraph provides a great solution for graph problems and an even better solution for apps. Most data models have relationships which need to be taken into account to execute queries and Dgraph can simplify data models quite significantly while improving query performance.
The most common use case that Dgraph is solving is to unify multiple data silos stuck in traditional databases or across different backends, into one Dgraph powered platform. This allows much more powerful queries across different datasets without compromising on performance, allowing users to build smarter apps and do real-time analytics.
Companies are learning that users don’t want references, they want answers. Having a high-quality knowledge graph allows them to serve their users better. Many companies are in the process of building a knowledge graph and are using Dgraph to serve that.
Software is eating the world and social is eating the apps. Today’s apps are built keeping social interactions in mind, where relationships are as important as data itself. Dgraph is being run as a primary database for many social apps.
In addition, graph use cases like referral and recommendation, real-time fraud detection, customer 360, etc. are being run on Dgraph as well (see blog post). Something that we didn’t forsee is the application of Dgraph for tracking Kubernetes resources. Both VMware and Intuit have open source projects managing K8s resources via Dgraph.
We ourselves have applied Dgraph as a general purpose database to serve data typically associated with traditional ones. Couple of years ago, we showcased running Stack Overflow on Dgraph and we were amazed by how much effort we saved by simplifying the data model, avoiding data denormalization, and retrieving a whole page worth of data in a single call to the DB. We cut the backend code significantly, spending most of the effort on the rendering of the results than on generating the content in the backend.
Earlier this year, we wrote Flock to live stream Tweets into Dgraph, to showcase how effortless it is to load JSON data and gain the ability to run complex queries.
It is hard to measure open source traction. But, there’s a common proxy that open source projects use: GitHub activity, in particular something objective like GitHub stars. But looking at an absolute number of GitHub stars for projects started in different years can be somewhat misleading. An older project would have more chance to gain a following than a younger project and therefore would always appear to have more stars.
Instead, we chose to plot the rate of growth. We wrote some scripts to download the GitHub star history and plotted GitHub stars by weeks since project inception. That is, after week N, what was the star count for different projects (50 weeks representing approximately an year). This allows us to compare their star power when the projects were of same age. You can see the graphs here.
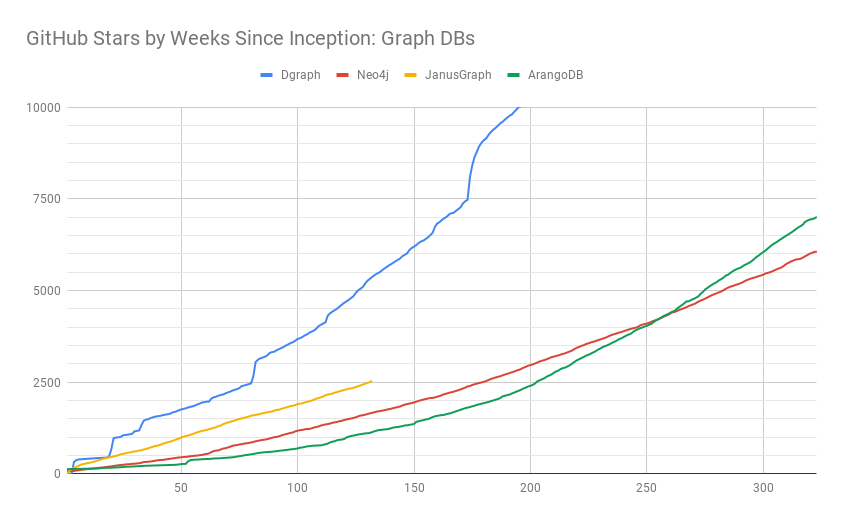
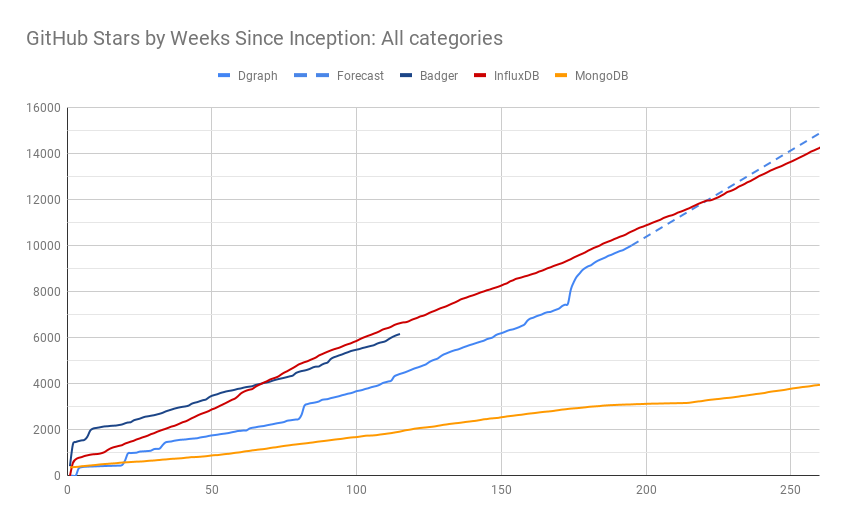
Here, the x-axis represents the number of weeks since project was first made public on GitHub. And the y-axis is the star count as of that week1.
Compared against Neo4j, JanusGraph and ArangoDB, Dgraph is the fastest growing and one of the most popular open source graph databases. And it performs well when put side-by-side with the most popular databases in other categories, including InfluxDB and MongoDB.
In addition, Dgraph’s own basic telemetry shows thousands of daily-active instances running in the wild, together serving terabytes of data.
This is one of the bets we took very early on in Dgraph’s journey. When looking for a query language for the database back in 2015, we weren’t happy with the existing choices of Cypher and Gremlin. Incidentally, Facebook’s GraphQL draft spec had just been publicly released in July 2015. We really liked it.
So, back in 2015, we bet upon GraphQL being the primary lingua franca for Dgraph. Over time, we had to make many modifications to make it work like a query language for a database, causing it to become incompatible with the official spec. We called it GraphQL+-.
While the idea was just to provide a simpler query language while allowing returning subgraphs as result instead of just lists, over the last 3 years GraphQL+- has become one of the most liked features of Dgraph. At the same time, GraphQL itself has taken the world by storm, with many companies replacing their REST APIs with GraphQL.
We envision Dgraph can play a lot bigger role in the next generation of mobile and web apps being built on top of GraphQL. Dgraph is special considering it is the only (or one of the rare) database to be built around GraphQL. As such, it can completely execute a GraphQL query within a single network call, while most other “GraphQL layer on DB” frameworks require making multiple round-trips between the GraphQL layer and the underlying database (not unlike what graph layers have to do). The former can provide much better performance and scalability than the latter.

One word, Hire.
“We shall hire on the beaches, we shall hire on the grounds, we shall hire in the fields and in the streets, we shall hire in the hills.” – As heard on the radio.
With only $3M in funding since inception in early 2016, Dgraph has been understaffed for the longest time. With this raise, we plan to expand our engineering team significantly, both in our headquarters in San Francisco and our remote office in Bengaluru, India. See our small tightly-knit existing team and our openings here.
The expanded team will allow us to respond much quicker to user feedback, which is sometimes overwhelming. It will also allow us to build both open source and enterprise features at a much faster pace. Finally, Dgraph as a service has been one of the most asked for requests — this will give us a chance to consider that effort seriously.
Dgraph is in a unique position where it can apply the power of graphs on both complex and seemingly mundane problems, while providing a good alternative solution to hammering every problem with SQL. That was the vision with which we raised 11.5 million dollars.
If you are curious about what our pitch deck to investors looked like, we have decided to open source it. The deck has some sensitive slides removed, but largely is the same as seen by investors. You can see it here (link).
Congrats for making it to the end of our moonshot pitch. Enjoy! And Keep Building Smart Apps. — Manish & the Dgraph Labs Team
For other perspectives on the funding announcement, see:
Note that the x-axis gets cutoff on the right, so it won’t reflect the full life of an old project. ↩︎
