
Build a Realtime Recommendation Engine: Part 2
This is part 2 of a two-part series on recommendations using Dgraph. Check our part 1 here.
In the last p ...
Learn more

In today’s world, user experience is paramount. It’s no longer about basic CRUD, just serving user data; it’s about mining the data to generate interesting predictions and suggesting actions to the user.
That’s the field of recommendations. They’re everywhere. In fact, they happen so frequently that you don’t even realize them.
You wake up and open Facebook, which shows you a feed of articles that it has chosen for you based on your viewing history.
Want to buy something? Amazon would recommend you things to purchase based on what you’ve viewed in the recent past.
Want to relax and unwind with a movie? Netflix would recommend you what to watch based on your interests.
No time to watch a full movie? YouTube would recommend you smaller chunk videos.
Want to listen to music instead? Spotify would generate a weekly discovery list of songs just for you.
All this makes you wonder: Should recommendations be part of your application? While competing against Netflix might be hard, in this two-part series, we’ll explain the basics of a recommendation engine. We’ll show how you can build recommendations via two approaches: Content-based filtering and Collaborative filtering. And, how you can use Dgraph to bring recommendations to your app without breaking a sweat.
For this, we’ll make use of Dgraph’s query variables. To learn more about variables, head over to Dgraph tour — if you are new to Dgraph variables, you really should check them out first before diving in here.
Let’s first check out how recommendation systems work, and then we’ll look at the support Dgraph queries offer. We’ll use two sample datasets. One about movies and ratings (Movielens) and the other is part of Stack Exchange’s data archive — we’ll just use the Lifehacks dataset here, but watch out for a coming series of posts where we show how to load all of Stack Overflow into Dgraph and run the entire website completely off Dgraph.
Making Recommendations is a subtle art. There are a number of approaches and a production worthy recommendation system might depend on data, weighting of various features, global user behaviour and maybe recent behaviour of the user we are recommending for.
Rather than just inventing recommendation queries, let’s start somewhere more grounded. For this post, we started with the Stanford University MOOC Minning Massive Datasets. Part of the course is on recommender systems. We’ll show how the theory in the ‘‘Recommendation Systems’’ chapter of the text can be translated into practice using Dgraph. We’ll also talk about other approaches and how to run one at scale.
Making recommendations is about taking past benaviour and preferences and trying to predict a preference for some unknown. For example, later in the post, we’ll talk about movie recommendations. For this, we know what a user has watched and how they rated movies; how then can we predict what unwatched movies they’ll enjoy.
As briefly mentioned before, broadly speaking, there are two basic approaches:
Content-based: Such systems base a recommendation on the properties of an item. Two items that have similar properties are deemed similar; the more properties shared, the more similar. For example, if a user likes movies with certain actors or directors, we can recommend other movies involving the same people.
Collaborative filtering: Such systems base recommendations on the relationship between users and items, and similarity to other users. Users are similar if they have relationships to items in common; the more items in common, the more similar. For example, if many similar users enjoyed a particular movie, that might be a good one to recommend.
There are also classification algorithms based on machine learning. We’ll focus here on how far we can get with Dgraph queries alone. Machine learning or other algorithms could also be run over the Dgraph output.
Our Stanford reference text represents data as a sparse matrix. So for our movie data set, we might think of the user’s ratings of movies as:
| User | The Matrix | Toy Story | Jurassic Park | Forrest Gump | Braveheart |
|---|---|---|---|---|---|
| A | 5 | 4 | 4 | ||
| B | 3 | 4 | 1 | ||
| C | 1 | 2 | 5 |
The movies also have other properties such as genres, not shown here. We’ve stored it all as a graph, which in itself is a nice way to store a sparse matrix.
The matrix (that’s the matrix above, not ’’The Matrix’’) is missing values because users haven’t seen all movies — in fact, for the real dataset it’s much sparser because users have each only rated a tiny percentage of the movies.
The challenge of recommendation is to predict values for the missing ratings. Will user A enjoy Braveheart because it’s an action movie and thus similar to movies they enjoyed? (content based filtering)
But maybe they won’t enjoy it because they might have something in common with user B who seems to share similar ratings (collaborative filtering).
Maybe user A just gives high ratings and isn’t very discriminating — sometimes benaviour rather than rating can be a better predictor. We’ll need to combine a number of approaches.
The theory boils down to finding functions that serve as measures of similarity or distance. For example, in content-based filtering, the function would take two movies and output a score (the distance or similarity). If we start with a movie and apply the function repeatedly to it and all other movies, we can find the most similar movies.
We’ll look at some distance measures below as we apply them in queries, but for any of them we’ll need to propagate values through our query, so let’s look at how that works in Dgraph and then try out some recommendation queries.
A Dgraph value variable is a mapping from graph nodes to values that have been computed for the nodes during the query. Value variables can be passed around the query, aggregated etc. Value variables also sum over paths as we move deeper into a query tree.
Within a query tree, a value variable defined at one level, propagates such that in a nested level, the variable is the sum of all paths from the definition.
We call this variable propagation. Note that the queries in this post we built for our master branch for the upcoming v0.8 release.
Say you had a query:
{
var(func: uid(<...P...>)) {
myscore as math(1) # A
friends { # B
friends { # C
fscore as math(myscore)
}
}
}
closeFriends(func: uid(fscore), orderdesc: val(fscore)) {
name
val(score)
}
}
At line A, nodes are assigned a score of 1 (which in this case we’ll assume is the single node P).
Traversing the friend edge twice reaches the friends of friends. The variable myscore gets
propagated, such that the value inside the block marked C is the sum of values from all paths from A to C.
Here’s how that propagation looks in a graph.
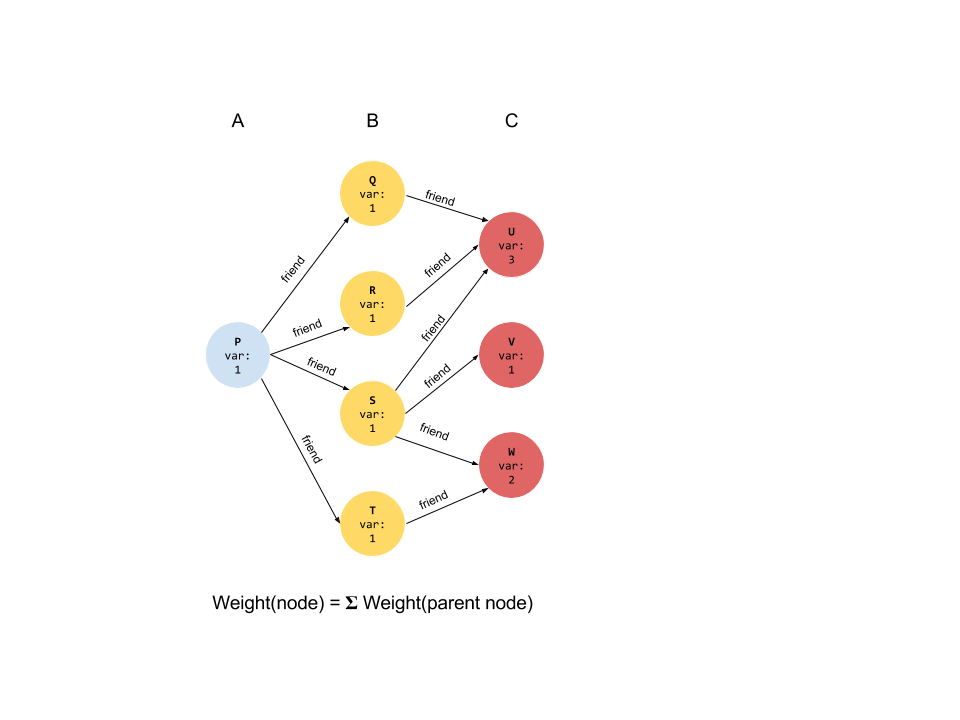
In short, the value that a node receives is equal to the sum of values of all its parent nodes. This propagation is useful when we want to normalize a sum across users, find the number of paths between some nodes or accumulate a sum as we move through the graph.
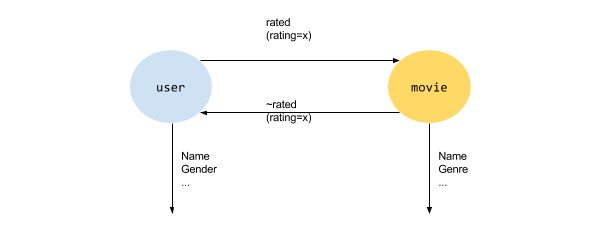
Let’s start with the ML-100k dataset of 100,000 ratings from 1000 users on 1700 movies. We converted the dataset to RDF (the dataset and script can be found at github) and loaded it into Dgraph.
It’s about users and movies and user’s ratings of movies. So a user (a node in the graph) has a name and a gender and a rated edge to a movie. The rated edge has a facet rating that tells us the users numeric 0–5 rating of the movie.
Content-based filtering ranks items as similar or not based on their properties. There are a number of measures we could use. Our reference text from Stanford talks about Jaccard and Cosine distances.
Let’s try some measure functions based on Jaccard distance. For two sets A and B the Jaccard distance is given by
$$1-\frac{|A\cap B|}{| A\cup B |}$$
That’s the ratio of the size of the set intersection to the size of the union. So if items have many properties in common (compared to how many properties each has) then the items are similar. For our movie example, let’s take $A$ and $B$ as the genre sets for each movie. We can then express our difference function as:
$$d(M_1, M_2) = 1-\frac{|M_1.\mathcal{genres} \cap M_2.\mathcal{genres}|}{| M_1.\mathcal{genres}\cup M_2.\mathcal{genres} |}$$
The closer the result is to 0, the closer the movies — if the number of genres in common is more, the second term is close to 1, if movies have few genres in common, the second term is closer to 0.
For movie a $M_1$, we picked ‘‘The Shawshank Redemption’’ with unique ID 0x30d80, and translated Jaccard distance to this query.
{
# Count the genres for every movie that has been rated
var(func: has(~rated)) {
M2_num_genres as count(genre)
}
# Calculate a Jaccard distance score for every movie that shares
# at least 1 genre with the given movie.
var(func: uid(0x30d80)) { # M1
norm as math(1) # 1
M1_num_genres as count(genre) # 2
M1genres as genre { # 3
~genre {
# M2 -- movies reached here share a genre with the initial movie
# normalize the count to account for multiple paths
M1_num_genres_norm as math(M1_num_genres / norm) # 4
num_genres as count(genre @filter(uid(M1genres))) # 5
distance as math( 1 - ( num_genres / (M1_num_genres_norm + M2_num_genres - num_genres) )) # 6
}
}
}
# Sort and return closest movies.
similarMovies(func: uid(distance), orderasc: val(distance), first: 10) { # 7
name
val(distance)
}
}
The query works as follows.
norm to 1.genre paths to find all movies $M_2$ that share a genre with $M_1$.# 2 would have accumulated for each path, so normalize back to the original count.distance is thus a map for each $M_2$ to the Jaccard distance between $M_1$ and $M_2$.Here’s the results we got for ‘‘The Shawshank Redemption’’
{
"similarMovies": [
{
"name": "Miracle on 34th Street (1994)",
"var(distance)": 0.0
},
{
"name": "Postman, The (1997)",
"var(distance)": 0.0
},
{
"name": "Mat' i syn (1997)",
"var(distance)": 0.0
},
{
"name": "Winter Guest, The (1997)",
"var(distance)": 0.0
},
{
"name": "Chamber, The (1996)",
"var(distance)": 0.0
},
{
"name": "Shanghai Triad (Yao a yao yao dao waipo qiao) (1995)",
"var(distance)": 0.0
},
{
"name": "Picnic (1955)",
"var(distance)": 0.0
},
{
"name": "Nell (1994)",
"var(distance)": 0.0
},
{
"name": "Dead Man Walking (1995)",
"var(distance)": 0.0
},
{
"name": "Blue Angel, The (Blaue Engel, Der) (1930)",
"var(distance)": 0.0
}
]
}
Ouch, there’s a bunch of movies with distance 0. That means all those movies share exactly the same genre set with ‘‘The Shawshank Redemption’’, so we can’t discriminate between them. Let’s test another movie. With ‘‘Toy Story’’ we get.
{
"similarMovies": [
{
"name": "Aladdin and the King of Thieves (1996)",
"var(distance)": 0.0
},
{
"name": "Toy Story (1995)",
"var(distance)": 0.0
},
{
"name": "Aladdin (1992)",
"var(distance)": 0.25
},
{
"name": "Goofy Movie, A (1995)",
"var(distance)": 0.25
},
{
"name": "Flintstones, The (1994)",
"var(distance)": 0.333333
}
]
}
That’s better. At least similar movies have similar genres. But still, the Jaccard distance function isn’t good enough because it can’t discriminate a difference between many movies. Our reference text suggests the same distance function but for data that also has actors and directors, which we don’t.
As it stands, the Jaccard distance might not be so appropriate because the only items we have to compare are the genres, since the Jaccard distance doesn’t take into account the magnitude of the ratings. So let’s play around with it and see how some variations come out.
The size of the intersection of the genres seems a reasonable start, but how to bring the magnitude of the ratings into it? If we are to use the ratings, then the average rating might be appropriate. Let’s try the number of genres in common plus an average rating. Given a movie $M_1$ we’ll find the similarity to all other movies $M_2$ as
$$d(M_1, M_2) = |M_1.\mathcal{genres}\cap M_2.\mathcal{genres}| + M_2.\overline{\mathcal{rating}}$$
Here’s the Dgraph query for movie $M_1$ having unique ID 0x30d72, that’s ‘‘Star Wars’’.
{
# M1 -- Star Wars by its unique ID
var(func: uid(0x30d72)) {
g as genre
}
# Calculate the average rating for every movie
var(func: has(rated)) {
allmovies as rated @facets(a as rating) {
c as count(~rated)
avg as math(a / c)
}
}
# Give every movie a score
var(func: uid(allmovies)) {
x as count(genre @filter(uid(g)))
score as math(avg + x)
}
# Return the top 10 movies
fin(func: uid(score), orderdesc: val(score), first: 10) {
name
val(score)
}
}
In terms of variable propagation, the important part is the calculation of average rating. If an edge has a facet and we assign the facet to a variable, we calculate the average. Then for each node reached by the block the variable is the sum of the facets of all such edges reaching the node.
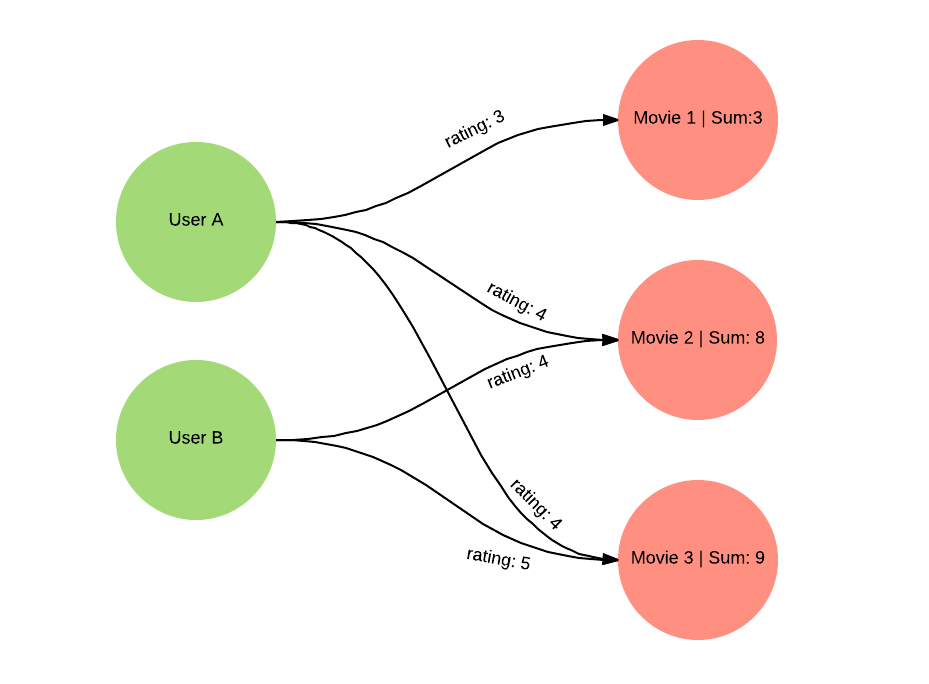
Running the query we get the following results.
{
"fin": [
{
"name": "Star Wars (1977)",
"var(score)": 9.358491
},
{
"name": "Empire Strikes Back, The (1980)",
"var(score)": 9.20436
},
{
"name": "Return of the Jedi (1983)",
"var(score)": 9.00789
},
{
"name": "African Queen, The (1951)",
"var(score)": 8.184211
},
{
"name": "Starship Troopers (1997)",
"var(score)": 7.232227
},
{
"name": "Princess Bride, The (1987)",
"var(score)": 7.17284
},
{
"name": "Star Kid (1997)",
"var(score)": 7.0
},
{
"name": "Aliens (1986)",
"var(score)": 6.947183
},
{
"name": "Star Trek: The Wrath of Khan (1982)",
"var(score)": 6.815574
},
{
"name": "Men in Black (1997)",
"var(score)": 6.745875
}
]
}
Note that we didn’t filter out ‘‘Star Wars’’ and thankfully it came back as the first result. Looks like a pretty good distance function, especially given the top three results, but it’s probably biased. ‘‘Star Wars’’ is highly rated on average, and so we got back other highly rated movies with intersecting genres. If we searched for a movie that wasn’t highly rated on average, the measure would still prefer highly rated movies with intersecting genres.
That might be fine. If a user likes certain genres, then maybe highly rated movie in those genres are good recommendations. Maybe it’s better to normalize the result so that two movies come out as more similar if they have genres in common and similar average ratings. That’s what cosine distance does.
Cosine distance treats our movies as vectors in an n-dimensional space. The similarity of the movies is then a measure of the difference in angle between the vectors. The smaller the angle between two vectors, the more similar the movies. For our movie example, we can express that as follows.
If we treat our movies as vectors
$$x_1 … x_n$$ and $$y_1 … y_n$$
the cosine difference between them is computed by calculating the vector dot product divided by the multiple of the distances from the origin.
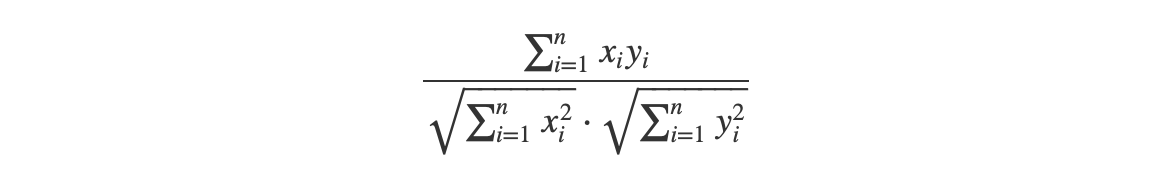
In our case the $x$’s up to $x_{n-1}$ will represent the genres, with 1 for genre present and 0 for not present. While the last term is the average rating. So for our movie example we can express the cosine difference as.
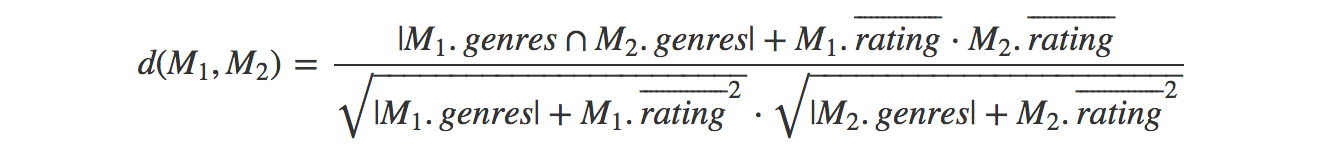
That factors in both the intersecting genres as well as the similarity of the average ratings.
As a single Dgraph query, that looks like this.
{
# Calculate the average rating of every movie
var(func: has(rated)) {
rated @facets(r as rating) {
c as count(~rated)
M2_avg_rating as math(r / c)
M2_num_gen as count(genre)
}
}
# Calculate a cosine difference score for every movie that shares
# at least 1 genre with M1
var(func: uid(0x30d80)) { # movie M1
norm as math(1) # 1
# Find the average rating for M1
M1_num_ratings as count(~rated)
~rated @facets(B as rating)
M1_ratings_sum as sum(val(B))
M1_avg_rating as math(M1_ratings_sum / M1_num_ratings) # 2
M1_num_gen as count(genre) # 3
M1_genres as genre {
~genre { # 4
# M2 -- movies reached here share a genre with the initial movie
# normalize the M1 count and average to account for multiple paths
M1_norm_avg as math(M1_avg_rating / norm)
num_genN as math(M1_num_gen/norm) # 5
genint as count(genre @filter(uid(M1_genres))) # 6
score as math((genint + (M1_norm_avg * M2_avg_rating)) /
(sqrt(num_genN + (M1_norm_avg*M1_norm_avg)) *
sqrt(M2_num_gen + (M2_avg_rating*M2_avg_rating)))) # 7
}
}
}
similarMovies(func: uid(score), first:20, orderdesc: val(score)) { # 8
name
val(score)
}
}
The query works as follows.
norm to 1.genre paths to find all movies $M_2$ that share a genre with $M_1$.# 2 and # 3 would have accumulated for each path, so normalize back to the originals.score is thus a map for each $M_2$ to the cosine distance between $M_1$ and $M_2$.We searched again for the ‘‘The Shawshank Redemption’’ and got these results.
{
"similarMovies": [
{
"name": "Shawshank Redemption, The (1994)",
"var(score)": 1.0
},
{
"name": "Anna (1996)",
"var(score)": 0.999997
},
{
"name": "Some Mother's Son (1996)",
"var(score)": 0.999997
},
{
"name": "12 Angry Men (1957)",
"var(score)": 0.999988
},
{
"name": "Bitter Sugar (Azucar Amargo) (1996)",
"var(score)": 0.999985
},
{
"name": "Citizen Kane (1941)",
"var(score)": 0.999971
},
{
"name": "To Kill a Mockingbird (1962)",
"var(score)": 0.999971
},
{
"name": "One Flew Over the Cuckoo's Nest (1975)",
"var(score)": 0.999971
},
{
"name": "Pather Panchali (1955)",
"var(score)": 0.999965
},
{
"name": "Good Will Hunting (1997)",
"var(score)": 0.999958
}
]
}
We didn’t filter out ‘‘The Shawshank Redemption’’ and thus it comes back as the top result — it has an angle of 0 with itself. Following that the query returns the results that cosine difference calculates as most similar.
With that, we conclude this post. In this post, we showcased Jaccard distance, a variation of Jaccard, and finally Cosine distance. That’s three content-based filtering distance metrics and queries for them in Dgraph. The variables and math function in Dgraph allow us to encode the metrics directly in the query.
In the next post, we’ll take a look at collaborative filtering. We’ll also look at making recommendations for Stack Overflow and how to build a scalable recommendation engine for big graphs.
