
Candidate REJECTED.
4 out of 5 interviewers had liked the candidate. I was one of the 4. He had received either above or very close to 3.0, which is a good score. The interviewer who didn’t like the candidate had been at Google since early 2004. And he didn’t like the candidate’s joke question about whether he was very rich because he joined before Google went IPO. I guess he wasn’t.
The system in place was methodical. On a scale of 0.0 to 5.0, only terrible candidates received less than 2.0. And only in very rare cases did someone receives above 4.0. Anything above 3.0 was a pretty solid YES for hire. But how the interviewers scored a candidate was very subjective. There was no standardized training for interviewers on how to interview. Some people tend to give higher scores; some tend to give lower scores. So, the hiring committee had been asked to take the interviewer’s previous scoring patterns into account, along with how much evidence and conviction they had presented in the feedback form.
It was duct tape on a broken system.
It’s not an issue specific to Google. Many tech companies follow some variance of the same approach. Two phone screens + five onsite technical interviews, followed by feedback presented to a committee which then decided if the candidate should be hired or not.
Except that the interviewers have no particular training in judging other people. Most would ask one question; which would get dragged on for the entire length of the interview. If the candidate did well on that question, they might ask another one. So, if the candidate messes up that first question, there’s no coming back, mostly even including the rest of the interviews (unless you do exceptionally well in the rest).
Also, given the inflow of smart young engineers flowing into the valley, the questions are generic enough to be answered by anyone. So, these drill down to basic computer science concepts – graphs, trees, sorting, and other algorithms. The candidate is expected to come up with a solution and code it up on a whiteboard within the allocated time under pressure.
Not surprisingly, experienced professionals tend to do worse at these interviews than fresh grads. Very few professional tech problem can be coded up in 20 mins. Over years of coding, they lose the practice of solving simple problems under time pressure, instead focusing on deeper, harder design problems.
Google: 90% of our engineers use the software you wrote (Homebrew), but you can’t invert a binary tree on a whiteboard so fuck off.
— Max Howell (@mxcl) June 10, 2015
I’m convinced that the existing technical interview system is expensive and broken.
Without any objective measurement, judging the smarts, skills and experience of an engineer is just handwaving.
Triplebyte recently came up with a post about hiring. I found it instantly interesting. With a lot of data, they found a higher correlation between a quiz and successful candidates; and a lower one between coding questions and successful candidates. This got us thinking. If we wanted to design an objective interviewing system, we should design a quiz. It would have multiple benefits:
And we did exactly this. We painstakingly and after much cross-examination came up with 30 or so quiz questions in the house. These questions test various aspects of algorithms, concurrency and server interaction.
Over the past months, we have had 20 candidates take our quiz. It’s a small number, but it’s still telling. The following graph shows how the candidates fared.
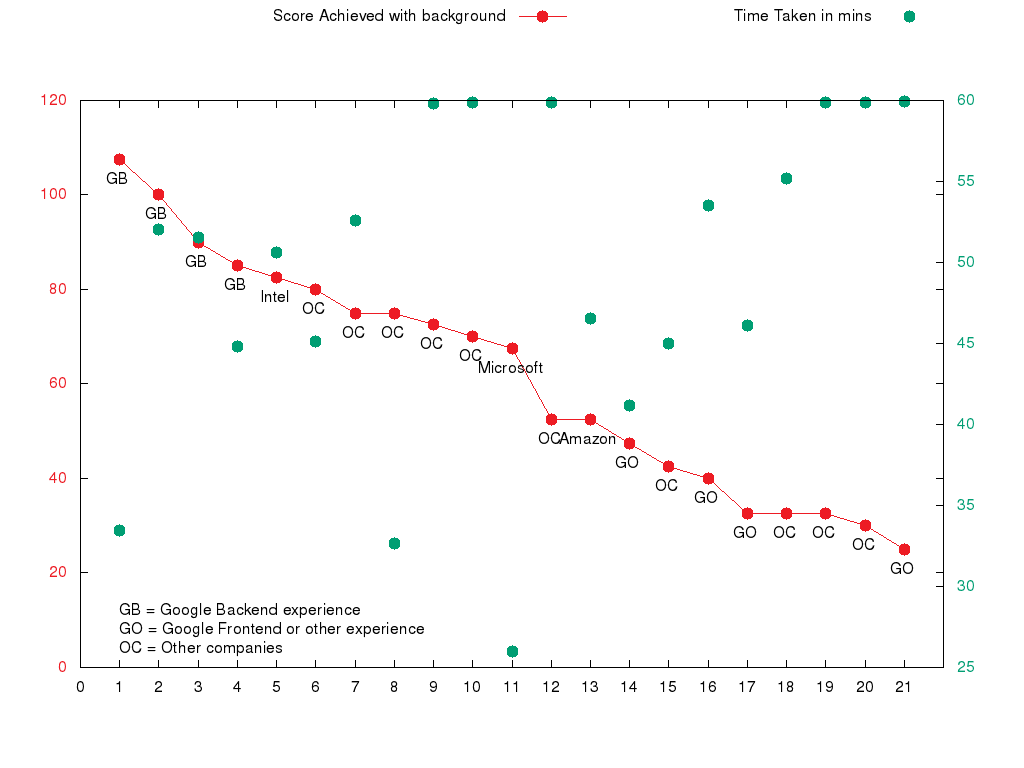
Note that the red dots represent the score (y-axis left), and the green dots represent the time taken (y-axis right). Candidates with experience in big companies are tagged as such - GB for Googlers who primarily worked on backend/infrastructure projects, GO for Googlers who worked on other projects, Intel, Microsoft and Amazon. Every other company whose name we didn’t recognize (startup/smaller company) is tagged as OC.
What we can learn from this:
So, we decided to improve upon this basic quiz and converted it to an adaptive test. Based on Triplebyte’s and our experience, we know that best candidates take less time to solve the quiz. We hypothesize if the best performers were allowed to answer more questions in the same fixed time, their score would have been significantly better.
So, instead of showing a fixed number of questions to be answered in a given maximum time duration, we fix the time and let the candidates answer as many questions as they can in an hour. And if they’re performing well, we show them harder questions carrying higher scores (and vice-versa). This system would make the difference between an okay candidate and a stellar candidate much more evident.
In fact, the best candidates would become outliers.
This inspiration is what lead to Gru.
Update: Gru’s design has changed significantly since this blog post. It has a browser based frontend, and uses Dgraph as backend. Over 200 candidates have taken Dgraph screening quiz using this new version of Gru.
Gru is an open-source, adaptive quiz system written entirely in Go. Gru server has a simple design and is very easy to setup. It doesn’t require maintaining a database. Questions and candidate information are stored and read from files. All the communication between the client and the server is encrypted.
Engineers collectively come up with questions from different areas and put them in a YAML formatted file. They tag them as easy, medium, hard. You can add more tags to define the field, for, e.g., concurrency, graph, sorting, searching, etc. Each question has it’s own positive and negative scores, generally determined based on their complexity, uniqueness, or statistical probability of anyone getting it right, etc. Here’s an example from our demo quiz.
- id: spacecraftmars
str: Which year did we first land a spacecraft on Mars?
correct: [spacecraftmars-1976]
opt:
- uid: spacecraftmars-2001
str: 2001
- uid: spacecraftmars-1976
str: 1976
- uid: spacecraftmars-1981
str: 1981
- uid: spacecraftmars-2013
str: 2013
positive: 5
negative: 2.5
tags: [medium,demo,mars]
Gru client runs on the command line and makes use of termui for displaying the questions. The score of the candidate is always visible to them, providing real-time feedback on how they are doing during the test.
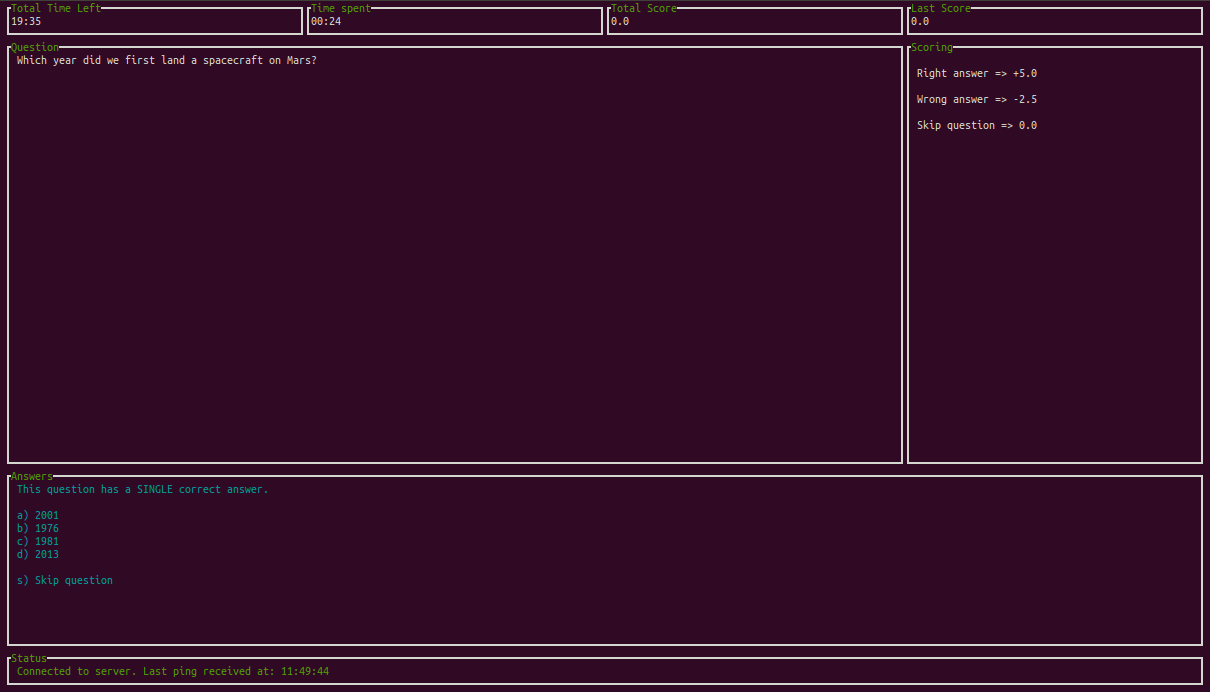
If you want to get your hands dirty, we have a server running with some demo questions. The binaries for both Gru server and Gru client are released here. To take the demo quiz, download the gruclient binary for your platform and just run it. It would automatically connect to our Gru server, and test your knowledge about humankind’s space missions.
You could start running Gru at your company for free. For more details on how Gru works and how to host it, please visit Gru wiki.
Gru is a work in progress. Let us know what you think about it and how we could improve it on discuss.dgraph.io. If you find any issues with Gru, file a bug. Hope you like Gru and looking forward to a world with better technical interviews.
Gru Links
Other posts I’ve written about interview process:

