
GraphQL Sorting: A Beginner's Guide
Sorting data in GraphQL is a powerful tool that enhances the usability and performance of your applicatio ...
Learn more

This blog takes you through converting a simple dataset and into a graph. Just follow these steps in Dgraph to express your dataset as an API. By adopting a minimalistic approach throughout this conversion process, you’ll build a strong understanding of the significance, and uniqueness, of Dgraph’s capabilities.
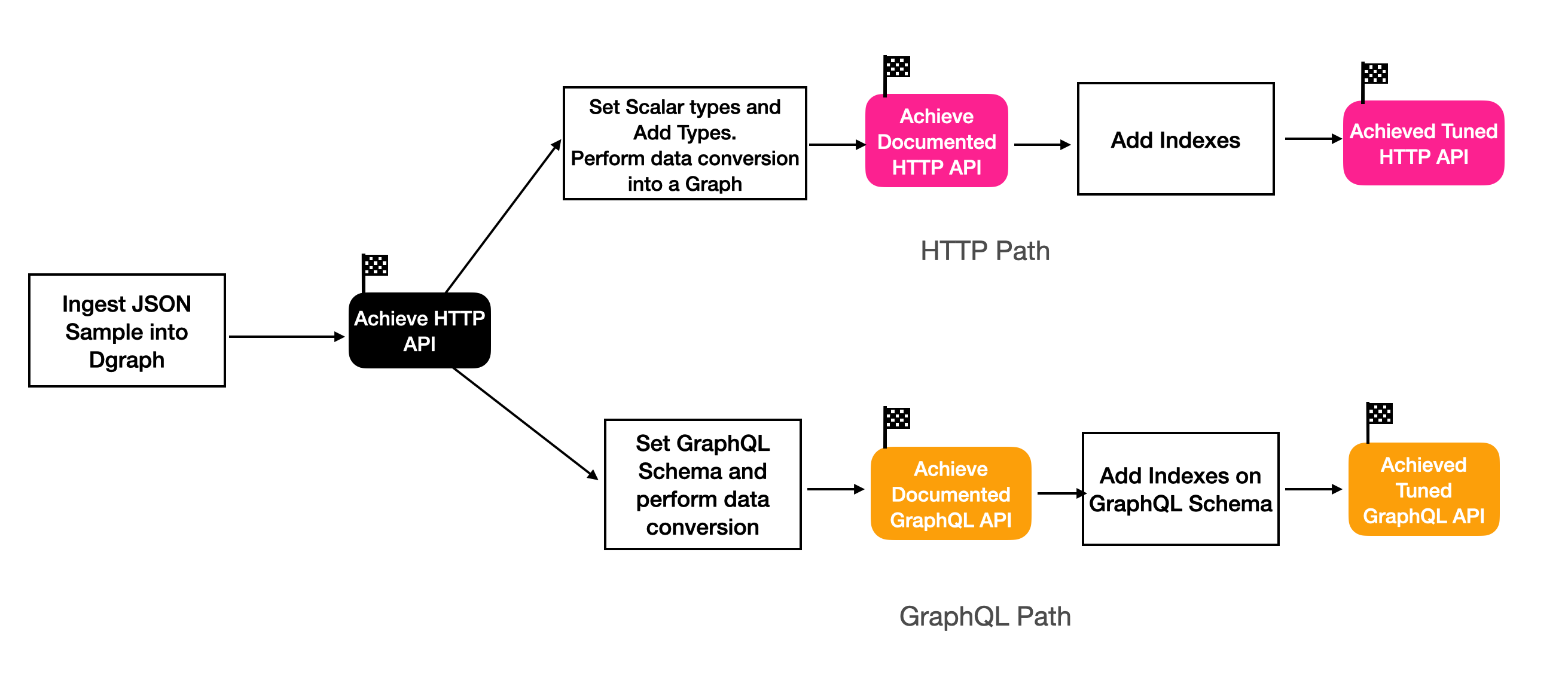
In order to maintain a minimalistic approach, we will follow a guided path covering HTTP and GraphQL protocols with focused changes to data and schema, and flag milestones in our journey towards an expressive and performant API. While this blog does not cover the gRPC protocol, you can consider the gRPC guided path to be very similar to the HTTP path.
Let’s get started!
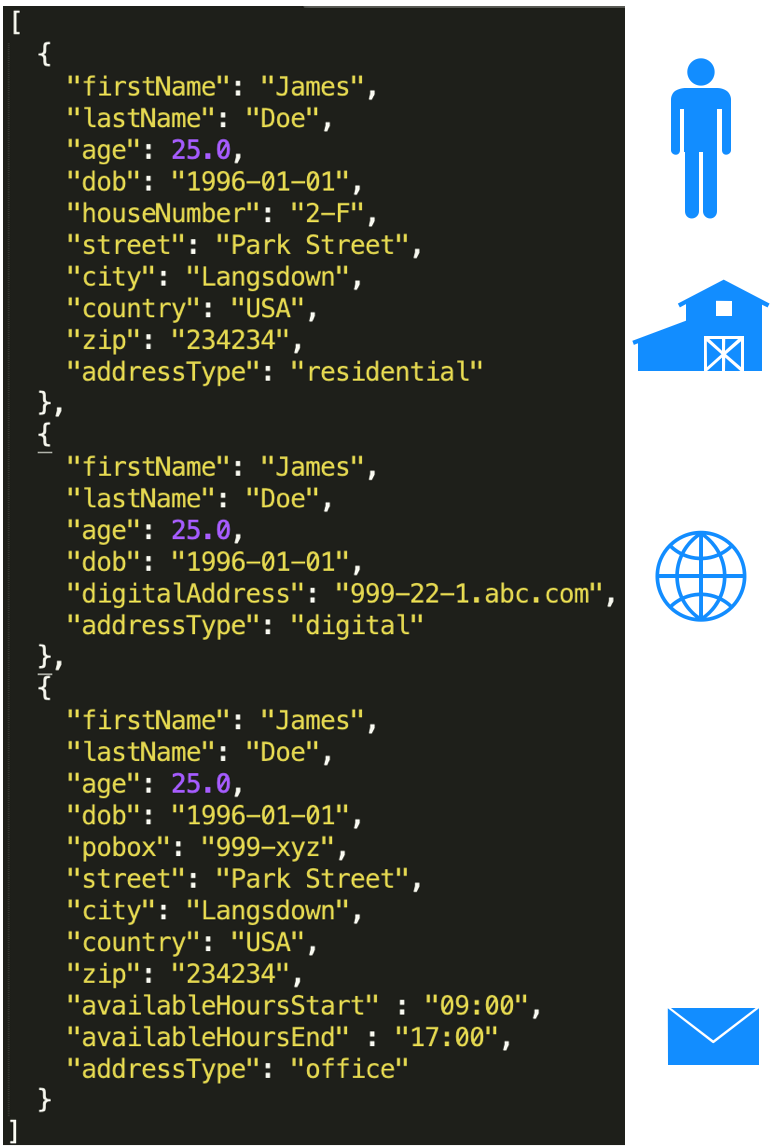
This dataset consists of attributes of a person such as name and age, as well as several ways to contact the person. The person has multiple addresses, including residential, PO Box, and a virtual address. As often happens, this dataset is made available in a flattened JSON format with certain core attributes of a person repeated with a paired address information. We will load the data as-is. We will run a Live Loader using the following command and load this JSON into Dgraph.
./dgraph live -f /Users/anand/Documents/data-to-api/sample-dataset.json
Running transaction with dgraph endpoint: 127.0.0.1:9080
Found 1 data file(s) to process
Processing data file "/Users/anand/Documents/data-to-api/sample-dataset.json"
Number of TXs run : 1
Number of N-Quads processed : 28
Time spent : 609.348373ms
N-Quads processed per second : 28
curl -H "Content-Type: application/dql" -X POST localhost:8080/query -d $'
{
qPerson(func: has(firstName)) {
firstName
lastName
age
dob
houseNumber
street
city
country
zip
digitalAddress
pobox
availableHoursStart
availableHoursEnd
addressType
}
}'

Dgraph supports an HTTP API out of the box. Even at this very early juncture in our journey towards an expressive API, we do have an API available to explore the data that we just loaded. Dgraph ships an HTTP endpoint, available at http://<alpha-address>:8080/query, that can be used for this exploration. You can use a cURL command to query and view the nodes as shown. Your clients can start using this features to explore Dgraph right from the command line. This HTTP API supports queries, mutations as well as database schema alterations.

“Ratel”, a graph visualization app provided by Dgraph, helps visualize the persona and address data we loaded.
{
qGroup1(func: has(firstName)) @groupby(firstName, lastName, age, dob){
count(uid)
}
qGroup2(func: has(addressType)) @groupby(addressType){
count(uid)
}
}

The @groupby queries in Dgraph is a good way to explore and identify certain trends or grouping in Dgraph. When we run a DQL query with a grouping of firstName, lastName, age and dob, (as Group 1) we find three nodes. By a simple visual inspection, we determine that these are duplicates. We also find that we have a single residential, office and a digital address (Group 2).
Now you have data loaded, plus an available API. This is already good progress and you can start thinking of some use cases, like log analytics, that already benefit from this feature. You have noticed that there are duplicate nodes in the Dgraph, and you might want to resolve those into a unique node. You also may want to unify the address links into a single new predicate ‘hasAddress’. Transforming raw data into a well-structured graph facilitates better data management, plus gives a smoother API experience.
The following steps are involved: a) transforming the identified groups (Person, Addresses) into unique nodes. b) creating edges or links that connect these nodes appropriately c) assigning a type to each node
upsert{
query{
#1
var(func: has(firstName)) {
f as firstName
l as lastName
d as dob
a as age
}
unique(){
fmax as max(val(f))
lmax as max(val(l))
dmax as max(val(d))
amax as max(val(a))
}
#2
addresses as var(func: has(addressType))
}
mutation{
#3
set{
_:newPerson <firstName> val(fmax) .
_:newPerson <lastName> val(lmax) .
_:newPerson <dob> val(dmax) .
_:newPerson <age> val(amax) .
_:newPerson <hasAddress> uid(addresses) .
_:newPerson <dgraph.type> "Person" .
uid(addresses) <dgraph.type> "Address" .
}
delete{
uid(addresses) <firstName> * .
uid(addresses) <lastName> * .
uid(addresses) <dob> * .
uid(addresses) <age> * .
}
}
}
The upsert statement acts like a find and update actor. At (1) an aggregated view of the person is created. This assists in creating a single set of attributes from the three duplicates. At (2), all the associated addresses are picked. At (3), a new person node is created with the appropriate attributes for firstName, lastName, dob, and age. The addresses and the new person node are given a dgraph.type, effectively labeling them as Address and Person respectively. We have repurposed the original data as address nodes, and the person-related data has been deleted.
Please note the newly created person is linked with the address using the hasAddress predicate. In the steps we have taken so far, this is the unique action that begins our Graph journey. This humble hasAddress link is a simple declaration that two nodes are linked by a certain relationship. Dgraph makes no conditions on what these two nodes need to be, or where they need to lie in the Graph database. These two nodes can be any two nodes in the graph (both nodes can be the same one as well). When the database scales to millions of nodes, this capability of arbitrarily linking any two nodes brings immense flexibility in transforming your data into the shape of the graph you need. Imagine any type of relationship you want to store, including a product and its variants, an event and its attendees, a device and its measurements and so on; Dgraph will use the same approach to manage the associated graph. This approach is preserved even when Dgraph scales to multiple nodes or undergoes sharding.
{
qPerson(func: type(Person)) {
firstName
lastName
age
dob
hasAddress{
houseNumber
street
city
country
zip
digitalAddress
pobox
availableHoursStart
availableHoursEnd
addressType
}
}
}

You can now explore the transformed graph. The data associated with the ingested JSON objects has been merged into a new Person node. The addresses are appropriately linked on the hasAddress predicate and is available as part of the graph.

You can now make the transformed graph queryable via an HTTP API. Your clients can now see that person and related address is represented in an appropriately nested format, and indeed, reflects the graph you organized in the Dgraph database.
While your graph is now available via HTTP, you would like your clients to have a better understanding of what is available in the database. As a first step, you can use the schema query as shown to explore the attributes stored in the graph.
curl -H "Content-Type: application/dql" -X POST localhost:8080/query -d $'
schema{}
' | jq
If you recollect, we have set the types Person and Address on our nodes. We want to say that a Person is associated with the attributes firstName, lastName, age and dob, while the addresses have typical physical address attributes as well as poboxes, digital addresses etc. In order to express this, let’s alter the database schema via Ratel and set the additional schema as shown below.
type <Person> {
age
firstName
hasAddress
lastName
dob
}

When clients issue a schema request now, they will be able to observe that firstName, lastName, dob, and age shown above are available as part of type Person. With this understanding, the clients can now send a subsequent query that explicitly asks for firstName, lastName, dob, and age. A similar approach can be applied for the address types as well.

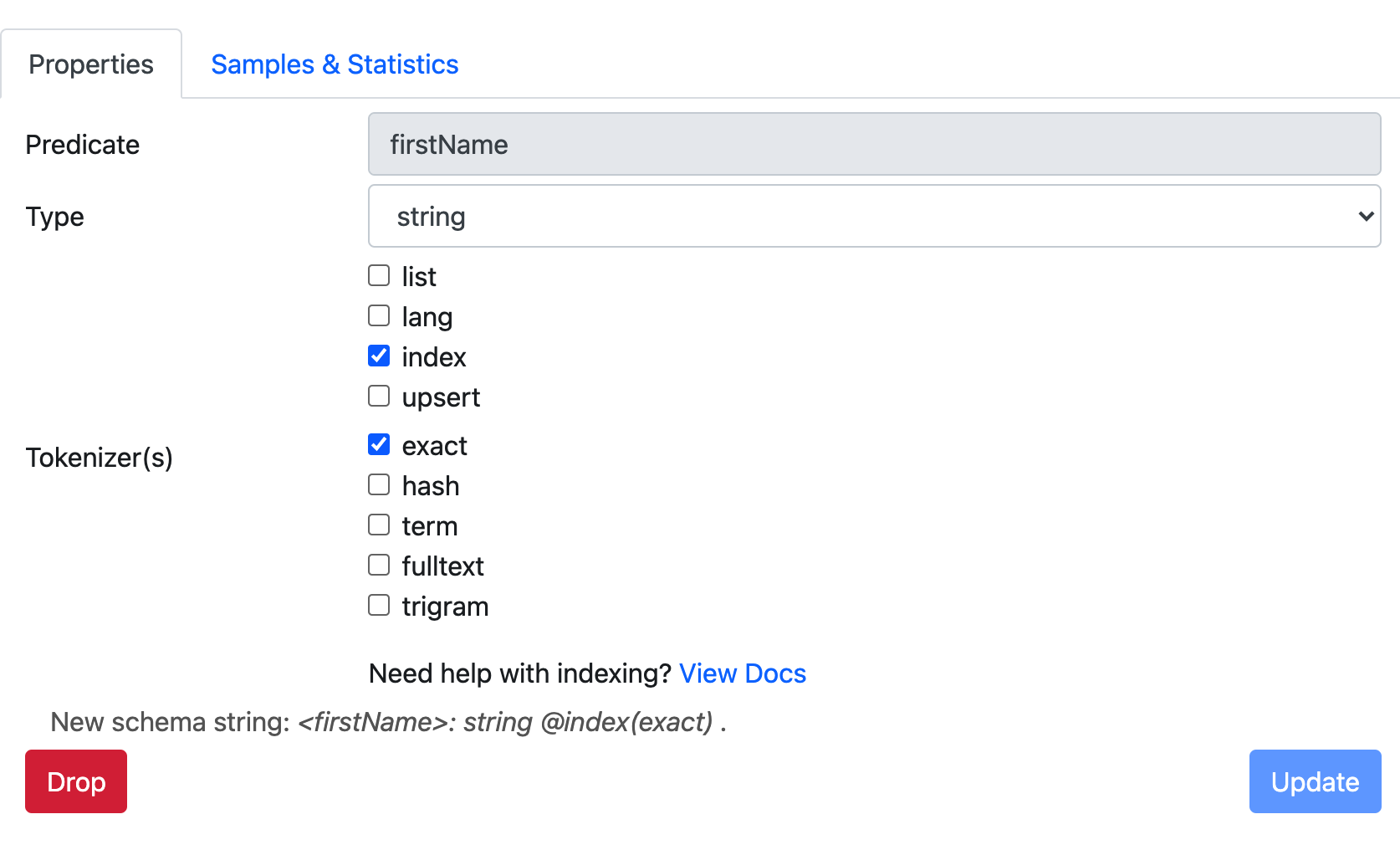
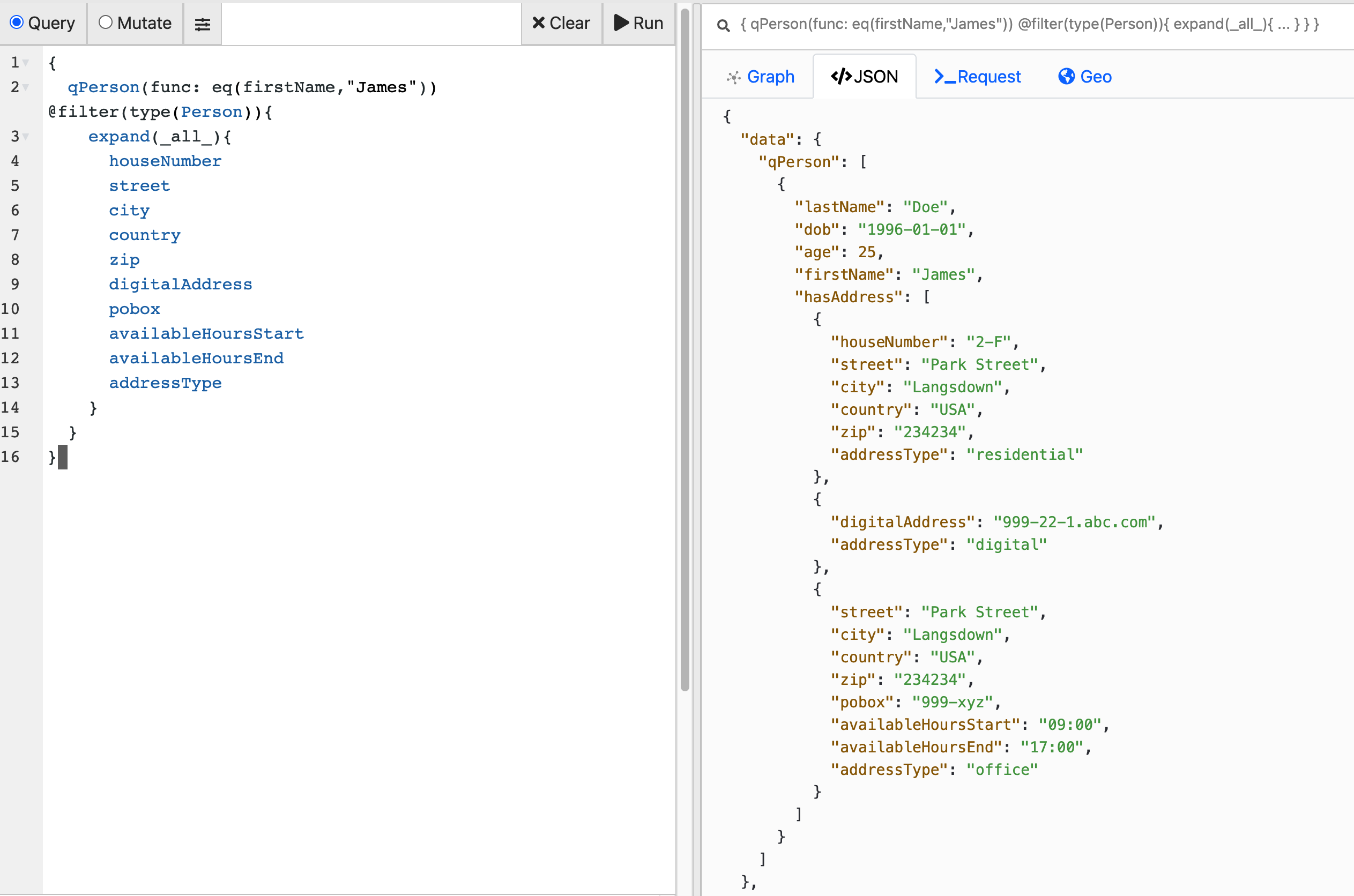
Since our graph is currently small, we have been able to traverse it pretty quickly. However, as the graph scales to millions of nodes, you will need to add indexes for a better API experience. Let’s set the type of firstName as string and add an exact index.
You can then fire a query with an equality check (eq) in the root function (identified by func:). The client can experiment with different indexes and construct the queries as per their respective latency needs.

Dgraph also supports GraphQL API. As a web API, GraphQL is similar to HTTP in terms of its capabilities of being able to exchange schema and data over an API. However, GraphQL is a unique API standard with commonly agreed and published conventions of describing, querying, and mutating data. GraphQL has a great ecosystem with several GraphQL clients that can be readily plugged into a GraphQL API.
So, let’s get back to the drawing board and start our journey with GraphQL. You can clear out the database and live load the data again as mentioned in a previous step.
type Customer {
id: ID!
firstName: String
lastName: String
dob: DateTime
age: Float
hasAddress: [CustomerAddress]
}
type CustomerAddress{
id: ID!
houseNumber: String
street: String
city: String
country: String
zip: String
digitalAddress: String
pobox: String
availableHoursStart: String
availableHoursEnd: String
addressType: String
}
You can then use a cURL command to set the schema shown above. Dgraph will convert this GraphQL schema into a GraphQL API, with specific operations for query and mutations. Based on our data, you can create the two types, Customer and CustomerAddress.
upsert{
query{
var(func: has(firstName)) {
f as firstName
l as lastName
d as dob
a as age
}
unique(){
fmax as max(val(f))
lmax as max(val(l))
dmax as max(val(d))
amax as max(val(a))
}
}
mutation{
set{
_:newPerson <Customer.firstName> val(fmax) .
_:newPerson <Customer.lastName> val(lmax) .
_:newPerson <Customer.dob> val(dmax) .
_:newPerson <Customer.age> val(amax) .
_:newPerson <dgraph.type> "Customer" .
}
}
}
You can write up an upsert mutation to convert the data related to a person into a Customer as shown. You can convert the address records in a similar manner.
 Query Documentation
Query Documentation
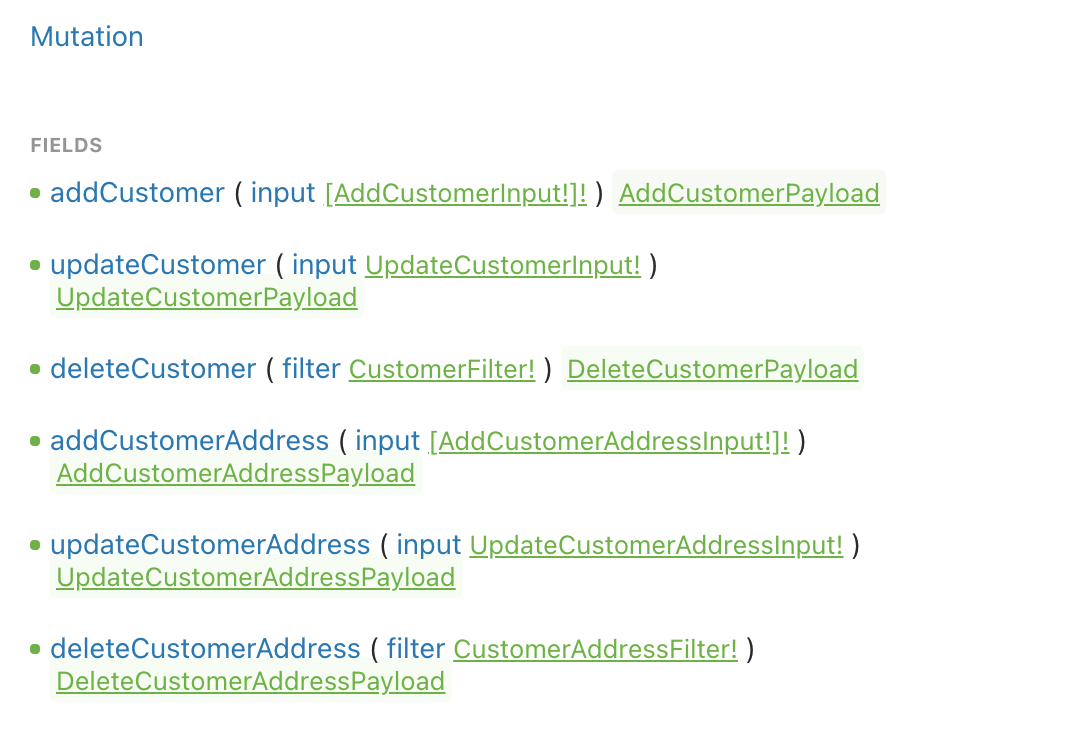 Mutation Documentation
Mutation Documentation
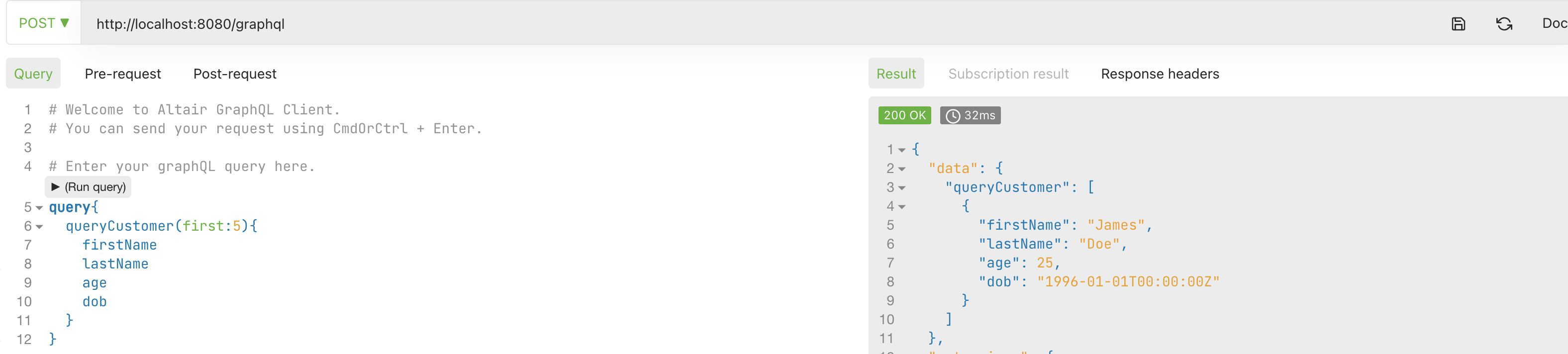 GraphQL Query
GraphQL Query
You can use GraphQL clients like Altair or GraphQL explorer to check the query and mutation API options available for a client as shown. This allows the client to build an understanding of the available options. When building and testing out GraphQL requests, most GraphQL clients can flag errors on the client side itself. This helps clients to consume the API smoothly and coherently.

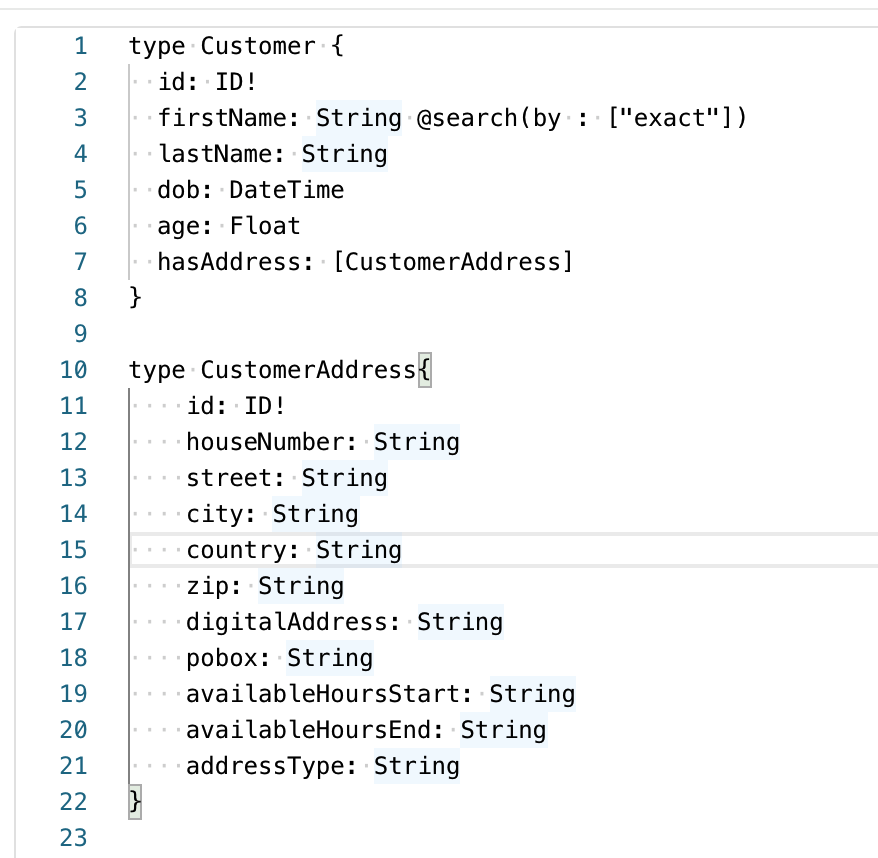 Adding an Index to a Type Definition
Adding an Index to a Type Definition
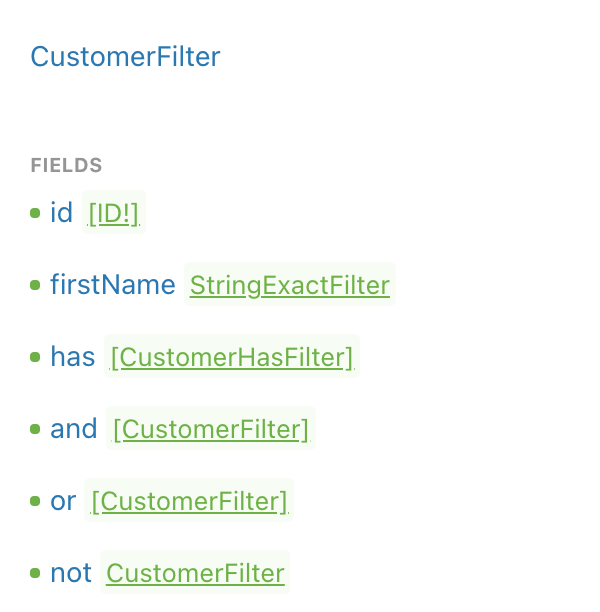 GraphQL Filter
GraphQL Filter
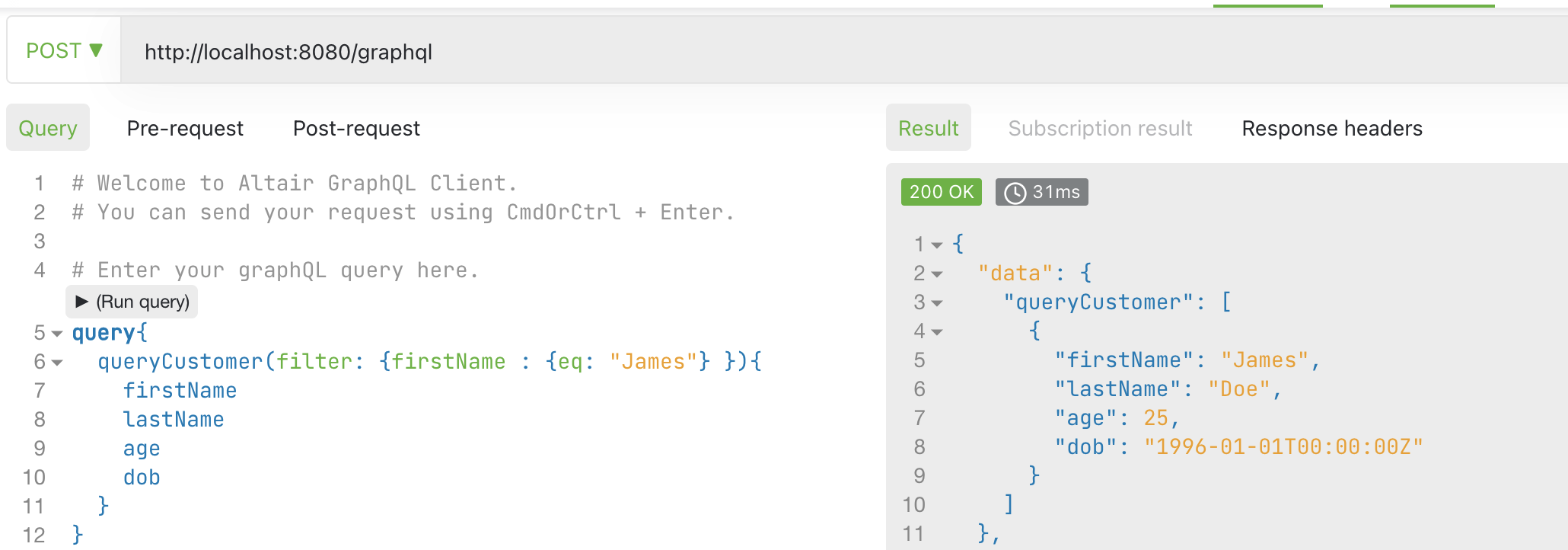 GraphQL Query using an Index
GraphQL Query using an Index
Dgraph’s GraphQL service also supports indexes to make it easy for clients to find the information they are looking for. Let’s assume your client wants to search by the firstName of a Customer. In this case, we can add the @search directive with the exact parameter. Upon deployment, the GraphQL API yields a CustomerFilter object which supports an eq operation. You can retrieve data for “James” as shown.

In this blog, you started working with a small dataset and loaded into Dgraph. You took focused actions including transforming data as well as making changes to schema. As you took those actions, you noted the availability of newer features on the APIs across GraphQL as well as simple HTTP APIs. You also explored how the rich data structures you have created in Dgraph can be communicated to your clients. Having a strong understanding of the actions you took here will help you tackle your next use case with accuracy and speed. Do chime in with your thoughts on what you want to build next!
Interested in getting started with Dgraph? You can get started here. Please say hello to our community here; we will be glad to help you in your journey!
