
GraphQL Sorting: A Beginner's Guide
Sorting data in GraphQL is a powerful tool that enhances the usability and performance of your applicatio ...
Learn more

This post made it to top 10 on HackerNews front page. Do engage in discussion there and show us love by giving us a GitHub star.
GraphQL has taken the app development world by storm because of its immense benefits. GraphQL adoption by UI development teams has brought in a new wave of flexibility in API design, productivity across frontend-backend teams, intuitiveness in expressing UI data requirements, and accessibility to powerful tooling. These benefits are why many tech companies, including Facebook, Airbnb, Paypal, GitHub, and Shopify, are embracing GraphQL.
Designing the GraphQL schema is often the first step in your app development journey using GraphQL. This guide presents an intuitive, straightforward process to design your GraphQL schemas, and modify them as your application UIs become increasingly complex.
Expressing the data requirements of your application in your GraphQL schema is easy for simple UIs. However, it can become more difficult as your UI becomes more extensive and more complex. A StackOverflow page or an Amazon product page are classic examples of complex application user interfaces.
Most of the benefits offered by GraphQL are due to GraphQL Schemas. Schemas enable automatic code generation, validation and parsing, introspection, and type safety for your APIs. In many ways, schemas are like strong typing in programming languages, in that they can catch errors while a system is being constructed, as well as helping deal with errors at runtime.
A GraphQL schema is a description of the data clients can request from a GraphQL API. It also defines the queries and mutation functions that the client can use to read and write data from the GraphQL server. In other words, you specify your client or application UI data requirements in your GraphQL schema.
Application Data
Consider a simple blogging application with two distinct app screens.
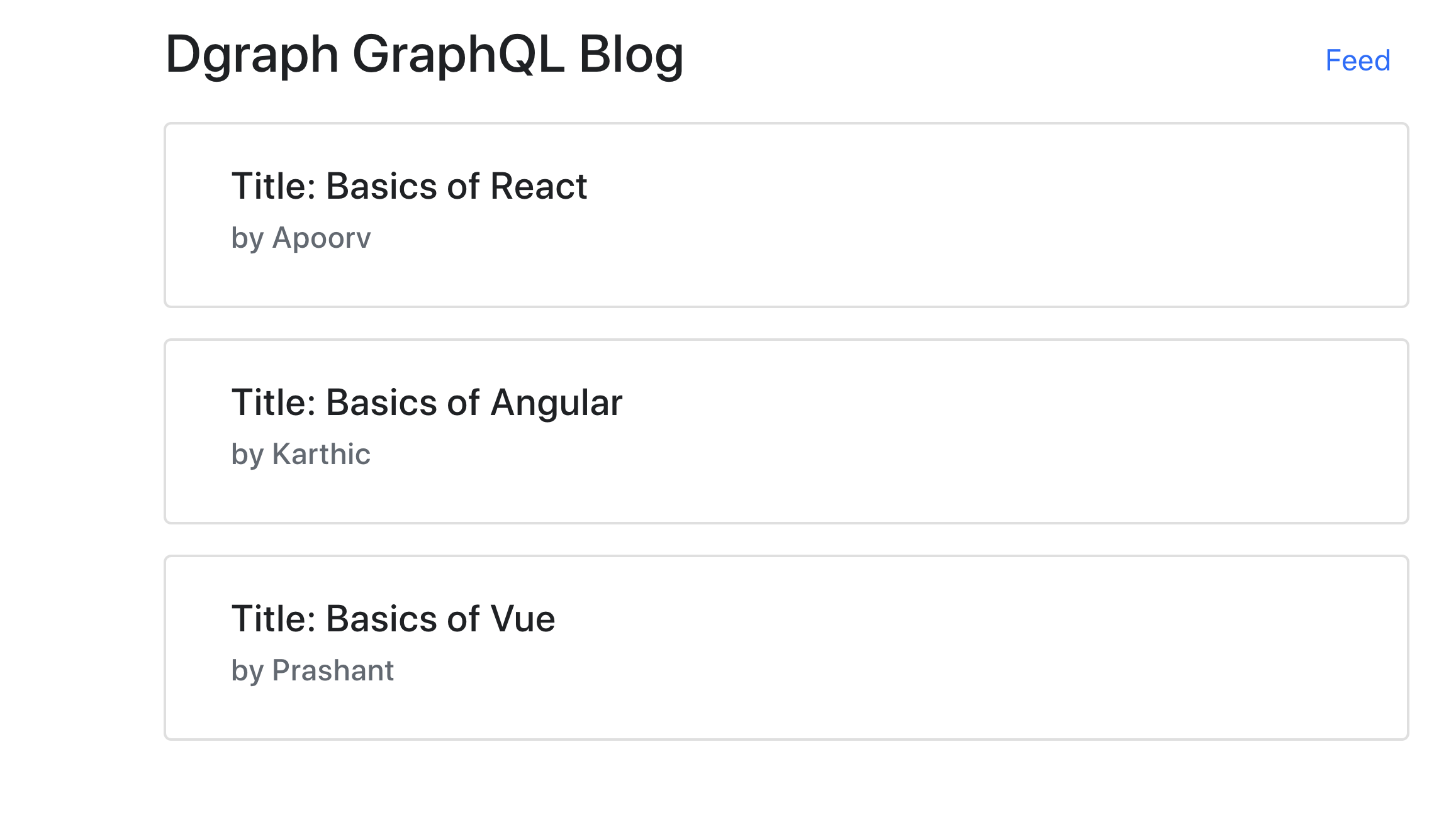

The application data requirement describes all the information your application UI expects to be served from the backend.
The data requirements of the table of contents are:
The data requirements of the content page are:
Once you identify the data requirements, you can group different data entities.
The title and content of the blog can be grouped under a Blog post entity. Similarly, the Author name or any other Author info can be grouped under the Author entity.
The Blog post entity consists of
A title
The content of the post
The Author entity consists of
By making the Author a separate entity, you can associate more than one blog post with an author, and also add more information about an author (e.g., the email address, personal website, etc.) without having to change multiple blog posts.
Data entities are generally related to each other. But how to represent the relationship between different data entities? Read on.
If you’ve wondered why there is a Graph in GraphQL, here is the quote from graphql.org, the official GraphQL site:
“Graphs are powerful tools for modeling many real-world phenomena because they resemble our natural mental models and verbal descriptions of the underlying process. With GraphQL, you model your business domain as a graph by defining a schema; within your schema, you define different types of nodes and how they connect/relate to one another.”
In short, a GraphQL schema is a textual representation of your application’s data graph and the operations on it. Your data graph defines the entities and the relationships between them. But to complete a schema, you usually need to add GraphQL operations. The GraphQL operations provide the information needed to generate and validate operations on the data graph.
To describe the relationship between the two entities in the blog post application mentioned above:
Compared to the rows and columns used in traditional relational databases, graphs are a much easier and more intuitive model to represent data and their relationships. Here is the diagram of the graph model for the blog application:

The graph represents the entities in application data as nodes in the graph, and their relationships are represented as edges. The title, content and author name are represented as properties of the node below the entity names.
By convention, you capitalize entity names. Note that this diagram uses CamelCase (e.g., BlogPost, Author) for entity names, and camelCase for data fields and relationship names. This casing practice is not a requirement, and the GraphQL spec doesn’t dictate any convention. This casing practice is widely followed because the same convention can be mapped to data structures representing the object types in your programming language.
Also, the asterisk (*) near the arrowhead of the hasBlog means this is a one-to-many relationship. A single author can be associated with multiple blog posts, one blog post, or even no blog posts.
The last step in designing the schema is to translate the application data graph into a GraphQL schema.
The GraphQL spec defines a language called the Schema Definition Language (SDL) to write GraphQL schemas.
You use the available types defined by SDL to compose your GraphQL schema. We cover four of the types in this article:
You’ll learn more about these types (and others) in upcoming articles.
It can be challenging to represent types as GraphQL schema, especially with complex and extensive UIs. However, follow the four steps below to represent your types as a GraphQL schema like a pro.
Based on the data graph of the blog post application above, it has two nodes representing two entities: BlogPost and Author. Both entities are represented as object types in the GraphQL schema.
type BlogPost {
}
type Author {
}
The built-in scalar types in GraphQL are Int, Float, String, Boolean, and ID. You can add scalar types as fields to the (previously defined) object types in the schema. These scalar types represent the properties of their corresponding entities.
The data fields for the BlogPost entity are title and content, and both are type String. If a field is mandatory, specify this with an exclamation point (!).
type BlogPost {
title: String!
content: String!
}
Similarly, add a property called name of type String to the Author object.
type Author {
name: String!
}
Defining a field as mandatory is a type modifier, which is not specified in the data graph. If a field is mandatory, that means that its value cannot be undefined or null. You can determine if a field is mandatory by figuring out if operations on the graph assume whether this field is defined. For example, a blog post needs a title and some content to be displayed correctly. If a BlogPost entity is created without defining both, an error would be thrown in the result.
A relationship in a GraphQL schema is represented by adding an object type as a field inside another object. The edges that are connecting the nodes represent the relationships between the entities.
In the graph above, the edge connecting a BlogPost node to an Author node is named hasAuthor. Add a field named hasAuthor of type Author, inside the BlogPost type to represent this relationship. Note that a blog post has to have an author, in addition to a title and content.
type BlogPost {
title: String!
content: String!
# It's required that every blog post has an author
# Hence the exclamation (!) to mark it as required
hasAuthor: Author!
}
Similarly, the edge connecting an Author node to its BlogPosts is named hasBlog. Add a field hasBlog of type BlogPost, inside the Author type to represent this relationship.
type Author {
name: String!
# An author can have more than one blog post
# Hence representing this as an array [BlogPost]
hasBlog: [BlogPost]
}
The square brackets around [BlogPost] indicates that the hasBlog field is stored as an array. Because an author can be associated with 0, 1, or more blog posts, so the one-to-many relationship was indicated by the asterisk (*) in the data graph.
This schema represents the application data graph for our blog application.
While object types help you represent the data graph, they don’t help you define the operations on it. To include the operations on the data graph, you need Query types and Mutation types. The Query types define the read operations, and the Mutation types define the write operations on the data graph. They define the type signatures of operations that are used by your application to read or write data.
For example, to fetch all of the blogs with their tables of content, you need to define a field in the Query type that returns an array of blog posts, like this:
type Query {
# Return all blog posts
# Satisfies the data requirement for the first page
getAllBlogs(): [BlogPost]
}
type BlogPost {
title: String!
content: String!
# It's required that every blog post has an author
# Hence the exclamation (!) to mark it as required
hasAuthor: Author!
}
type Author {
name: String!
# An author can have more than one blog post
# hence representing this as an array [blogpost]
hasBlog: [BlogPost]
}
Next, you need an operation to fetch a specific blog post. To enable this operation, you need to associate a unique ID with every blog post. The ID of a blog post is used to fetch the blog content for the second application screen.
ID is a scalar type in GraphQL that represents a unique identifier and is added as a field to the BlogPost and Author object type to uniquely identify each Author and their BlogPosts.
type BlogPost {
id: ID!
title: String!
content: String!
# It's required that every blog post has an author
# Hence the exclamation (!) to mark it as required
hasAuthor: Author!
}
type Author {
id: ID!
name: String!
# An author can have more than one blog post
# hence representing this as an array [blogpost]
hasBlog: [BlogPost]
}
Now, you can extend the Query type in the schema by adding a getBlogPost field; this field can fetch a blog post with its unique ID.
type Query {
# Return all blog posts
# Satisfies the data requirement for the first page
getAllBlogs(): [BlogPost]
# Returns a single blog post given it's ID.
getBlogPost(id: ID!): BlogPost
}
Similarly, you can add fields to the Mutation type to create new objects. For example, here is a Mutation field to create new blog posts:
type Mutation {
addBlogPost(title: String!, content: String!, authorID: ID!): BlogPost
}
Voila! You have successfully created the GraphQL schema for your simple blog application:
type Query {
getAllBlogs(): [BlogPost]
getBlogPost(id: ID!): BlogPost
}
type Mutation {
addBlogPost(title: String!, content: String!, authorID: ID!): BlogPost!
}
type BlogPost {
id: ID!
title: String!
content: String!
hasAuthor: Author!
}
type Author {
id: ID!
name: String!
hasBlog: [BlogPost]
}
For most of the common read-write operations, you can define CRUD functions named for your types. In the blog post application case, you could name them as addAuthor, queryAuthor, UpdateAuthor, and DeleteAuthor. You can add more Query and Mutation functions later to your GraphQL schema for handling custom logic that is more complicated than the basic CRUD operations.
GraphQL schema defines the signature of your GraphQL API, but it’s not yet functional.
To make it functional, you still need to run a GraphQL web server, write server-side code, and use a database to store and retrieve the data.
Next, let’s dive into how to use Dgraph GraphQL to obtain production-grade, scalable GraphQL APIs in a couple of simple steps - with only the GraphQL object types from your schema.
What is Dgraph GraphQL?
Dgraph is an open-source, distributed, transactional, native GraphQL database. Last week, we released the GA version of Dgraph 20.03.00. It comes with GraphQL out of the box.
To get started with Dgraph GraphQL is extremely simple. Just compose a GraphQL schema containing types to represent the data requirements of your application and submit it to Dgraphs HTTP endpoint. No need to initiate the database. No schema mapping or layering.
Dgraph takes those types, prepares graph storage for them, and auto-generates a production-ready, scalable CRUD Graph API with Queries and Mutations instantly.
All of these in only two steps, without having to write any server-side code or having to run your GraphQL server.
Step 1: Run Dgraph GraphQL
Use Dgraph standalone image to run Dgraph for a quick start.
docker run -it -p 8080:8080 -p 9080:9080 -p 8000:8000 dgraph/standalone:v20.03.0
Step 2: Submit your schema to Dgraph GraphQL
Save the GraphQL schema with your GraphQL types in a file, we’re calling it schema.graphql. Don’t bother adding the Query and Mutations types, Dgraph GraphQL auto-generates it for you.
type BlogPost {
id: ID!
title: String!
content: String!
hasAuthor: Author!
}
type Author {
id: ID!
name: String!
hasBlog: [BlogPost]
}
Upload the schema to Dgraph GraphQL HTTP endpoint
curl -X POST localhost:8080/admin/schema -d '@schema.graphql'
That’s it! You now have a production-ready, scalable GraphQL API!
Point your favorite GraphQL client to http://localhost:8080/graphql and start using it!
In this blog post, you learned an intuitive approach to design your GraphQL schema and some of the GraphQL types defined by the Schema Definition Language (SDL).
In the upcoming articles, we will show you how to compose a GraphQL schema and obtain functional GraphQL API for more complex UIs.
Subscribe to our email list so you will receive the article directly in your inbox. Until then, keep building smarter apps!
