
Cracking DQL: Variable Propagation
Variable Propagation in Algorithms Variable propagation is a powerful technique in programming and algori ...
Learn more

By combining Dgraph with a vector database, not only can you find the needle in the haystack, but also how much it costs, when it was lost, and who is actively looking for it!
Dgraph interviewed Knights Analytics to learn from their experience building products that combine LLMs and Dgraph. They shared their strategies for creating intelligent and adaptive search by augmenting graph traversals with vector embeddings.
Fuzzy matching has always been a big topic in search and discovery tasks, and is often at odds with structured databases who often rely on keys and concrete connections across data to surface aggregations and insights.
Dgraph stores data as you think about it: a network of interconnected pieces of information, a Graph! It excels at handling “relationships” among your data. On the other hand LLMs offer flexibility and can convert text into “embeddings” - numerical vectors representing the semantic meaning of a chunk of text or an entire document.
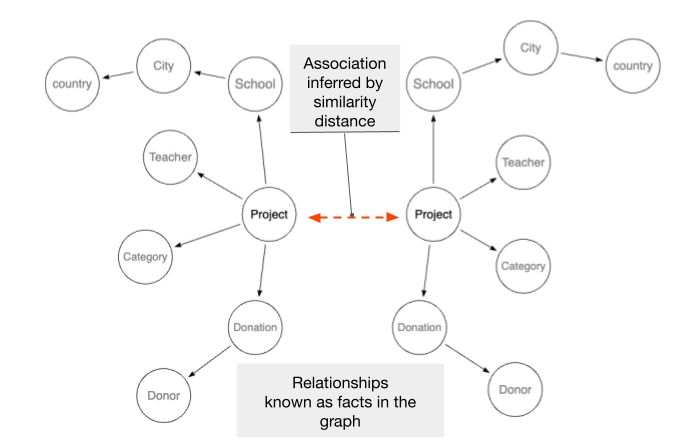
In this blog we will show how you can combine the power and intelligence of LLMs with the structured, highly navigable related data stored in Dgraph to create a powerful “Association Graph” with association links, into the unique GraphQL + Graph Database technology of Dgraph. The result is a new kind of graph that goes beyond “knowledge” and into “associations”.
In a recent post we explored how to use word embeddings in Dgraph to make your data smarter and implement automatic classification.
In our use case, projects are associated to categories using word embeddings.
We are now extending this approach to include “associations” based on semantic similarities and implement semantic search.
The embedding generated by OpenAI API for a given text, is a vector of floating point numbers. The vector is of dimension 1536 when using the model text-embedding-ada-002.
The distance between two vectors happens to measure a semantic proximity between two texts.
A vector database is the perfect technology to store vectors and search similar vectors using distance computation.
We will use Qdrant, who presents itself as “a vector similarity search engine”.
The combination of Dgraph and a vector search engine is a very effective and flexible solution:
This is a good approach to mix reliable and curated information (your knowledge graph) with AI inferred, or guessed relationships (associations).
Dgraph can also store metadata about a relationship like a similarity score or the AI model used to infer it, providing a full data lineage.
If you want to try this out yourself, the easiest way to get Dgraph up and running is to signup for Dgraph Cloud and launch a free backend.
Let’s stay with our Projects from the data classification post.
Dgraph automatically generates get, query, aggregate, add, update, and delete operations for every type in your GraphQL schema.
It also allows you to define custom queries and mutations.
In our schema, we are defining semSearchProject query. The @lambda directive instructs Dgraph to use a custom logic.
type Project @lambdaOnMutate(add: true, update: false, delete: false) {
id: ID!
title: String! @search(by: [term])
grade: String @search(by: [hash])
category: Category
score: Float
}
type Category @lambdaOnMutate(add: true, update: false, delete: false) {
id: ID!
name: String!
}
type Query {
semSearchProjects(title: String!, first: Int!): [Project] @lambda
}
We have already used the directive @lambdaOnMutate to trigger the logic of computing the embeddings for projects title and catgories name.
Copy this schema in the Dgraph Cloud dashboard and deploy it.
We are using OpenAI API to compute the embeddings.
Keep a copy of the key as we will use it to invoke OpenAI REST API from Dgraph.
We are using Qdrant as our vector similarity search engine.
Keep a copy of the cluster URL and API key as we will use them to invoke Qdrant REST API from Dgraph.
Create a collection named dgraph that will hosts our vectors.
You need to specify the vectors size: OpenAI embeddings vectors for text-embedding-ada-002 model are of size 1536.
You also need to specify the distance function. Let’s use dot product.
curl -X PUT '{{Qdrant-cluster-endpoint}}/collections/dgraph' \
-H 'api-key: {{Qdrant-key}}' \
-H 'Content-Type: application/json' \
--data-raw '{
"vectors": {
"size": 1536,
"distance": "Dot"
}
}'
Every time a Category or Project is created,
We can simplify the logic that we have used in the previous post and use the vector database API to search for similar vectors. The vectors ID returned correspond to Dgraph node UIDs, from there we can query / mutate the Dgraph data as needed.
ProjectProject objects to the GraphQL operationDgraph lambda provides a way to write custom logic in JavaScript, integrate it with your GraphQL schema, and execute it using the GraphQL API.
The following section of the GraphQL schema is defining a custom query semSearchProjects:
type Query {
semSearchProjects(title: String!, first: Int!): [Project] @lambda
}
We are using @lambda directive to indicate a lambda query.
Here is the complete code of our lambda.
const OPENAI_KEY = "<---- YOUR OPENAI API KEY ---->"
const QDRANT_CLUSTER_URL = "<---- YOUR QDRANT CLUSTER URL ---->"
const QDRANT_KEY = "<---- YOUR QDRANT KEY ---->"
const QDRANT_COLLECTION = "dgraph"
async function saveVector(nodetype,uid,vec) {
let url = QDRANT_CLUSTER_URL+"/collections/"+QDRANT_COLLECTION+"/points?wait=true";
let body = `{ "points": [ { "id":${BigInt(uid).toString()}, "vector":[${vec}], "payload": { "type": "${nodetype}"} } ] }`
return fetch(url,{
method: "PUT",
headers: {
"Content-Type": "application/json",
"api-key": QDRANT_KEY
},
body: body
})
// use response.status and await response.json() if needed
}
async function searchSimilarity(vec,nodetype,limit=10) {
data = []
try {
let url = QDRANT_CLUSTER_URL+"/collections/"+QDRANT_COLLECTION+"/points/search?wait=true";
let body = `{
"vector" : [${vec}],
"filter" : {
"must" : [ {
"key":"type",
"match": {
"value":"${nodetype}"
}
}]
},
"limit":${limit}
}`
let response = await fetch(url,{
method: "POST",
headers: {
"Content-Type": "application/json",
"api-key": QDRANT_KEY
},
body: body
})
// we cannot use json parse because id are BigInt
// build the response containing an array of id and score by parsing the response text
//
let resp = await response.text()
let r1 = /"id":(?<id>\d+)/g
let r2 = /"score":(?<score>\d*.\d*)/g
while ((m=r1.exec(resp)) != null) {
data.push( {
"id":'0x' + BigInt(m.groups['id']).toString(16)
})
}
let i = 0
while ((m=r2.exec(resp)) != null) {
data[i]["score"]=m.groups['score']
i++
}
// console.log(`Qdrant result: ${JSON.stringify(data)}`)
} catch (error) {
console.log(error)
}
return data // array with id and score
}
async function mutateRDF(dql,rdfs) {
// Use DQL mutation to store the rdfs
if (rdfs !== "") {
return dql.mutate(`{
set {
${rdfs}
}
}`)
}
}
async function embedding(text) {
let url = `https://api.openai.com/v1/embeddings`;
let response = await fetch(url,{
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": "Bearer "+OPENAI_KEY
},
body: `{ "input": "${text}", "model": "text-embedding-ada-002" }`
})
let data = await response.json();
console.log(`embedding = ${data.data[0].embedding}`)
return data.data[0].embedding;
}
async function addProjectWebhook({event, dql, graphql, authHeader}) {
var rdfs = "";
for (let i = 0; i < event.add.rootUIDs.length; ++i ) {
console.log(`adding embedding for Project ${event.add.rootUIDs[i]} ${event.add.input[i]['title']}`)
var uid = event.add.rootUIDs[i];
const v1 = await embedding(event.add.input[i].title);
await saveVector("Project",uid,v1);
if (event.add.input[i]['category'] == undefined) {
// if the project is added without category
similarCategories = await searchSimilarity(v1,"Category",1);
console.log(`set closest category to ${similarCategories[0].id}`)
rdfs += `<${uid}> <Project.category> <${similarCategories[0].id}> .
`;
} else {
console.log(`Project ${event.add.rootUIDs[i]} added with category ${event.add.input[i]['category'].name}`)
}
}
await mutateRDF(dql,rdfs);
}
async function addCategoryWebhook({event, dql, graphql, authHeader}) {
var rdfs = "";
// webhook may receive an array of UIDs
// apply the same logic for each node
for (let i = 0; i < event.add.rootUIDs.length; ++i ) {
console.log(`adding embedding for ${event.add.rootUIDs[i]} ${event.add.input[i]['name']}`)
const uid = event.add.rootUIDs[i];
// retrieve the embedding for the category name
const data = await embedding(event.add.input[i]['name']);
await saveVector("Category",uid,data);
}
}
async function semSearchProjects({args, dql}) {
// semantic search Projects
// get vector
const v1 = await embedding(args.title);
const limit = args.first;
// find similar Project
const projects = await searchSimilarity(v1,"Project",limit);
ids = projects.map( (p)=> '0x'+BigInt(p.id).toString(16))
scores = {}
projects.forEach( (p)=> { scores['0x'+BigInt(p.id).toString(16)]=p.score})
const query = `{
projects(func:uid(${ids})) {
id:uid
title: Project.title
category:Project.category { id:uid name:Category.name}
grade:Project.grade
}
}`
console.log(query)
const results = await dql.query(query)
console.log(JSON.stringify(results))
results.data.projects.forEach( (p)=>{ p.score = scores[p.id]})
return [results.data.projects]
}
self.addWebHookResolvers({
"Project.add": addProjectWebhook,
"Category.add": addCategoryWebhook,
"Query.semSearchProjects": semSearchProjects
})
Let’s examine what’s new in this code compared to previous post.
self.addWebHookResolvers({
"Project.add": addProjectWebhook,
"Category.add": addCategoryWebhook,
"Query.semSearchProjects": semSearchProjects
})
Registers the JS functions for each operations declared in the @lambdaOnMutate directives and for the @lambda query.
async function saveVector(nodetype,uid,vec)
Use the Qdrant API to save the embedding. We use the Dgraph node uid as the vector id in Qdrant.
Dgraph UIDs are hexadecimal strings and Qdrant ids are big integer. We need to perform the conversion back and forth.
The payload attached to the vector is reduced to the node type information. We don’t need to store more data as all the information about the node is in Dgraph.
async function searchSimilarity(vec,nodetype,limit=10)
simply uses the /points/search Qdrant API and returns the list of id and score.
We can now add some categories using the GraphQL API generated by Dgraph from the GraphQL schema.
In GraphQL explorer, paste the following query:
mutation addCategory($input: [AddCategoryInput!]!) {
addCategory(input: $input) {
category {
id
name
}
}
}
Paste the following JSON in the variables section
{
"input": [
{"name":"Math & Science"},
{"name":"Health & Sports"},
{"name": "History & Civics"},
{"name": "Literacy & Language"},
{"name": "Music & The Arts"},
{"name": "Special Needs"}
]
}
Execute the mutation.
Use the following mutation to add projects:
mutation NewProjectMutation($input: [AddProjectInput!]!) {
addProject(input: $input) {
numUids
}
}
with the variables
{
"input": [
{"title": "Multi-Use Chairs for Music Classes"},
{"title": "Photography and Memories....Yearbook in the Works"},
{"title": "Current Events in Second Grade"},
{"title": "Great Green Garden Gables"},
{"title": "Albert.io Prepares South LA students for AP Success!"},
{"title": "Learning and Growing Through Collaborative Play in TK!"},
{"title": "Sit Together, Learn Together, Grow Together!"},
{"title": "Help Special Children Succeed with Social Skills!"},
{"title": "iCreate with a Mini iPad"},
{"title": "Photography and Memories....Yearbook in the Works"},
{"title": "The Truth About Junk Food"},
{"title": "I Can Listen"},
{"title": "Making Math A Group Learning Experience"},
{"title": "The Center Of Learning: Kindergarten Fun!"}
]
}
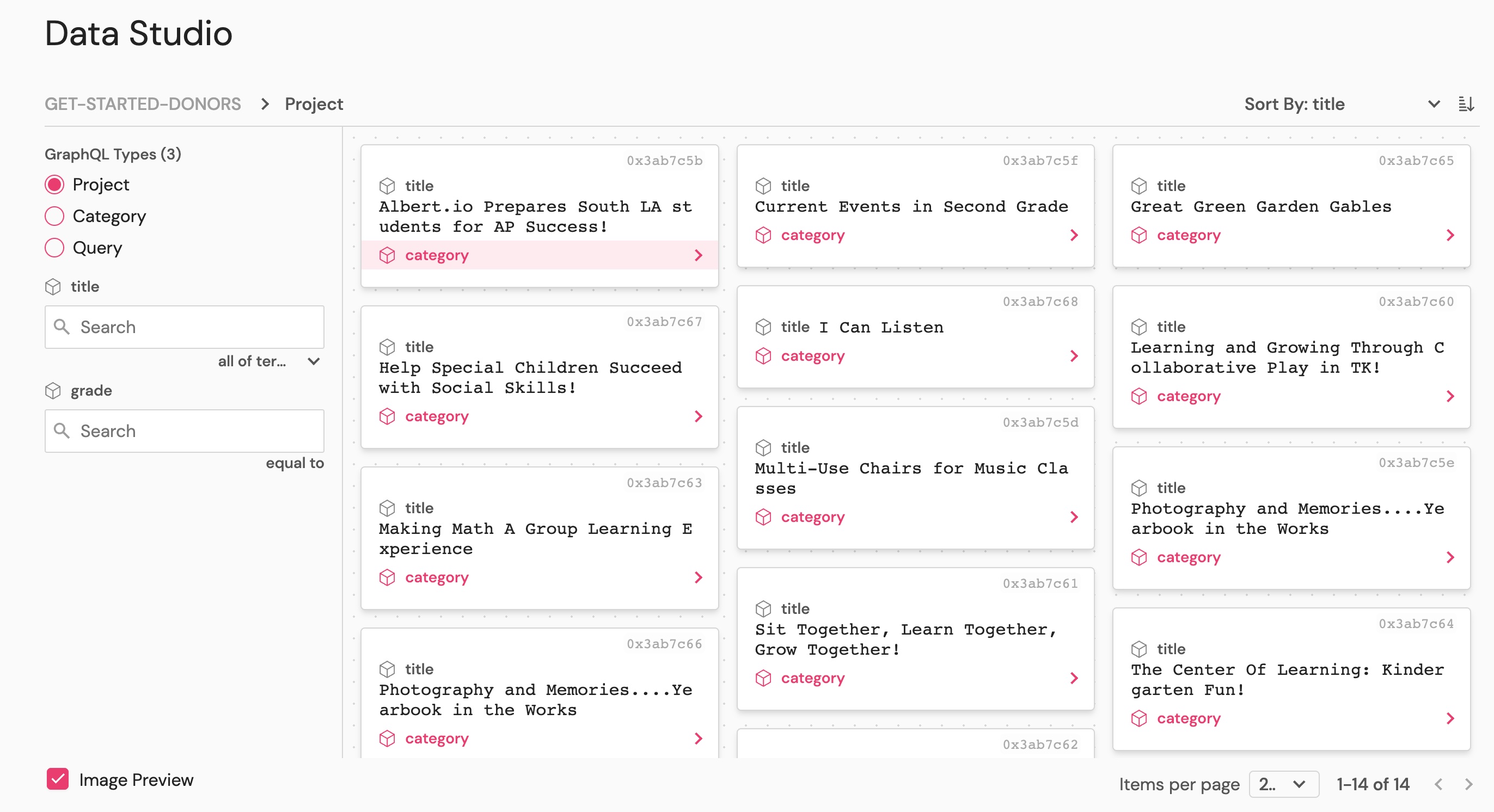
In the Data Studio you can see the projects created and the category associated with each project.
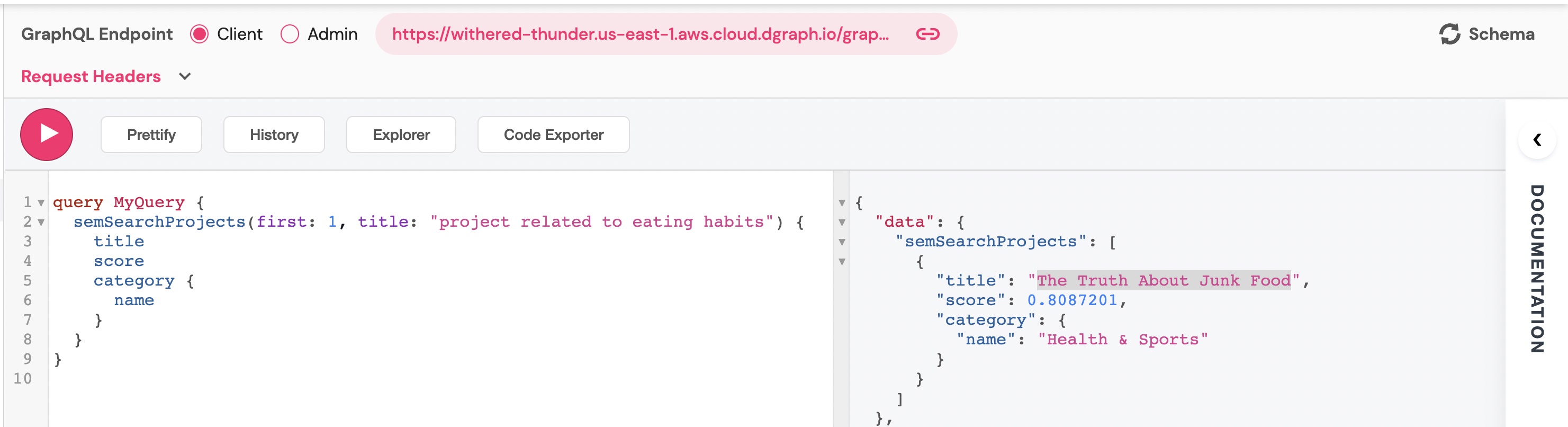
In GraphQL explorer, experience with the semSearchProjects query.
query MyQuery {
semSearchProjects(first: 1, title: "project related to eating habits") {
title
score
category {
name
}
}
}
The result should be the project “The Truth About Junk Food”.
Play with more data, ask for more results, and check the scores.
With the ease of use of GraphQL API generation and the power of JavaScript custom resolvers (Dgraph lambda), boosting your graph data with AI is an easy task in Dgraph.
In this Blog, we showed how to leverage OpenAI API to compute word embeddings when data is added to Dgraph, and to use a Vector database to implement a semantic search of nodes in the graph. In conjunction with the Dgraph query language, this approach allows you to implement sophisticated use cases.
Knights Analytics are experts in AI and Data Management, they have been a partner of Dgraph for over 4 years.
Knights’ enterprise Alchemia platform streams data from structured and unstructured sources into Dgraph while cleaning, matching and merging entities and concepts to form a richly connected graph.
Their Alchemia platform processes all types of data, and they have developed a range of AI tooling to clean, enrich, and resolve entities (individuals, companies etc) or concepts (events, topics etc) into a knowledge graph, matching incoming data with ground truth ontologies.
Check them out here: www.knightsanalytics.com
Photo by NASA