
Designing GraphQL schemas
This post made it to top 10 on HackerNews front page. Do engage in discussion there and show us love by g ...
Learn more

This post made it to #3 on HackerNews front page. Do engage in discussion there and show us love by giving us a GitHub star.
When I introduce myself and explain what we are building at Dgraph Labs, I am typically asked if I worked at Facebook, or if what I’m building is inspired by Facebook. A lot of people know about the efforts at Facebook to serve their social graph, because they have published multiple articles about the graph infrastructure they put together.
Word from Google has been limited to serving Knowledge Graph, but nothing has been said about the internal infrastructure which makes this happen. There are specialized systems in place at Google to serve the knowledge graph. In fact, we (at Google) placed big bets on graph serving system. I myself put at least two promotions at stake to go work on the new graph thing back in 2010, and see what we could build.
Google needed to build a graph serving system to serve not just the complex relationships in the Knowledge Graph data, but also all the OneBoxes which had access to structured data. The serving system needed to traverse facts, with high enough throughput and low enough latency to be hit by a good chunk of web search queries. No available system or database was able to do all three.
Now that I’ve answered the why, I’ll take the rest of the blog post to walk you through my journey, intertwined with Google’s, of building the graph system to serve the Knowledge Graph and OneBoxes.
I’ll quickly introduce myself. I worked at Google from 2006 to 2013. First as an intern, then as a software engineer in Web Search Infrastructure. In 2010, Google acquired Metaweb and my team had just launched Caffeine. I wanted to do something different and started working with Metaweb folks (in SF), splitting my time between San Francisco and Mountain View. My aim was to figure out how we could use the knowledge graph to improve web search.
There were projects at Google which predate my entrance into graphs. Notably, a project called Squared was built out of the NY office, and there was some talk of Knowledge Cards. These were sporadic efforts by individuals/small teams, but at this time there was no established chain of command in place, something that would eventually cause me to leave Google. But we’ll get to that later.
As mentioned before, Google acquired Metaweb in 2010. Metaweb had built a high-quality knowledge graph using multiple techniques, including crawling and parsing Wikipedia, and using a Wikipedia-like crowd-sourced curation run via Freebase. All of this was powered by a graph database they had built in-house called Graphd – a graph daemon (now published on GitHub).
Graphd had some pretty typical properties. Like a daemon, it ran on a single server and all the data was in memory. The entire Freebase website was being run out of Graphd. After the acquisition, one of the challenges Google had was to continue to run Freebase.
Google has built an empire on commodity hardware and distributed software. A single server database could have never housed the crawling, indexing and serving for Search. Google built SSTable and then Bigtable, which could scale horizontally to hundreds or thousands of machines, working together to serve petabytes of data. Machines were allocated using Borg (K8s came out of that experience), communicated using Stubby (gRPC came out of that), resolved IP addresses via Borg name service (BNS, baked into K8s), and housed their data on Google File System (GFS, think Hadoop FS). Processes can die and machines can crash, but the system just keeps humming.
That was the environment in which Graphd found itself. The idea of a database serving an entire website running on a single server was alien to Google (myself included). In particular, Graphd needed 64GB or more memory just to function. If you are sneering at the memory requirement, note that this was back in 2010. Most Google servers were maxed at 32GB. In fact, Google had to procure special machines with enough RAM to serve Graphd as it stood.
Ideas were thrown around about how Graphd could be moved or rewritten to work in a distributed way. But see, graphs are hard. They are not key-value databases, where one can just take a chunk of data, move it to another server and when asked for the key, serve it. Graphs promise efficient joins and traversals, which require software to be built in a particular way.
One of the ideas was to use a project called MindMeld (IIRC). The promise was that memory from another server could be accessed much faster via network hardware. This was supposedly faster than doing normal RPCs, fast enough to pseudo-replicate direct memory accesses required by an in-memory database. That idea didn’t go very far.
Another idea, which actually became a project, was to build a truly distributed graph serving system. Something which can not only replace Graphd for Freebase but also serve all knowledge efforts in the future. This was named, Dgraph – distributed graph, a spin on Graphd – graph daemon.
If you are now wondering, the answer is yes. Dgraph Labs, the company and Dgraph, the open source project are named after this project at Google1.
For the majority of this blog post, when I refer to Dgraph, I am referring to the project internal to Google, not the open source project that we built. But more on that later.
Inadvertently building a graph serving system.
While I was generally aware of the Dgraph effort to replace Graphd, my goal was to build something to improve web search. I came across a research engineer, DH, at Metaweb, who had built Cubed.
As I mentioned before, a ragtag of engineers at Google NY had built Google Squared. So, doing a one up, DH built Cubed. While Squared was a dud, Cubed was very impressive. I started thinking about how I could build that at Google. Google had bits and pieces of the puzzle that I could readily use.
The first piece of the puzzle was a search project which provided a way to understand which words
belonged together with a high degree of accuracy. For example, when you see a phrase like [tom hanks movies], it can tell you that [tom] and [hanks] belong together. Similarly, from [san francisco weather], [san] and [francisco] belong together. These are obvious things for humans,
not so obvious to machines.
The second piece of the puzzle was to understand grammar. When a query asks for [books by french authors], a machine could interpret it as [books] by [french authors] (i.e. books by those
authors who are French). But it could also interpret it as [french books] by [authors] (i.e.
French language books by any author). I used a Part-Of-Speech (POS) tagger by Stanford to
understand grammar better and build a tree.
The third piece of the puzzle was to understand entities. [french] can mean many things. It could be
the country (the region), the nationality (referring to French people), the cuisine (referring to
the food), or the language. There was another project I could use to get a list of entities that the
word or phrase could correspond to.
The fourth piece of the puzzle was to understand the relationship between entities. Now that I knew
how to associate the words into phrases, the order in which phrases should be executed, i.e. their
grammar, and what entities they could correspond to, I needed a way to find relationships between
these entities to create machine interpretations. For example, a query says [books by french authors] and POS tells us it is [books] by [french authors]. We have a few entities for
[french] and few for [authors], and the algorithm needs to determine how they are connected.
They could be connected by birth, i.e. authors who were born in France (but could be writing in
English), or authors who are French nationals, or authors who speak or write French (but could be
unrelated to France, the country), or authors who just enjoy French food.
To determine if and how the entities are connected, I needed a graph system. Graphd was never going
to scale to Google levels, and I understood web search. Knowledge Graph data was formatted in
Triples, i.e. every fact was represented by three pieces, subject (entity), predicate
(relationship), and object (another entity). Queries had to go from [S P] → [O], from [P O] → [S], and sometimes from [S O] → [P].
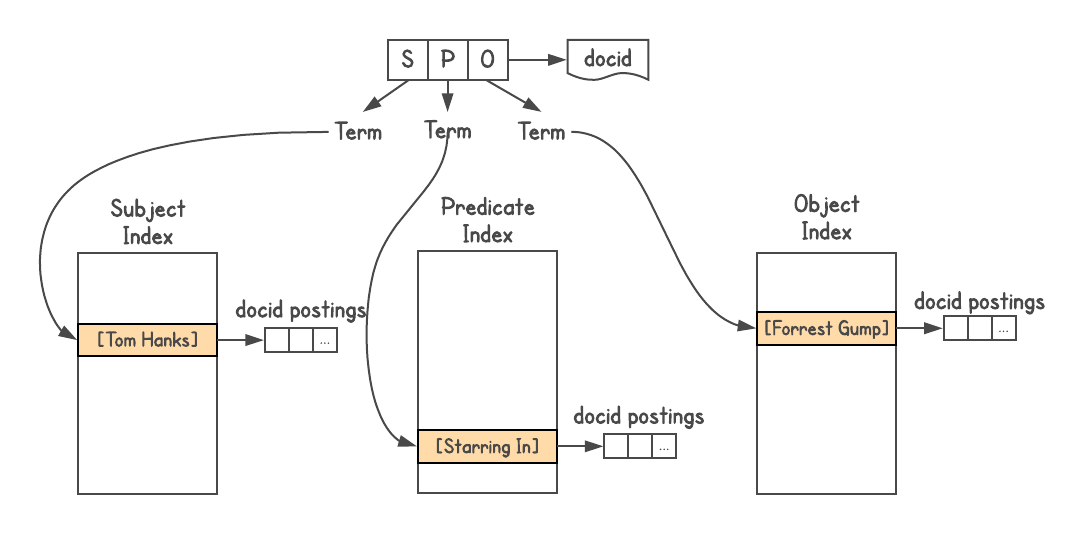
I used Google’s search index system, assigned a docid to each triple and built three indices, one each for S, P and O. In addition, the index allowed attachments, so I attached the type information about each entity (i.e. actor, book, person, etc).
I built this graph serving system, with the knowledge that it had the join depth problem (explained below) and was unsuited for any complex graph queries. In fact, when someone from the Metaweb team asked me to make it generally accessible to other teams, I flat-out rejected the idea.
Now to determine relationships, I’d do queries to see how many results each yielded. Does [french]
and [author] yield any results? Pick those results and see how they are connected to [books],
and so on. This resulted in multiple machine interpretations of the query. For example, when you
run [tom hanks movies], it would produce interpretations like [movies directed by tom hanks],
[movies starring tom hanks], [movies produced by tom hanks], and automatically reject
interpretations like [movies named tom hanks].
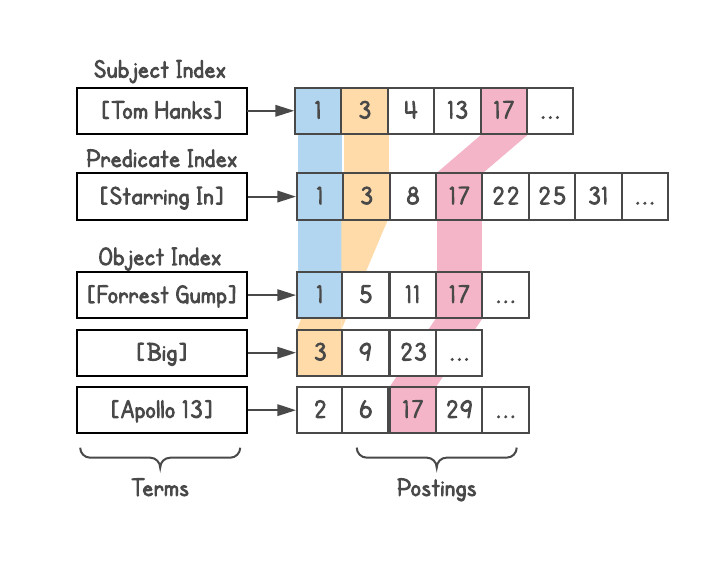
With each interpretation, it would generate a list of results – valid entities in the graph – and it would also return their types (present in attachments). This was extremely powerful because understanding the type of the results allowed capabilities like filtering, sorting or further expansion. For movie results, you could sort the movies by year of release, length of the movie (short, long), language, awards won, etc.
This project seemed so smart, that we (DH was loosely involved as the knowledge graph expert) named it Cerebro, after the device of the same name appearing in X-Men.
Cerebro would often reveal very interesting facts that one didn’t originally search for. When
you’d run a query like [us presidents], Cerebro would understand that presidents are humans, and
humans have height. Therefore, it would allow you to sort presidents by height and show that
Abraham Lincoln is the tallest US president. It would also let people be filtered by nationality.
In this case, it showed America and Britain in the list, because US had one British president,
namely George Washington. (Disclaimer: Results based on the state of KG at the time; can’t vouch
for the correctness of these results.)
Cerebro had a chance to truly understand user queries. Provided we had data in the graph, we could
generate machine interpretations of the query, generate the list of results and know a lot about the
results to support further exploration. As explained above, once you understand you’re dealing with
movies or humans or books, etc., you can enable specific filtering and sorting abilities. You could
also do edge traversals to show connected data, going from [us presidents] to [schools they went to], or [children they fathered]. This ability to jump from one list of results to another was
demonstrated by DH in another project he’d built called Parallax.
Cerebro was very impressive2 and the leadership at Metaweb was supportive of it. Even the graph serving part of it was performant and functional. I referred to it as a Knowledge Engine (an upgrade from search engine). But there was no leadership for knowledge in place at Google. My manager had little interest in it, and after being told to talk to this person and that, I got a chance to show it to a very senior leader in search.
The response was not what I was hoping for. For the demo of [books by french authors], the
senior search leader showed me Google search results for the query, which showed ten blue links, and
asserted that Google can do the same thing. Also, they do not want to take traffic away from
websites, because then the owners would be pissed.
If you are thinking he was right, consider this: When Google does a web search, it does not truly understand the query. It looks for the right keywords, at the right relative position, the rank of the page, and so on. It is a very complex and extremely sophisticated system, but it does not truly understand either the query or the results. It is up to the user to read, parse, and extract the pieces of information they need from the results, and make further searches to put the full list of results together.
For example, for [books by french authors], first one needs to put together an exhaustive list
which might not be available in a single web page. Then sort these books by year of publication, or
filter by publication houses, etc. — all those would require a lot of link following, further
searches, and human aggregation of results. Cerebro had the power to cut down on all that effort and
make the user interaction simple and flawless.
However, this was the typical approach towards knowledge back then. Management wasn’t sure of the utility of the knowledge graph, or how and in what capacity that should be involved with search. This new way of approaching knowledge was not easily digestible by an organization that had been so massively successful by providing users with links to web pages.
After butting heads with the management for a year, I eventually lost interest in continuing. A manager from the Google Shanghai office reached out to me, and I handed the project over to him in June 2011. He put a team of 15 engineers on the project. I spent a week in Shanghai transferring whatever I had built and learned to the engineers. DH was involved as well and he guided the team for the long term.
The graph serving system I had built for Cerebro had a join-depth problem. A join is executed when
the result set from an earlier portion of the query is needed to execute a later portion of it. A
typical join would involve some SELECT, i.e. a filter in certain results from the universal data
set, then using these results to filter against another portion of the dataset. I’ll illustrate with
an example.
Say, you want to know [people in SF who eat sushi]. Data is sharded by people, and has information
about who lives in which city and what food they eat.
The above query is a single-level join. If an application external to a database was executing this, it would do one query to execute the first step. Then execute multiple queries (one query for each result), to figure out what each person eats, picking only those who eat sushi.
The second step suffers from a fan-out problem. If the first step has a million results (population of San Francisco), then the second step would need to put each result into a query, retrieving their eating habit, followed by a filter.
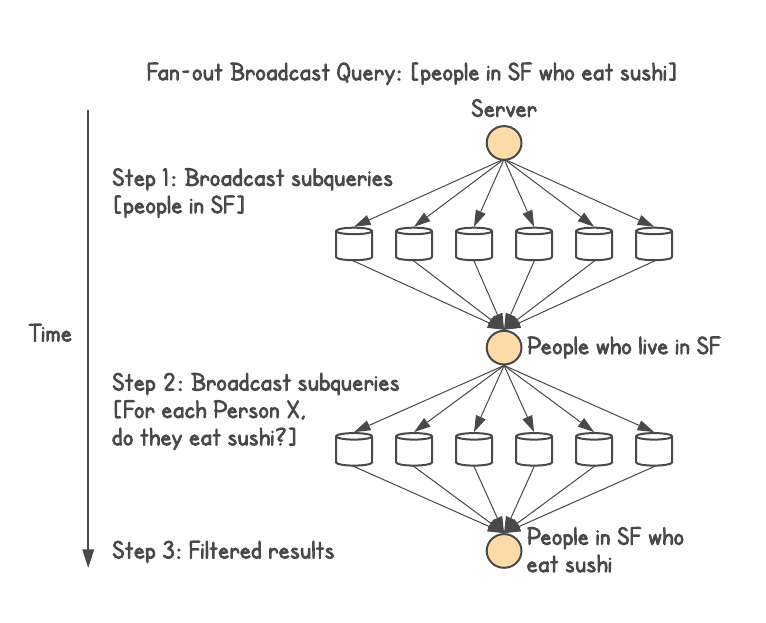
Distributed system engineers typically solve this by doing a broadcast. They would batch up the results, corresponding to their sharding function, and make a query to each server in the cluster. This would give them a join, but cause query latency issues.
Broadcasts in a distributed system are bad. This issue is best explained by Jeff Dean of Google in his “Achieving Rapid Response Times in Large Online Services” talk (video, slides). The overall latency of a query is always greater than the latency of the slowest component. Small blips on individual machines cause delays, and touching more machines per query increases the likelihood of delays dramatically.
Consider a server with 50th-%ile latency of 1ms, but 99th-%ile latency of 1s. If a query only touches one server, only 1% of requests take over a second. But if the query touches 100 of these servers, 63% of requests would take over a second.
Thus, broadcasts to execute one query are bad for query latency. Now consider if two, three or more joins need to happen. They would get too slow for real-time (OLTP) execution.
This high fan-out broadcast problem is shared by most non-native graph databases, including Janus graph, Twitter’s FlockDB, and Facebook’s TAO.
Distributed joins are a hard problem. Existing native graph databases avoid this problem by keeping the universal dataset within one machine (standalone DB), and doing all the joins without touching other servers, e.g. Neo4j.
After wrapping up Cerebro, and having experience building a graph serving system, I got involved with the Dgraph project, becoming one of the three tech leads on the project. The concepts involved in Dgraph design were novel and solved the join-depth problem.
In particular, Dgraph sharded the graph data in a way where each join can be executed entirely by
one machine. Going back to subject-predicate-object (SPO), each instance of Dgraph would hold all
the subjects and objects corresponding to each predicate in that instance. Multiple predicates would
be stored on the instance, each predicate being stored in its entirety.
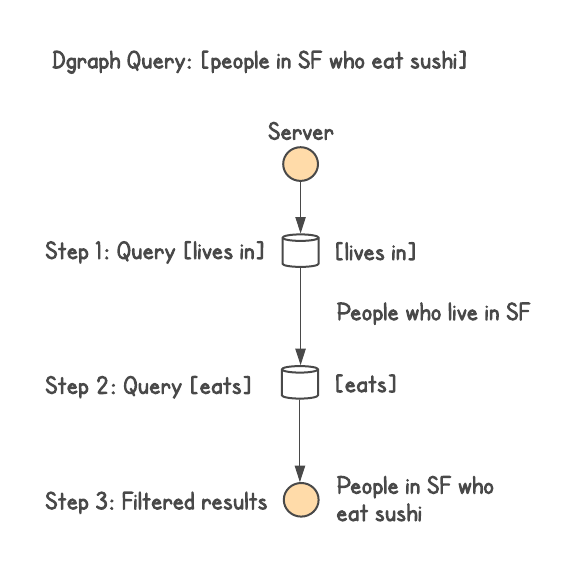
This allowed the queries to execute arbitrary depth joins while avoiding the fan-out broadcast
problem. Taking the query [people in SF who eat sushi], this would result in at most two network
calls within the database irrespective of the size of the cluster. The first call would find all
people who live in SF. The second call would send this list of people and intersect with all the
people who eat sushi. We can then add more constraints or expansions, each step would still involve
at most one more network call.
This introduces the problem of very large predicates located on a single server, but that can be solved by further splitting up a predicate among two or more instances as the size grows. Even then, a single predicate split across the entire cluster would be the worst-case behavior in only the most extreme cases where all the data corresponds to just one predicate. In the rest of the cases, the design of sharding data by predicates works better to achieve much faster query latency in real-world systems.
Sharding was not the only innovation in Dgraph. All objects were assigned integer IDs and were
sorted and stored in a posting list structure to allow for quick intersections of posting lists.
This would allow fast filtering during joins, finding common references, etc. Ideas from Google’s
web serving system were involved.
Dgraph at Google was not a database. It was a serving system, the equivalent of Google’s web search serving system. In addition, it was meant to react to live updates. As a real-time updating serving system, it needed a real-time graph indexing system. I had a lot of experience with real-time incremental indexing systems having worked on Caffeine.
I started a project to unite all Google OneBoxes under this graph indexing system, which involved weather, flights, events, and so on. You might not know the term, but you definitely have seen them. OneBox is a separate display box which gets shown when certain types of queries are run, where Google can return richer information. To see one in action, try [weather in sf].
Before this project, each OneBox was being run by standalone backends and maintained by different teams. There was a rich set of structured data, but no data was being shared between the boxes. Not only was maintaining all these backends a lot of work operationally but also the lack of knowledge share limited the kind of queries Google could respond to.
For example, [events in SF] can show the events, and [weather in SF] can show the weather. But if
[events in SF] could understand that the weather is rainy and know whether events are indoors or
outdoors, it can filter (or at least sort) the events based on weather (in a heavy rainstorm, maybe a
movie or a symphony is the best option).
Along with help from the Metaweb team, we started converting all this data into the SPO format and indexing it under one system. I named the system Plasma, a real-time graph indexing system for the graph serving system, Dgraph.
Like Cerebro, Plasma was an under-funded project but kept on gaining steam. Eventually, when management came to realize that OneBoxes were imminently moving to this project, they needed the “right people” in charge of Knowledge. In the midst of that game of politics, I saw three different management changes, each with zero prior experience with graphs.
During this shuffle, Dgraph was considered too complex by management who supported Spanner, a globally distributed SQL database which needs GPS clocks to ensure global consistency. The irony of this is still mind-boggling.
Dgraph got canceled, Plasma survived. And a new team under a new leader was put in charge, with a hierarchy in place reporting to the CEO. The new team – with little understanding or knowledge of graph issues – decided to build a serving system based on Google’s existing search index (like I had done for Cerebro). I suggested using the system I had already built for Cerebro, but that was rejected. I changed Plasma to crawl and expand each knowledge topic out a few levels, so this system could treat it like a web document. They called it TS (name abbreviated).
This meant that the new serving system would not be able to do any deep joins. A curse of a decision that I see in many companies because engineers start with the wrong idea that “graphs are a simple problem that can be solved by just building a layer on top of another system.”
After a few more months, I left Google in May 2013, having worked on Dgraph/Plasma for just about two years.
A few years later, Web Search Infrastructure was renamed to Web Search and Knowledge Graph Infrastructure and the leader to whom I had demoed Cerebro came to lead the Knowledge effort, talking about how they intend to replace blue links with knowledge — directly answering user queries as much as possible.
When the team in Shanghai working on Cerebro was close to getting it into production, the project got pulled from under their feet and moved to the Google NY office. Eventually, it got launched as Knowledge Strip. If you search for [tom hanks movies], you’ll see it at the top. It has sort of improved since the initial launch, but still does not support the level of filtering and sorting offered by Cerebro.
All the three tech leads (including me) who worked on Dgraph eventually left Google. To the best of my knowledge, the other two leads are now working at Microsoft and LinkedIn.
I did manage to get the two promotions and was due for a third one when I left Google as a Senior Software Engineer.
Based on some anecdotal knowledge, the current version of TS is actually very close to Cerebro’s graph system design, with subject, predicate and object each having an index. It, therefore, continues to suffer from the join-depth problem.
Plasma has since been rewritten and renamed, but still continues to act as a real-time graph indexing system, supporting TS. Together, they continue to host and serve all structured data at Google, including Knowledge Graph.
Google’s inability to do deep joins is visible in many places. For one, we still don’t see a
marriage of the various data feeds of OneBoxes: [cities by most rain in asia] does not produce a
list of city entities despite that weather and KG data are readily available (instead, the result is
a quote from a web page); [events in SF] cannot be filtered based on weather; [US presidents]
results cannot be further sorted, filtered, or expanded to their children or schools they attended.
I suspect this was also one of the reasons to discontinue Freebase.
Two years after leaving Google, I decided to build Dgraph. Outside of Google, I witnessed the same indecision about graph systems as I did inside. The graph space had a lot of half-baked solutions, in particular, a lot of custom solutions, hastily put together on top of relational or NoSQL databases, or as one of the many features of multi-model databases. If a native solution existed, it suffered from scalability issues.
Nothing I saw had a coherent story with a performant, scalable design at heart. Building a horizontally scalable, low-latency graph database with arbitrary-depth joins is an extremely hard problem and I wanted to ensure that we built Dgraph the right way.
The Dgraph team has spent the last three years — not only learning from my own experience but also putting a lot of original research into the design — building a graph database unparalleled in the market. So companies have the choice of using a robust, scalable, and performant solution instead of a yet another half baked one.
Thanks for reading this post. If you liked this post, show us some love and give us a star on GitHub.
Dgraph is a trademark of Dgraph Labs, Inc. (FWIW, Google does not release projects externally with the same name as they are referred to internally.) ↩︎
Some more queries powered by Cerebro:
[female african american politicians],
[bollywood actors married to politicians],
[children of us presidents],
[movies starring tom hanks released in the 90s] ↩︎
