
GraphQL Sorting: A Beginner's Guide
Sorting data in GraphQL is a powerful tool that enhances the usability and performance of your applicatio ...
Learn more
Everyone wants to build the next unicorn of a modern application. Whether you’re building a prototype or expanding your existing product, the goal is to reach a massive user base. However, that journey can include a range of hurdles that many developers and technologists neglect or forget about, particularly when it comes to scaling a database.
As the core component of most modern architectures, databases have a tremendous responsibility. Database performance bottlenecks can make or break a product. The effect of such issues is even more apparent as your application begins to scale, potentially leading to poor user experience and a loss of users. Application performance is a key factor in the success of giants of the tech arena like Amazon, Facebook, and Google, that proved performance at mega-scale is possible. This is the benchmark for all modern applications: faster and unrestricted access to data.
To do that, since the market is more or less always unpredictable, you have to ensure that your products can scale as you’re growing. Scaling a system can be very complex and involve many different facets. Complexity mainly depends on the architecture of your system and the underlying technologies. Part of the equation likely involves scaling your database to increase resources to serve the increasing demand. As a fundamental part of most modern applications, there are many ways that you could begin to scale your database functionalities.
This article discusses one of the most common and modern options for scaling: database sharding. The idea of database sharding has become a cornerstone of modern database architecture, especially at scale. Since Dgraph is a graph database, we’re going to look at how a graph database can distribute its graphs across several machines to achieve horizontal scalability. We will also look at some methods of doing so that aim to mitigate limitations on the performance of the database. Lastly, we’re going to dive a bit deeper into Dgraph’s approach to sharding data and how it addresses problems seen in existing solutions.
Let’s look at the topics we’re going to explore:
If you’d prefer a video primer on sharding, here is our five-minute video on what sharding is that’ll give you a brief introduction. You can watch the video and then start reading from the section Horizontally scaling graph databases.
Sharding is a way of scaling horizontally. A sharded database architecture splits a large database into several smaller databases. Each smaller component is called a shard.
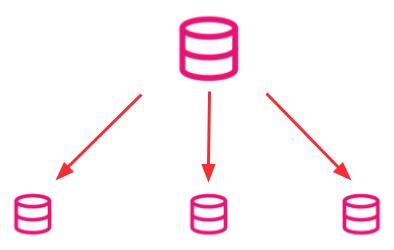
Instead of storing all data on a single server, we distribute it across several servers. This reduces the load on a single resource and instead distributes it equally across all the servers. This allows us to serve more requests and traffic from the growing number of customers while maintaining performance.
You’ve likely seen this approach before in other systems where application load is spread across multiple servers. In regards to databases, this approach falls under a distributed database architecture, where the aim is to spread the total load across multiple database instances.
Sharding is not the only way of scaling; there’s vertical scaling at the other end of the spectrum*.* With this approach, instead of buying new machines, you increase the operational capacity of your single server by upgrading its hardware parts.
Vertical scaling may seem like a simpler alternative but it’s not a pragmatic solution. In the long run, you’ll soon hit the ceiling beyond which you can’t upgrade your machine anymore.
You could always get more servers and use them as resource pools. There’s a limit to how many upgrades you can apply to a machine, but no limit on purchasing newer and more modern machines. This makes more sense and offers greater flexibility than simply continuing to bulk up a single machine until the ceiling is reached.
Financially speaking, setting up a distributed, sharded architecture for your needs can be high at first due to the cost of setting up multiple database instances. This entry cost is easily forgiven though once the solution is in place. Scaling through a sharding approach lessens costs in the long term compared to other scaling strategies. As you can easily see, your long-term business goals will benefit largely from choosing a strategy that focuses on database sharding and provides durability in your growth.
Databases that back up large applications and important infrastructure have to consider these facts before choosing a solution. Oftentimes, it might make sense to adopt multiple solutions, sharding being one of them. Depending on your needs in terms of performance, cost, and ease of maintenance, the approach you take to scalability will likely be a customized one, potentially utilizing many different methods and approaches bundled together.
Dgraph is a native-GraphQL, open-source graph database. It stores and represents data using graph structures. Even though it is a NoSQL approach to data storage, it does differ from other NoSQL approaches including document-oriented types like MongoDB. This also means that graph databases may take a different approach to sharding data. To better understand this, it makes sense to understand how data is stored in Dgraph and other graph databases.
A graph is an abstract data structure to represent data. It consists of nodes and edges. The nodes of a graph have properties associated with them, representing various data objects. An edge also contains data by indicating the relationship between two nodes. In Dgraph, both node properties and edges are called predicates.
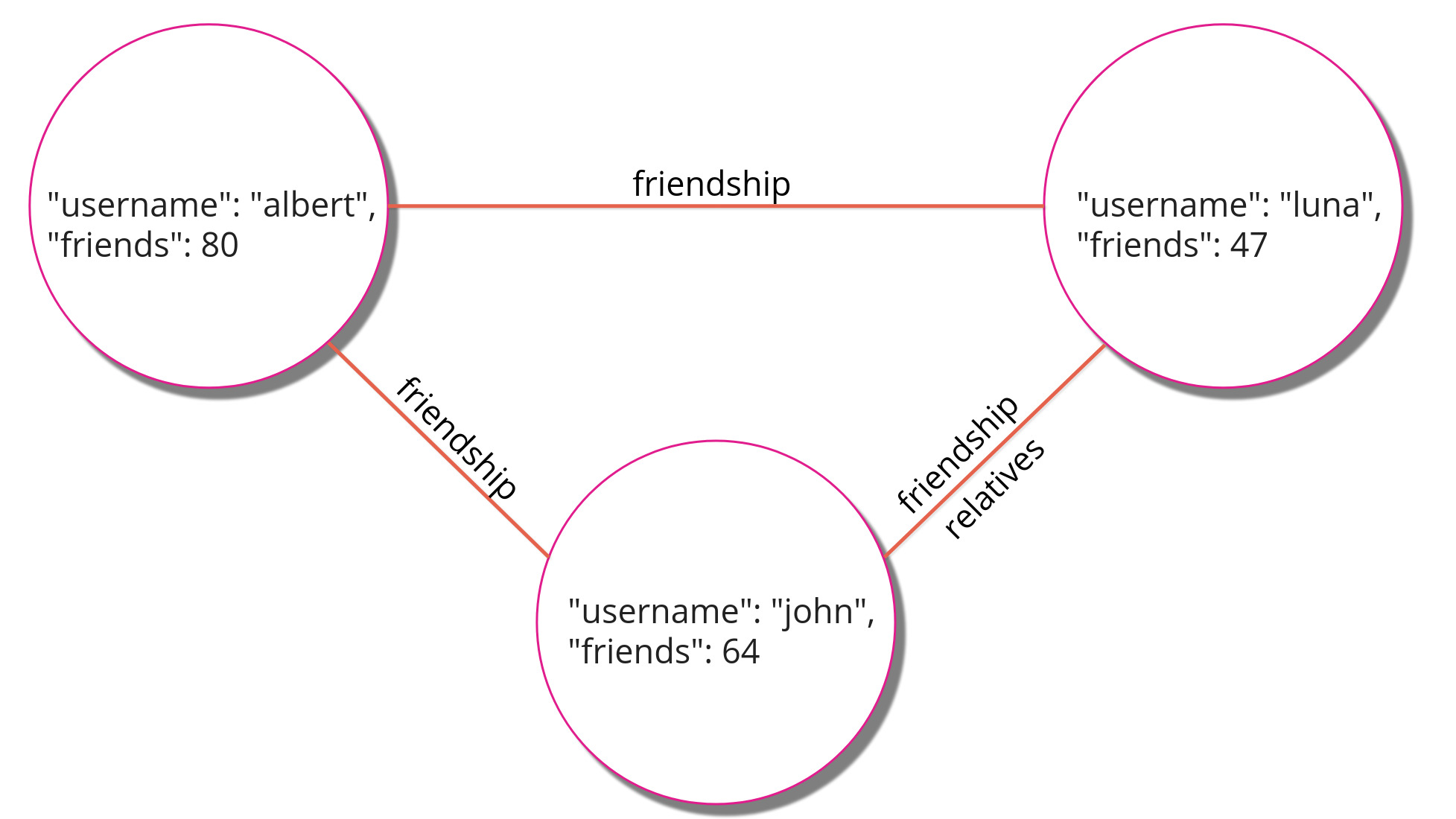
There’s also a short introductory video on what graphs are that you can check out below:
Before we get into how Dgraph implements sharding, let’s try to understand the architecture of a Dgraph cluster.
A Dgraph cluster consists of two nodes:
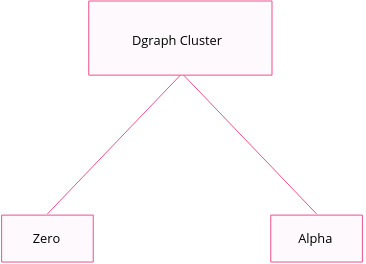
Each has a different set of responsibilities that they carry out.
You might be familiar with the word “cluster” in the sense that it means several computers or servers connected acting as a single system. But a Dgraph cluster means a collection of Dgraph instances, an instance being a node, i.e. either a Zero or an Alpha. A cluster can contain multiple Alphas and Zeros, but you need a minimum of one Zero and one Alpha to run a cluster.
Each Zero and Alpha belong to a group and each group may contain multiple Zeros and Alphas. The following figure shows three Alpha groups monitored by a Zero group, each containing multiple instances.
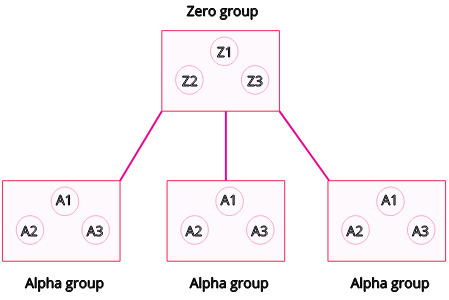
Dgraph Alpha hosts the data in the form of predicates. A predicate represents the relationship that exists between two vertices of a graph, but it could also mean a distinct property of a vertex. As we’ll soon discuss, a predicate is used to group some data to form a shard.
Each group of Alphas serves exactly one set of these predicates. If a group has more than one Alpha, data is replicated among them to ensure high availability.
Dgraph Zero is in charge of controlling a cluster and performing related tasks. It stores information like IP addresses for communication within the cluster, the amount of data each Alpha is serving, etc. When new data arrives, Zero determines which group would serve that data, using the information it has on different Alpha groups.
Zero periodically monitors the balance of data among groups. In case of an imbalance, Zero would try to move some predicates to a group having lower disk usage.
Likewise, when a new Alpha joins the cluster, Zero can either tell it to join an existing group or form a new one.
When thinking about sharding a highly connected graph, as seen in social networking platforms such as Facebook and Twitter, you can think about various strategies. One often-used approach is to randomly choose users (nodes or vertices of the graph) and assign them to shards. Being a highly connected data structure, that would mean we’re tearing apart the connections and sacrificing that connected nature in favor of scaling. This is the reality whenever you move towards sharded data.
Also from a performance viewpoint, this approach has some obvious pitfalls. The “random sharding” model introduces randomness in graph traversal too, meaning to get the appropriate data for a single query, there might be multiple network hops from one server to another for a single traversal, resulting in latency issues.
For multiple traversals within a single query, the number of network calls also increases as you add more shards. This is called the join-depth problem, where for a single join you need to do more network calls. These network calls also contain data, so the performance gets quite unpredictable.
Sharding by entities also introduces the fan-out problem. Suppose you have some survey data on developers, sharded by entities, containing information such as their stack, editor of choice, and so on. You want to find developers in sf who use vim.
Let’s look at the steps that take place to satisfy this query:
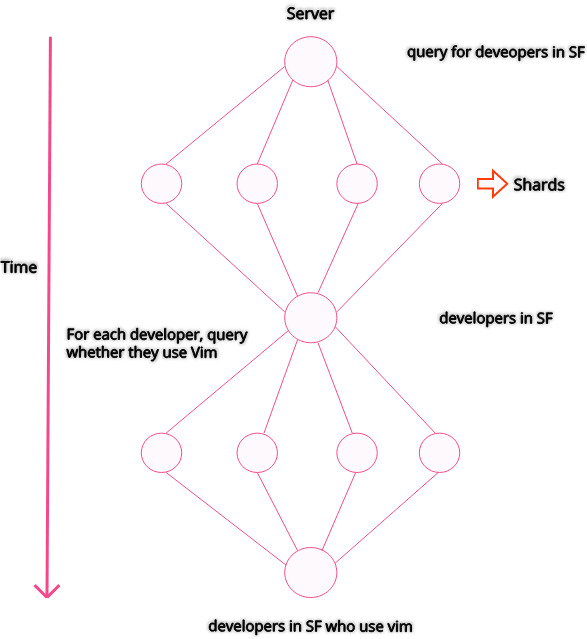
Applying more filters or constraints means more network calls to each shard. Making calls to multiple servers in a distributed, sharded system would add up to the total delay seen by a client that’s making the request.
Can we do better so that we can retain, as much as possible, the original shape of the graph and achieve a better performance?
The answer lies right there, in the nature of a social network graph—its connectedness. We can easily explore patterns in the graph, patterns that are correlated, identify closely connected data, and assign them to each shard. For example, we could shard by location, where each shard contains data for a specific region of the world and its users.
This would reduce the number of shards the service needs to access for a query and thus improve latency. We’ll see faster data fetching and efficient personalization of user-profiles suited to the users’ interests given that this model tries to retain the relationships each user has; this is a general element in almost all social media applications.
Dgraph chose a different approach for sharding to address the problems in prevalent sharding solutions, such as the arbitrary-depth join problem and fan-out problems.
Instead of entities, Dgraph shards data by predicates. Data with the same predicates are grouped to form a shard.
Dgraph’s smallest unit of data or record that it stores is called a triple. A triple is expressed as a subject-predicate-object, or subject-predicate-value, hence the name triple.
The subject represents an entity (a node in the graph), the predicate is a relationship, and the object is another node. The object can also be a primitive data value, like Int, Float, String, etc.
A shard is formed by taking the records having the same predicates. For example, consider the following simple GraphQL schema representing a data graph of some developer data:
type Tool {
id: ID!
name: String!
}
type Developer {
id: ID!
tools: [Tool!]
lives-in: String!
}
For the Tool type, we can have some sample data like the following:
{
id: 0x01, name: “GraphQL”,
id: 0x02, name: “Vim”,
id: 0x03, name: “Dgraph”,
id: 0x04, name: “Emacs”,
...
}
So data for a Developer could look like the following:
{
id: 0xab,
tools: [{id: 0x02, name: “Vim”}, {id: 0x03, name: “Dgraph”}]
lives-in: “SF”
}
Dgraph uses its own key-value store Badger to store data. Within each shard, we have the same predicate for a bunch of subjects and objects. Dgraph converts them into one key-value pair and stores it in Badger. For each predicate and its corresponding subjects and objects, there’s a single key-value pair.
Notice the following records in RDF triple format (subject-predicate-object) where you have the tools predicate and some corresponding data:
<0xab> <tools> <0x02> .
<0xab> <tools> <0x03> .
...
This is a sample for only one entity. Like this, for each entity (in our case a Developer), the respective values for that entity are grouped to form a key-value pair in the following way:
key = <tools, 0xab> .
value = <0x02, 0x03, ...> .
You can read it like this: The tools predicate of the Developer with ID 0xab has the values0x02,0x03…
There are going to be two shards in our case, one for each predicate tools and lives-in, served by two Alphas:
AlphaGroupOne:
ShardOne:
key = <tools, 0xab>
value = <0x02, 0x03, ...>
key = <tools, 0xbc> .
value = <0x01, 0x03, ...>
...
AlphaGroupTwo:
ShardTwo:
key = <lives-in, 0xab>
value = <SF>
key = <lives-in, 0xbc>
value = <NYC>
...
Let’s consider the previous query of finding developers who live in SF and use Vim. In Dgraph, the following steps would take place:
We can already spot some improvements:
One issue that might arise is large predicates residing in a single server, resulting in heavily skewed disk usage and imbalance across data shards. As mentioned before, Zero keeps an eye on it across the servers. For large predicates, Zero can further split them up and redistribute them to maintain a healthy balance.
Sharding by predicates greatly improves latency in real-world systems and allows arbitrary-depth joins, which is flexible and gives a predictable performance. With Dgraph, you can scale effortlessly and efficiently, without worrying about the safety of your data.
Achieving horizontal scalability with Dgraph is easy. It’s baked into Dgraph and it shards the data automatically based on the appropriate cluster setup. Dgraph puts you in fine-tuned control over your storage setup, taking care of everything else.
By default, when you’re trying Dgraph out on your local machine, there’s just one Alpha group and all the predicates live there. There’s no sharding since it’s only one Alpha group running on one server. This is a basic 2-node-cluster setup, consisting of one Zero and one Alpha.
When you want a sharded database, you need to set up more machines and run instances on each of them. For example, say you want to divide your entire data into two shards and have Dgraph serve them. Then you can set up a 3-node cluster, consisting of 2 Alphas (two groups, each serving one shard) and one Zero. It’s that easy.
If you want some sample cluster patterns and how to set them up, refer to our Production Checklist docs and the immediate sections following Terminology. It contains everything you might need to know for running a production-level Dgraph cluster.
In case you hit a snafu or have a question, feel free to open a thread on our community forum.
Dgraph benefits from several sources of modern and original research that make it a robust graph database platform able to tackle complex market requirements. The “data era” is constantly mutating and getting bigger, and Dgraph promises a distributed, scalable and effective solution in harnessing that data for your needs.
If you want to know more about Dgraph’s technology, download the Dgraph research paper that discusses all the technical aspects of designing a distributed and consistently performant graph database for real-world applications.
If you want to jump right in, check out Dgraph Cloud. You can get started for free and begin building your applications without any worries about manually handling database management.
