
This post made it to the front page of Go Reddit for over 24hrs. Do engage in discussion there and show us your love by giving Dgraph a GitHub Star.
Software is only as strong as the engineer writing it. This post is dedicated to all the engineers who put relentless efforts in writing and debugging systems to make them stable and reliable for others to use.
The year was 2018. It was 9 pm. I started my day at 8 am. This particular Jepsen test was unforgiving. I could not figure out why this Jepsen test would continue to fail. Just the day before, this test had passed 16 out of 16 times.
Jepsen produces randomness and chaos. This entails the test can pass sometimes but that doesn’t mean there is no bug. Though if it fails even once, that proves the presence of a bug. A more definitive way of ascertaining a fix is to loop the test repeatedly. 16 pass out of 16 run was a pretty encouraging score.
Today, however, that test was failing consistently.
I was tired and alone in a small rented office in San Francisco’s financial district. This was not the typical glass-walled office you see in WeWork ads. This was Regus, with thick walls with a wood door. The office space made you feel isolated – you could sit in it a whole day without seeing anyone else.
Some months before, I had created a branch called f*ck-the-bank, with a
possible fix for the issue revealed by this test. The name came out of
frustration with the Jepsen test called the bank test.
Jepsen is a framework for distributed systems verification with fault injection. Jepsen test is a Clojure program that uses the Jepsen library to set up a distributed system, run a bunch of operations against that system, and verify that the history of those operations makes sense.
Jepsen has been used by many distributed transactional databases to verify their consistency guarantees in not only healthy clusters, but also across a bunch of failure condition nemesis like process crashes, network partitions, clock skews, and so on.
Dgraph is the first graph database to have been Jepsen tested. In fact, for a seed-stage company (at the time), it was quite remarkable to have engaged Kyle Kingsbury a.k.a Aphyr, an industry veteran to help find issues with the newly built distributed transaction system in Dgraph. The process identified 23 issues, out of which we were able to resolve 19 by the time the collaboration ended. The last four, however, were very challenging. The most complex of them was the bank test.
The bank test begins with a fixed amount ($100) of money in a single account and proceeds to randomly transfer money between accounts. Transfers proceed by reading two random accounts by key and writing back new amounts for those accounts. Concurrently, clients read all accounts to observe the total state of the system. The total of all account balances should remain constant throughout this entire test.
The bank test is then coupled with various nemeses that kill processes, move shards around, and introduces network partitions and clock skews.
If there was a weakness in the transactional integrity and data consistency of the database, this test would surely find it. And it did for Dgraph.
I had put everything into fixing these test failures over the previous few months. The code was a mess: patch over patch was added to fix individual issues as were encountered by the engineers, without challenging the overall design in place.
I had first tried to understand the reasoning behind all that mess and simplify it. But later realized it was all based on older assumptions, no longer true. No one had challenged the underlying assumptions with the evolved understanding of the transactional system. By re-architecting the design, the code could be hugely simplified. So, I had rewritten the whole thing from scratch over the past few months.
The rewritten, simplified codebase did fix a variety of Jepsen issues. The last major stronghold was the bank test.
That evening, after the 16th re-run of the test passed, I was ecstatic. My last fix must have solved the issue. To confirm, I set it up to be run overnight. I left late, excited about the possibility of finally having solved the bug caught by the bank test. My home was a 10 min walk from the office. By the time I reached home, my wife and daughter were fast asleep. I re-heated the dinner left on the kitchen counter for me and got to bed.
The next morning I woke up early, picked up a cup of ristretto from the coffee shop on the way, and rushed to the office. It was 8 am. I eagerly logged into my desktop to see the result of the tests which I had run overnight. Turns out, the first run itself had failed. It did not bother continuing beyond the first half an hour.
By 9 pm, I had thrown everything I had at fixing the test. Exhausted and demotivated, I realized I still did not have a solution. This test had truly sucked the life out of me.
Jepsen is an incredible testing framework. However, it is essentially black-box testing. While it does produce logs of the actions it takes, it is very hard to correlate each of those actions with what went on inside the system.
Looking at Jepsen or Dgraph logs wasn’t sufficient to debug the problem. It was at best guesswork. Moreover, Jepsen being written in Clojure made it even harder to tweak the codebase to introduce more visibility. Clojure developers are hard to come by (now that our team has grown to over 30 engineers, we finally have one person who can speak Clojure).
Back at Google, I had heard about Distributed Tracing. Dapper as it was called, helped provide more information about the behavior of complex distributed systems. It helped figure out latency and other issues seen by a request being processed by multiple servers.
I had never used Dapper myself. My team, in charge of building a real-time
incremental indexing system for the entire web, was doing local
tracing, i.e. tracing specific to a single server. Because we were running
thousands of servers, even the rarest trace could be found by just doing a
real-time crawl of the live running requests /rpcz on those servers.
Dgraph was doing a similar thing. We were using golang.org/x/net/trace which would give us machine local traces, but not track a single request across servers. While local tracing was useful to understand generally what was going on in the system, the disassociation with the query caused them to be ineffective in understanding why a particular transaction misbehaved.
I knew about an open-source distributed tracing framework and felt it could be useful to integrate that into Dgraph. But, that task was in the ever-growing long list of backburner items. We had new customers, big Fortune 500 companies knocking at our door, and I had little time to spare on ideas with unproven utility.
But by 9 pm, it was clear that shooting in the dark can only take you so far. If I had to continue making progress with Jepsen test failures, I needed a better way to shed light on what was going on with each transaction request. I needed a lantern. I needed that tracing framework.
OpenCensus (now merged to form OpenTelemetry) is a set of libraries which allow you to collect distributed traces, then transfer the data to a backend in real-time.
OpenCensus works by having a unique request-id. This id is maintained even if the request goes over the network. In Go, this is done by encoding this id in context, which gets passed along by Grpc. Multiple servers involved in handling parts of this request would all send their portion of the execution trace to the common backend. This backend would then stitch-up the various parts to show you a trace of the entire request execution across all servers.
Each of these requests has multiple spans. Each span can be annotated with useful information to help you debug what was going on.
I replaced most of the net/trace tracing with OpenCensus spans in
9e7fa0. In particular, I added annotations so we can search any trace by a
transaction start timestamp.
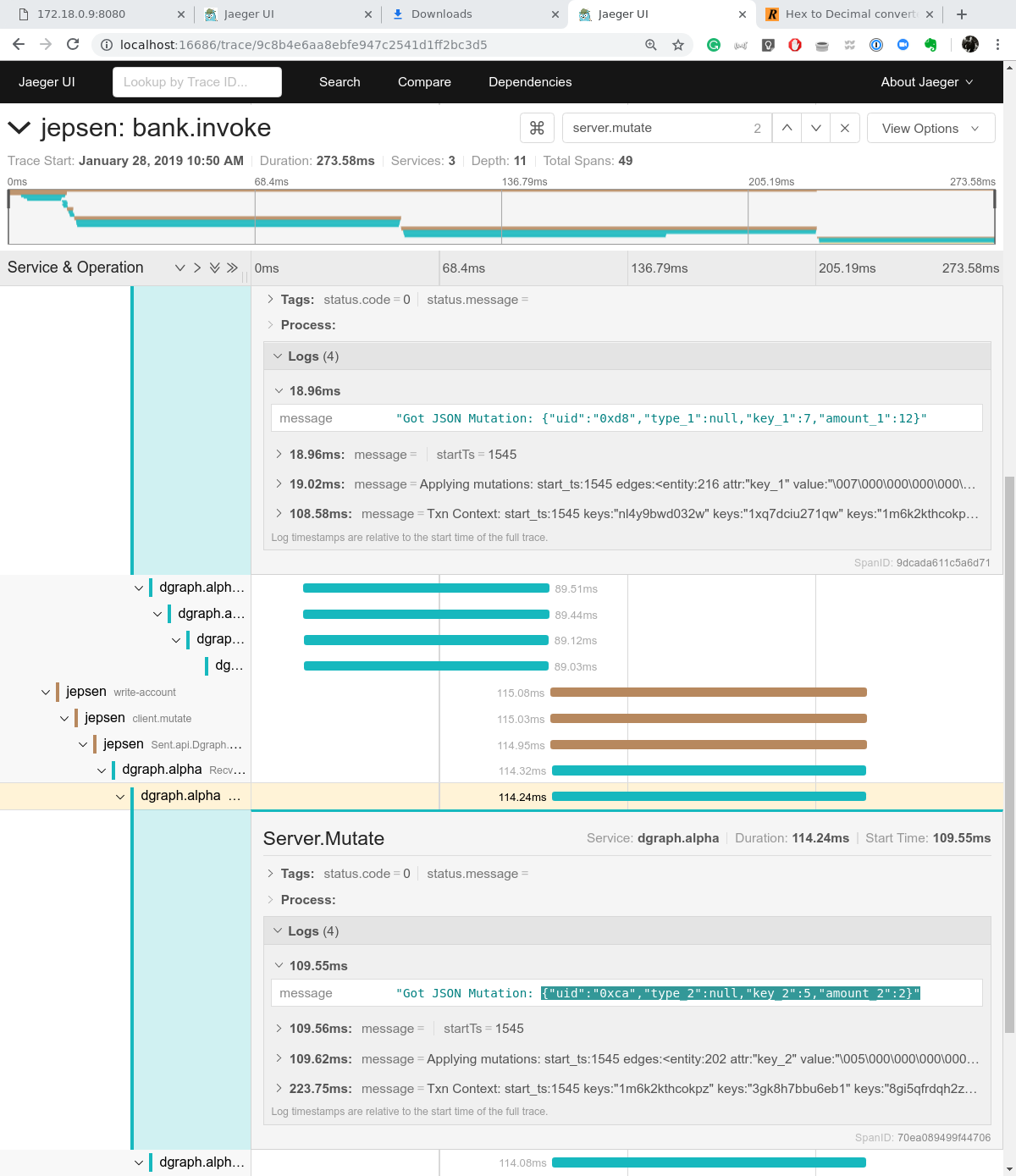
The above shows a request trace from Jepsen to Dgraph in Jaeger. It is our favorite distributed tracing system to look at these traces. In fact, Jaeger recently introduced Badger support, which makes us love and recommend it even more.
Got it. Fixed it. Squashed it. Done with it. Tamed it. — 3b6d81
Within a week of first OpenCensus integration, I was able to identify the cause of bank test failure. It happened during a network partition. As I note in my commit message.
Open Census and Dgraph debug dissect were instrumental in determining the cause of this violation. The tell-tale sign was noticing a /Commit timeout of one of the penultimate commits, to the violating commit.
The cause of the violation (might be hard to follow, feel free to skip), as explained in the commit message, or slightly better explained by Aphyr in his new report, section 3.3 is as follows:
When a Zero leader received a commit request for a transaction T, it assigned a timestamp to that commit. If Zero was unable to communicate with its Raft peers, and a new Zero node became the leader, that new leader would begin allocating timestamps at a significantly higher number. Alphas interacting with the new Zero leader would advance their max-applied timestamps to match.
Then assume the original Zero leader rejoined the cluster as a follower, and retried its commit proposal—this time, succeeding. Because this new proposal kept the original transaction timestamps, two problems could occur:
A read R executed after the new leader advanced the clock, but before T’s commit was retried, could fail to observe T – even though T would go on to commit in the logical past of R. In essence, this allowed temporary “holes” in the timeline of transactions.
When an Alpha node applied a write w for key k, it would first check k’s last written timestamp, and ignore w if it was lower. If w was a write from the logical past, w might be rejected – but other writes from the same transaction might succeed, so long as they hadn’t been written recently. This allowed Dgraph to partially apply transactions.
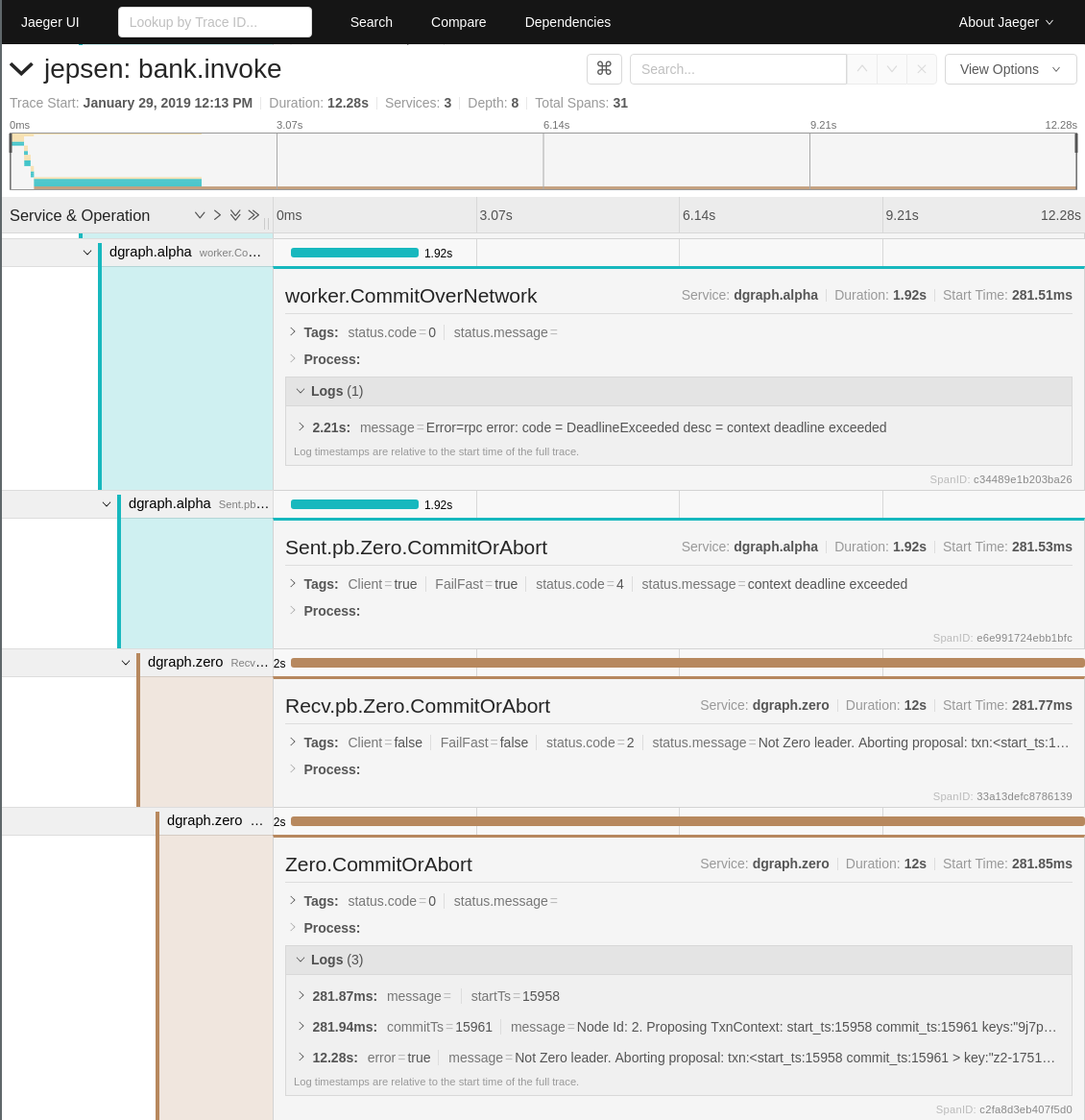
This was a complex find. But using OpenCensus as a lantern to light every path that a distributed transaction took helped determine the cause quickly.
The fix was to disallow a Zero1 raft follower from forwarding proposals to the leader. So, only Zero leader can propose to raft. That way, if a leader steps down, while in a loop to get a quorum on a proposal, that proposal would fail – which is the intended behavior here to avoid a transactional guarantee failure.
Why run proposals in a loop, you ask? Why not give up on the first failure? The raft library that Dgraph is using can drop proposals without returning errors or any other identifiable indications. So, if after having sent a proposal, you don’t see it come back in the committed log after some duration, you have to retry. However, the messages can also be delayed due to high activity. So, Dgraph does exponential backoff retries, until the proposal is finally seen at the other end.
Dgraph allows automatic shard migrations to balance data load across servers. This is infrequent as you can imagine. However, Jepsen specifically targeted this feature by moving shards as fast as possible to introduce transactional violations.
Issue 2321 captures the bug detected. With OpenCensus, the reason became clear. I saw that an Alpha server serves a request for data in a shard S, even after S had been moved to another server.
In Dgraph, Zero holds the source of truth of membership information about which Alpha server serves which data and transmits that over to all the Alphas in the cluster. In this case, there was a race condition between the shard movement and the Alpha server getting to know about it from Zero. So, an Alpha server after having done the move could end up serving a request, thinking that it is still serving that shard.
Aphyr explains this in his new report in section 5.1:
In more general terms, tablet migrations were error-prone because changing distributed state is just plain hard. Dgraph relies on Raft for state changes within a group, and Raft is a solid algorithm with mature implementations that handle failure well. Dgraph coordinates transactions between Raft groups by having nodes agree on which groups own which tablets. This too is relatively straightforward—as long as that mapping doesn’t change. When mappings are stable, everyone’s requests go to the right groups, and Raft handles it from there. When the mapping changes, nodes might be out of date: Dgraph doesn’t, for performance reasons, use a consensus protocol for tablet mappings. Instead, nodes asynchronously discover mapping changes via side channels, which makes agreement trickier.
Both of the above fixes were from late 2018 to early 2019. OpenCensus integration helped identify these complex issues, which no amount of guessing permutation would have achieved.
OpenCensus benefits didn’t stop there. Even more recently as Mar 2020, we
fixed a two-year-old bug in our codebase, causing nil responses to
be returned for data under very specific scenarios.
Beyond helping us identify and fix bugs, anytime our clients experience query latency issues, an important step in our debugging process is to ask them for the query trace. It reveals so many things about exactly what happened with that query, any steps which were becoming the bottleneck and can tell what was going on in the system which lets us pinpoint the issue quickly.
OpenCensus has come the closest to becoming an advantage in debugging Dgraph. Despite being introduced just to help solve Jepsen issues, distributed tracing has become a central part of Dgraph’s debugging workflow.
As Aphyr would put it, failure of detecting the presence of bugs is not the same as not have bugs.
We cannot prove correctness, only suggest that a system is less likely to fail because we have not, so far, observed a problem. — https://jepsen.io/ethics
I concur wholeheartedly.
I would add, however, that not being able to hit bugs under extreme tests like the kinds Jepsen produces, does inspire confidence in the stability of the software. And ultimately, adding quality tests is the best you can do to improve your software.
Aphyr recently completed another round of testing on Dgraph, and found that Dgraph resolved all issues from the earlier 2018 report, but went on to find some issues related to tablet moves.
Just to address those issues: In Dgraph, tablet moves are infrequent. Jepsen tests cause moves at a rapid, unnatural, pace. This is completely expected considering Jepsen’s job is to identify if the system breaks in extreme scenarios, but the chances of them affecting a Dgraph user is rare. So, while we need to investigate and fix these issues, their priority is low considering all the other things that we’re working on.
But I do no doubt that when we do get to them, OpenCensus would let us identify the issues and fix them quickly.
That’s the hard thing about hard things — there is no formula for dealing with them. - Ben Horowitz
2018 was hard. Working from 8 am to 9 pm is hard. Building a distributed graph database is hard. Making it have distributed transactions is hard. Having those pass Jepsen is hard. But, that’s why you pick up hard things to build — precisely because they are hard.
All the efforts that went into Dgraph in 2018 have brought it to a place where we can confidently stand behind Dgraph’s consistency guarantees. So, when you are exhausted, demotivated and alone, keep pushing!
P.S. I’d like to thank Emmanuel for helping integrate OpenCensus with Dgraph, to Kyle for integrating Jepsen tests with Dgraph, to Kit for integrating OpenCensus with Jepsen, and to all Dgraph contributors in helping build this amazing software.
If you are curious about Dgraph’s architecture, you can read this paper, which goes into details of the internal workings of Dgraph. ↩︎

