
Dgraph’s next release v21.12, codenamed Zion, has been a very special release for many reasons — some of which might not be obvious right now.
Part of what makes this release special is the introduction of Roaring Bitmaps. It has been a pending task for a long time to improve Dgraph’s posting list structures. For context, Dgraph assigns a unique 64-bit unsigned integer to every node in the graph. These nodes are kept grouped in a sorted list, known as posting list — a term typically used by search engines.
Since its inception, Dgraph has been using group varint encoding for storage 1 and just plain Go lists of integers via protocol buffers for transportation. This conversion from a compressed structure to an uncompressed structure isn’t efficient. Moreover, uncompressed plain integer lists consume a lot of space (8 bytes per integer) and are expensive to keep in RAM or ship over the network.
Group Varint is a popular encoding mechanism, still in production at various big companies. But, Roaring Bitmaps have been making waves. It is being used by Google Procella, Apache Lucene including Elastic Search, Netflix Atlas, and many more. We at Dgraph have also been impressed by its simplicity and efficiency. As mentioned in Dgraph Paper, it has been on the cards to try to switch to roaring bitmaps, but posting list structures are integrated so deep into Dgraph’s storage, communication, and query processing that previous attempts hit various roadblocks despite months of work.
This time around, we were able to push through the various challenges and achieve our goal of integrating Roaring Bitmaps (henceforth, RB). At the same time, we realized that the official RB Go library had a few shortcomings related to memory usage, which negatively affected our integration significantly. So, we went down the path of rewriting the Go library to be more memory efficient.
In this blog post, I explain our motivation for the rewrite, the techniques we used and the impressive results we were able to achieve with this new library called sroar – Serialized Roaring Bitmaps.
The main requirement for roaring bitmaps was that the on-disk representation and the in-memory representation should be the same. This way, a posting list can be operated upon or shipped over the network by just reading from disk and doing a memory copy. Moreover, all the set, remove, clone, union, and intersection operations then wouldn’t require expensive encoding/decoding step.
That wasn’t the case with the Go implementation of roaring bitmaps, RoaringBitmaps/Roaring. The on-disk format and the in-memory format were different. The on-disk format couldn’t do any operations and had to be converted to the in-memory format, which required an expensive decoding step.
Moreover, the in-memory format allocated memory on heap for every container in the bitmap, which led to much higher memory consumption and lots of allocations, hence increasing the work for the Go garbage collector.
As detailed in our blog post manual memory management in Go, we replaced Go memory with jemalloc in all critical paths to remove the consistent OOM errors we were getting, because the Go garbage collector was unable to keep up with the pace of memory allocations and deallocations. We don’t expect this to be the case for typical Go systems. But with a high-performance database system, this became a very big issue for us. So, we replaced all smaller allocations on the heap with bigger byte slice allocations via jemalloc.
This learning when applied to RBs was to avoid allocating memory for containers separately. Instead, the idea was to lay the entire RB out onto one bigger byte slice, hence converting memory allocations from O(N) to O(1), where N = number of containers in the RB.
We looked at how we could modify the available Go implementation to achieve this but didn’t see a good simple way to achieve that. This layout would impact everything from how containers are created, accessed, grown, shrunk, and removed. So, we decided it was best to write an implementation of roaring bitmaps from scratch. The goal for this rewrite was to ensure that the in-memory representation and the on-disk representation is the same, with all data lying on a single byte slice, avoiding any encoding/decoding steps.
Per GitHub, this library is being used by many other Go projects like InfluxDB, SourceGraph, Bleve, and others. Seeing its importance not just for us at Dgraph, but across the wider Go community, we saw there was a major room for improvement 2 and felt the effort was worth investing in.
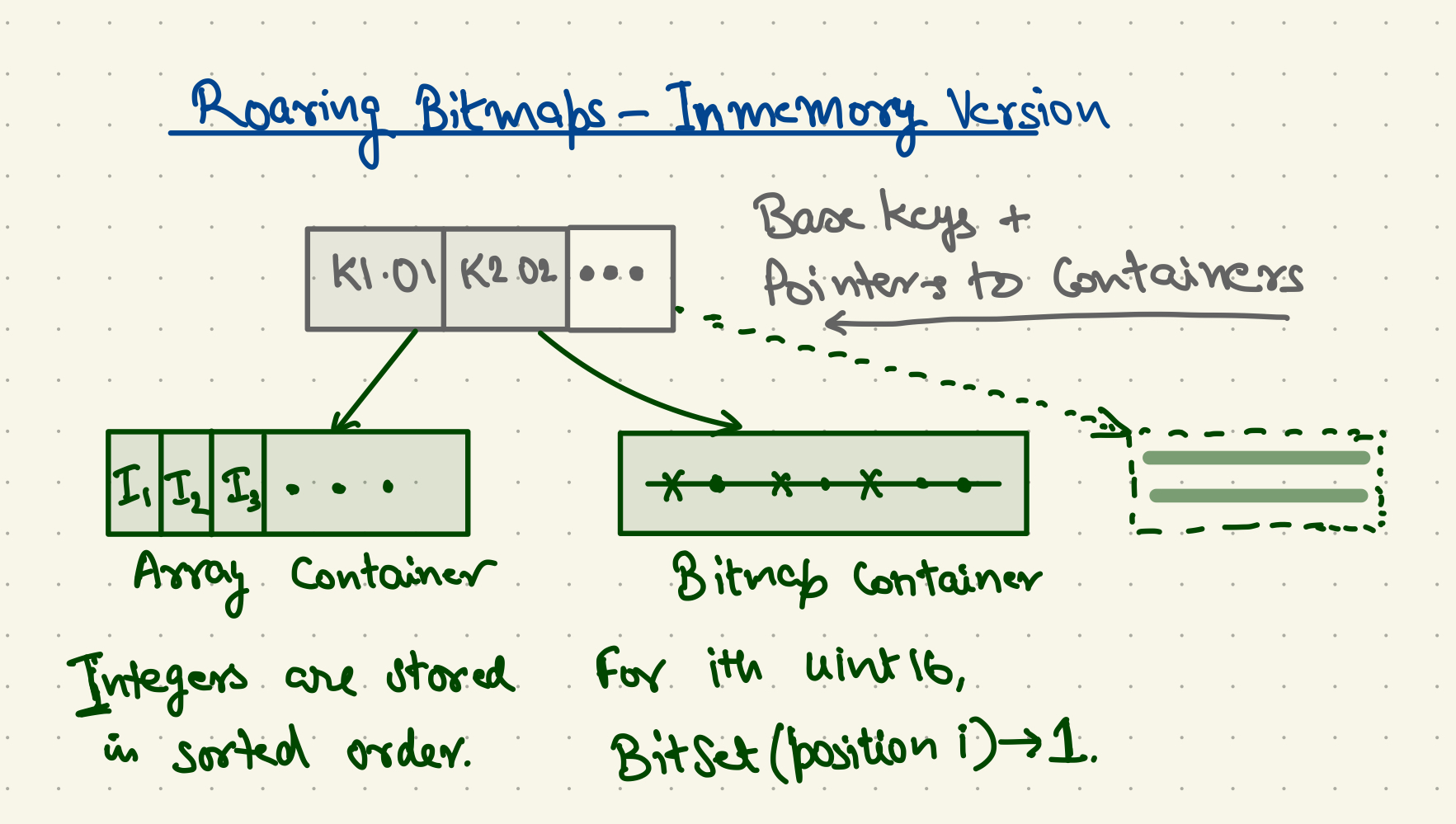
Let’s look at how Roaring Bitmaps work. They use two kinds of containers — arrays and bitmaps. To give a quick primer about roaring bitmap containers, each container stores all the integers having a common 48-bit base key (mask of 0xFFFFFFFFFFFF0000), with the lower 16-bits being represented as uint16s (mask of 0xFFFF).
An array container just stores lists of uint16s. Each integer takes 2-bytes (16 bits). Array containers are of variable length and can start as small as holding just one uint16. When an array container grows to 4096 uint16s, its size hits 8 kB. At that point, it makes sense to convert it to a bitmap container instead. A bitmap container uses 1 bit each to represent each uint16 integer. To store all 2^16 integers thus takes a maximum space of 2^16 bits / 8 bits per byte = 8 kB.
In the original implementation of roaring bitmaps, each container allocates its memory on the heap. Thus, each RB does O(N) allocations on the heap, where N = number of containers. When RB is growing, the array containers are growing, hence leading to more memory re-allocations and more work for the Go GC. Not only that – cloning, encoding, or decoding these to move from in-memory to on-wire or on-disk is an expensive step consuming CPU cycles.
So we built sroar — Serialized Roaring Bitmaps. Sroar operates on 64-bit integers and uses a single byte slice to store all the keys and containers. This byte slice can then be stored on disk, operated on directly in memory, or transmitted over the wire. There’s no encoding/decoding step required. For all practical purposes, sroar can be treated just like a byte slice.
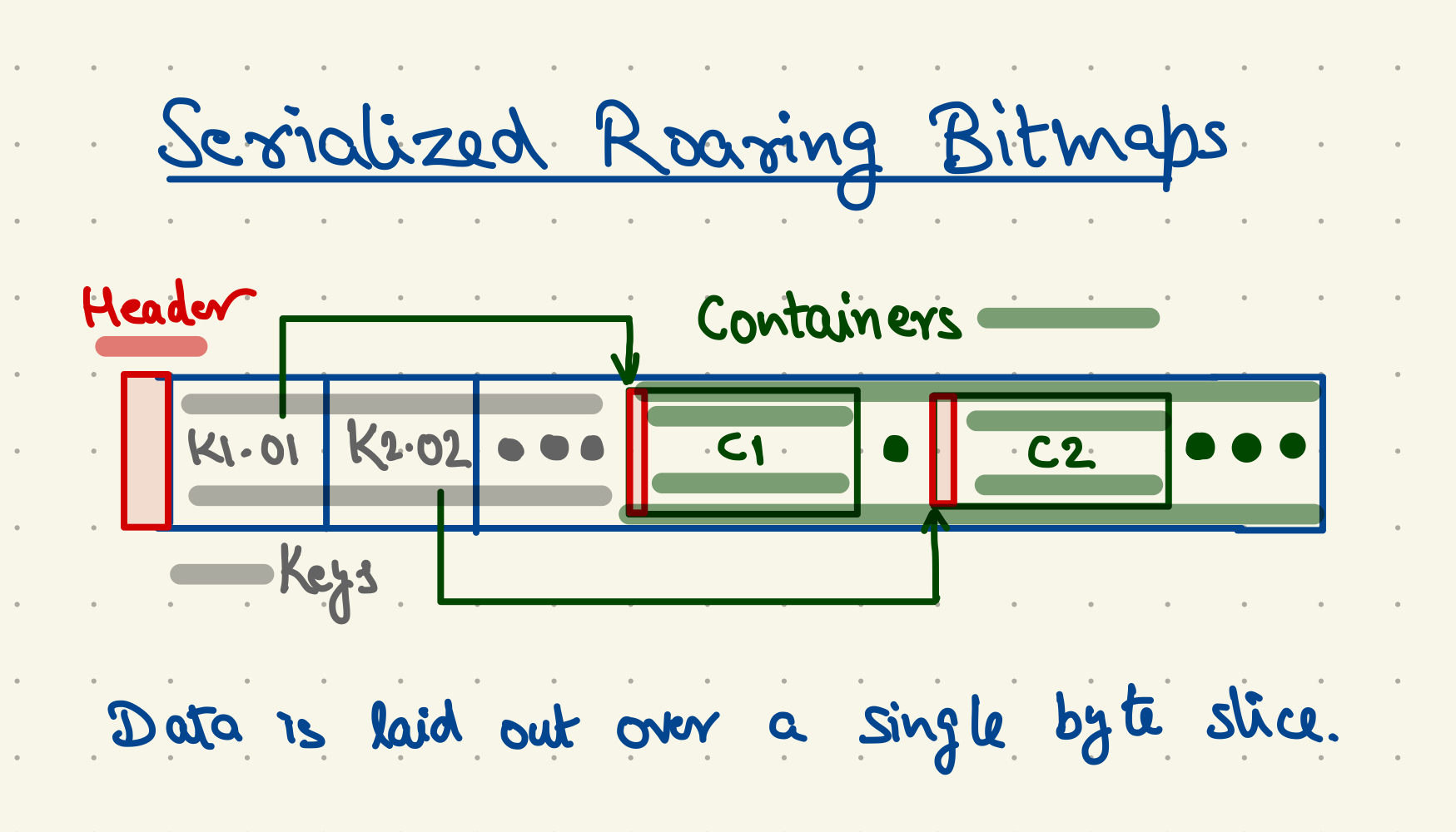
With sroar, we changed how RB is generated and laid out. Sroar allocates one long byte array — actually using a uint16 slice in Go. It uses the first portion of the array to store the base keys and the offset for their corresponding containers. The base keys are all kept sorted for faster search, but the containers can be located anywhere in the array.
Each container starts with a header that stores its size, type of the container (array or bitmap), and its cardinality. Size and type each take 1 uint16. The maximum cardinality of a container can be 2^16, so it needs 2 uint16s. Thus the header is 4 uint16s (or 8 bytes) long.
The logic for storing uint16s in these containers is typical of the structure. The array container keeps the uint16s sorted, while the bitmap container uses bits to mark whether the uint16 is present or absent.
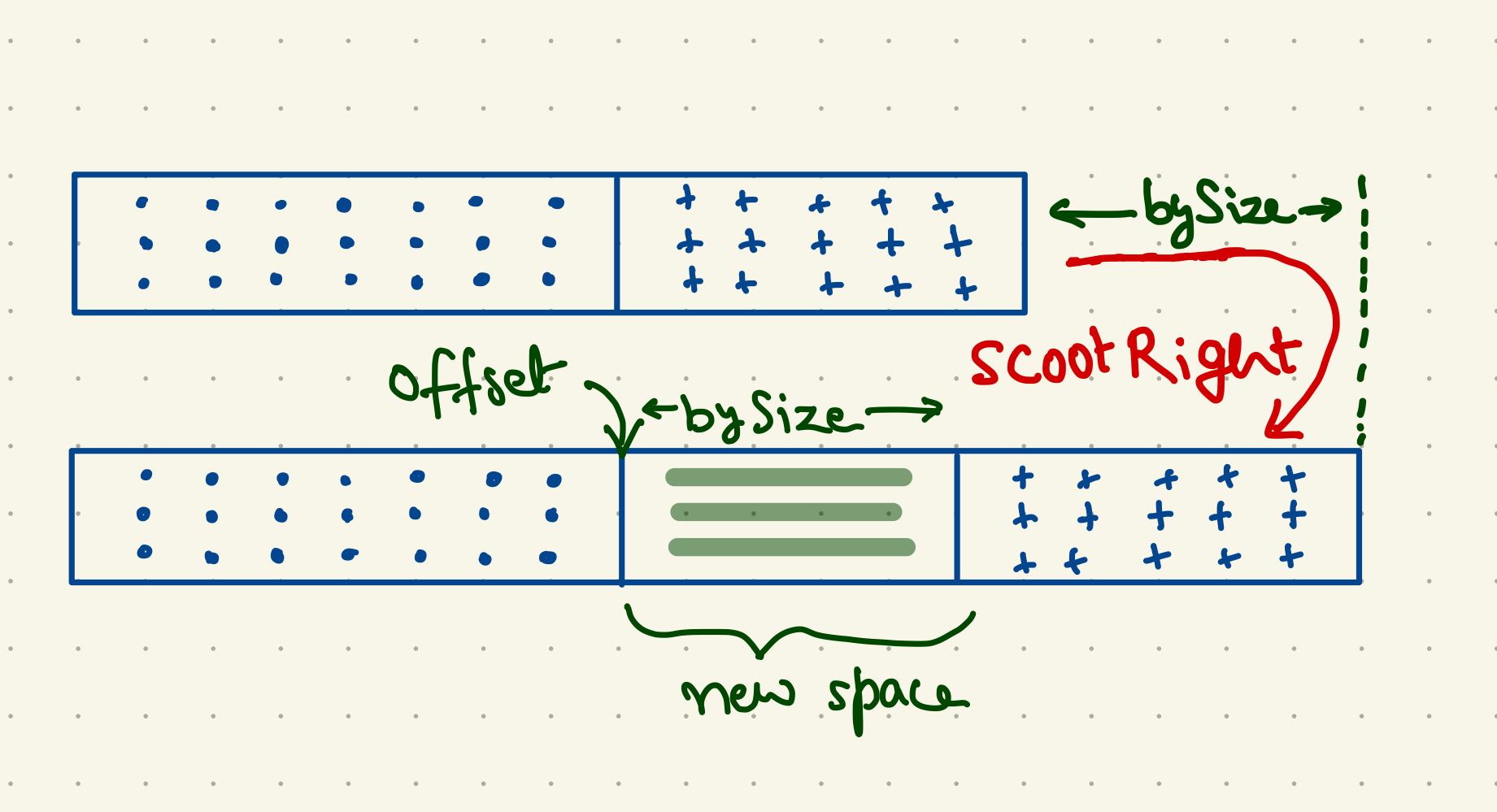
What’s more interesting is how these containers grow and shrink. To make the
size changes happen, we added two functions, scootRight and scootLeft. These
functions take an offset and a bySize and can move the contents of the data
slice left or right accordingly. They also clear out the internal space created
at the offset by using runtime.memclrNoHeapPointers. Note that the underlying
data slice might have to be grown as well to make space. These moves can get
expensive, Sroar keeps track of how many bytes of movements have happened as
efficiency metrics, which we used to improve our implementation.
Sroar has been optimized for the various intersection and union operations
expected from RBs. A lot of this optimization hinges on avoiding scoots and
getting the keys and containers laid out upfront. Let’s look at FastOr, which is
a union of an arbitrary number of Sroars.
To make this operation efficient, all the base keys from all source Sroars are first accumulated along with their cardinalities. Cardinalities per container are then just summed up assuming the worst case with no integer overlap.
If the cardinality is below 4096 integers, an array container is created upfront. For anything above, a bitmap container is created upfront. This way, the output SRB gets its memory allocated upfront – avoiding the need to scoot memory later. And then, this SRB is ORed with each of the source SRBs in a loop.
To optimize this further, the cardinalities are not calculated during the union. Instead, they are calculated once all the unions are done. This improves performance significantly.
Intersections tend to be much cheaper than unions. For intersections, Sroar iterates over the Bitmaps container by container, intersects them, and if the resulting container has any elements remaining, adds the container to the destination Bitmap. This is a relatively straightforward approach and has worked really well in our tests so far.
To benchmark Sroar, we ran benchmarks
FastOr, which is a more expensive operation than And or
equivalent (BenchmarkRealDataFastOr).Based on the benchmarks, Sroar consumes 15x less memory and does 25x fewer memory allocations. And it achieves this, while also being 7x faster! See results here.
These results were impressive on their own. But, we saw even better performance results when integrated with Dgraph.
We ran Dgraph v21.12 (Zion) which has sroar (with posting list cache turned off) on the heaviest Dgraph Cloud user workload. We sampled the queries which used to take >100ms with v21.03. With 32 concurrent requests against v21.03, we saw massive improvements.
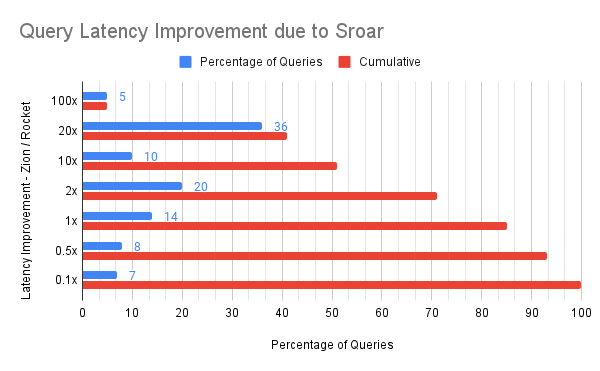
Over 40% of the queries were at least 20x faster, while over 50% of the queries were at least 10x faster. This showed that Dgraph Zion release performs exceptionally well under heavier workloads.
Another benchmark for lighter workloads with only a single pending request saw that over 50% of the queries were at least 2x faster.
Moreover, Dgraph with Sroar uses 10x less memory. In heavy load scenarios, where Dgraph was previously using over 50 GBs of memory, Dgraph with Sroar used under 5 GB.
So, not only is Zion release 10x faster, but also 10x more memory efficient than Rocket. These are incredibly delightful results, all thanks to Sroar!
Serialized Roaring Bitmaps is a ground-up rewrite of Go Roaring Bitmaps, which results in a factor faster operations, lower memory usage, and fewer memory allocations than existing Go implementation. Furthermore, Sroar shows even better performance and memory benefits when used within Dgraph. We think any user of Sroar should see improvements compared to the official library.
Sroar is available under Apache v2.0 license. Do try it out in your project and let us know your experiences! Sroar is being used in Dgraph release v21.12, codenamed Zion.
Special thanks to Ahsan Barkati for his amazing work on Sroar.
To quickly summarize group varint encoding, the list of integers gets divided up into fixed-sized blocks of say 128 integers. The first integer is stored whole, and the rest are stored as diffs. Because the diffs are smaller integers, using a var encoding reduces their space consumption. ↩︎
Note that all of our experimentation and analysis is centered around the 64-bit version of roaring bitmaps. As mentioned, Dgraph uses 64-bit unsigned integers for storing nodes in the graph. We have not done any benchmarks against the 32-bit version. ↩︎

