
Product recommendation using RAG on Dgraph
In this blog post, we will use Dgraph database to store retail products information (Amazon products data ...
Learn more

Dgraph stores data as you think about it: a network of interconnected pieces of information, a Graph!
The recent advance of language models from OpenAI, provides us with interesting tools to make your data smarter, and automate tedious tasks such as data classification.
In this post we will show you how to use word embeddings in Dgraph to make your data smarter and have automatic classification. You can try it yourself in few minutes, as Dgraph is also a fantastic data platform for Rapid Application development.
For an overview, refer to the following video:
Word embedding is an AI technique representing words and sentences in a very large vector space. Large Language Models (LLMs) encode words and other terms into vectors based on their context in sentences, based on training from a massive corpus. Following the distributional hypothesis stating that “Words which frequently appear in similar contexts have similar meaning”, words with similar meaning tend to have a similar ‘position’ in the vector space.
With this technique, we can transpose the question “do those two words or two sentences have the same meaning ?” into computing a vector similarity!
GPT models have democratized the usage of Large Language Models (LLM): they are pre-trained, (the P in Generalized Pre-trained Transformers) so you can use the models without going through the tedious process of creating them. Moreover ‘using a model’ can be as simple as invoking a REST service.
Note: when using a model you have not trained yourself, always have a look at the model quality, what it is supposed to be good at, and the potential training bias. For example, you should be aware of the social bias of openAI embeddings models.
Let’s consider the data model we have used in the Rapid Application development blog.
In this use case about donations to projects issued by public schools in the US, projects such as “Photography and Memories….Yearbook in the Works”, “Fund a Much Needed Acid Cabinet & Save Us from Corrosion!” have categories ( “Music & The Arts”, “Math & Science”, …).
The project category is usually selected by the teacher when creating the project. We want to remove this step and have the category infered automatically when a project is created.
If you want to try this out yourself, the easiest way to get Dgraph up and running is to signup for Dgraph Cloud and launch a free backend.
We will focus on Project and Category so we can work on a simplified model to experiment auto-classification.
We will tell Dgraph that we want to do some specific logic when a Project or a Category is added. We are using the custom directive @lambdaOnMutate:
type Project @lambdaOnMutate(add: true, update: false, delete: false) {
id: ID!
title: String! @search(by: [term])
grade: String @search(by: [hash])
category: Category
}
type Category @lambdaOnMutate(add: true, update: false, delete: false) {
id: ID!
name: String!
}
Copy this schema in the Dgraph Cloud dashboard and deploy it.
Dgraph automatically created a GraphQL API to update and query Projects and Categories, and the @lambdaOnMutate directive means you can add additional code to run whenever there is an update (mutation). You will soon add the LLM integration in the “Dgraph Lambda” step below.
The API is up and running! We can test it without the auto-classification.
Let’s create “test” project by running a GraphQL mutation. Copy the request in the GraphQL explorer and run the query.
mutation MyMutation {
addProject(input: {title: "Dgraph & OpenAI integration"}) {
project {
id
}
}
}
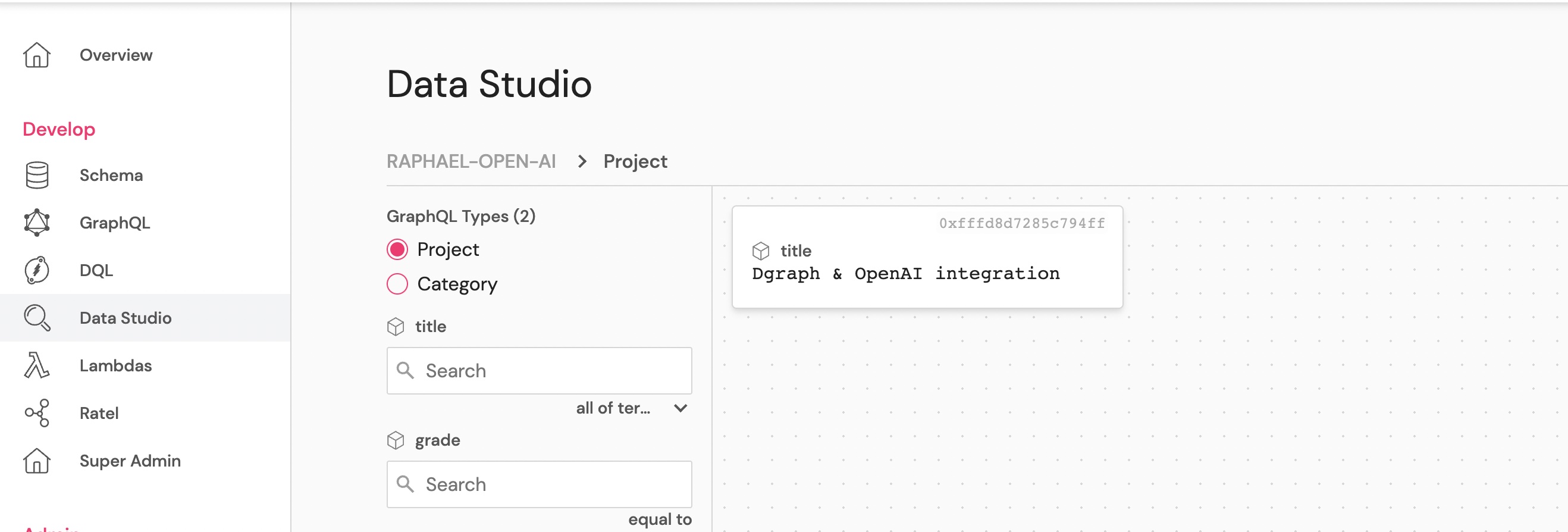
Access the Data Studio view to verify that we have one project created. It has a title but not category.
OpenAI API
Keep a copy of the key as we will use it to invoke OpenAI REST API from Dgraph.
Dgraph lambda
Dgraph lambda provides a way to write custom logic in JavaScript, integrate it with your GraphQL schema, and execute it using the GraphQL API.
We are using webhooks which are a specific type of Lambda, executed asynchronosouly after an add, delete, or update operation. Using the @lambdaOnMutate directive, we have already declared a lambda webhook on add operations for Category and Project in the GraphQL Schema.
Now we need to write the JS code, and add it to the GraphQL resolvers.
Auto classification logic
The auto classification logic is simple:
embedding predicate.cosine similarity between the title’s embedding and each category’s embedding.cosine similarity as a relationship called similarity between the project and the category, with an cosine property added as a facet on the relationship indicating how similar it is.more similar category to create a relationship Project.category as expected in the GraphQL Schema.
We are using interresting Dgraph features here:
embedding and similarity relationships are not declared in the GraphQL schema. We are creating those relationships with Dgraph Query language. That means, in Dgraph, you can easily add “meta-data” or any type of information “on-top” of a graph generated by the GraphQL API.DQL predicates
In our logic we are adding some information in the graph in the form of predicates embedding and similarity.
Refer to the DQL Schema section of the documention.
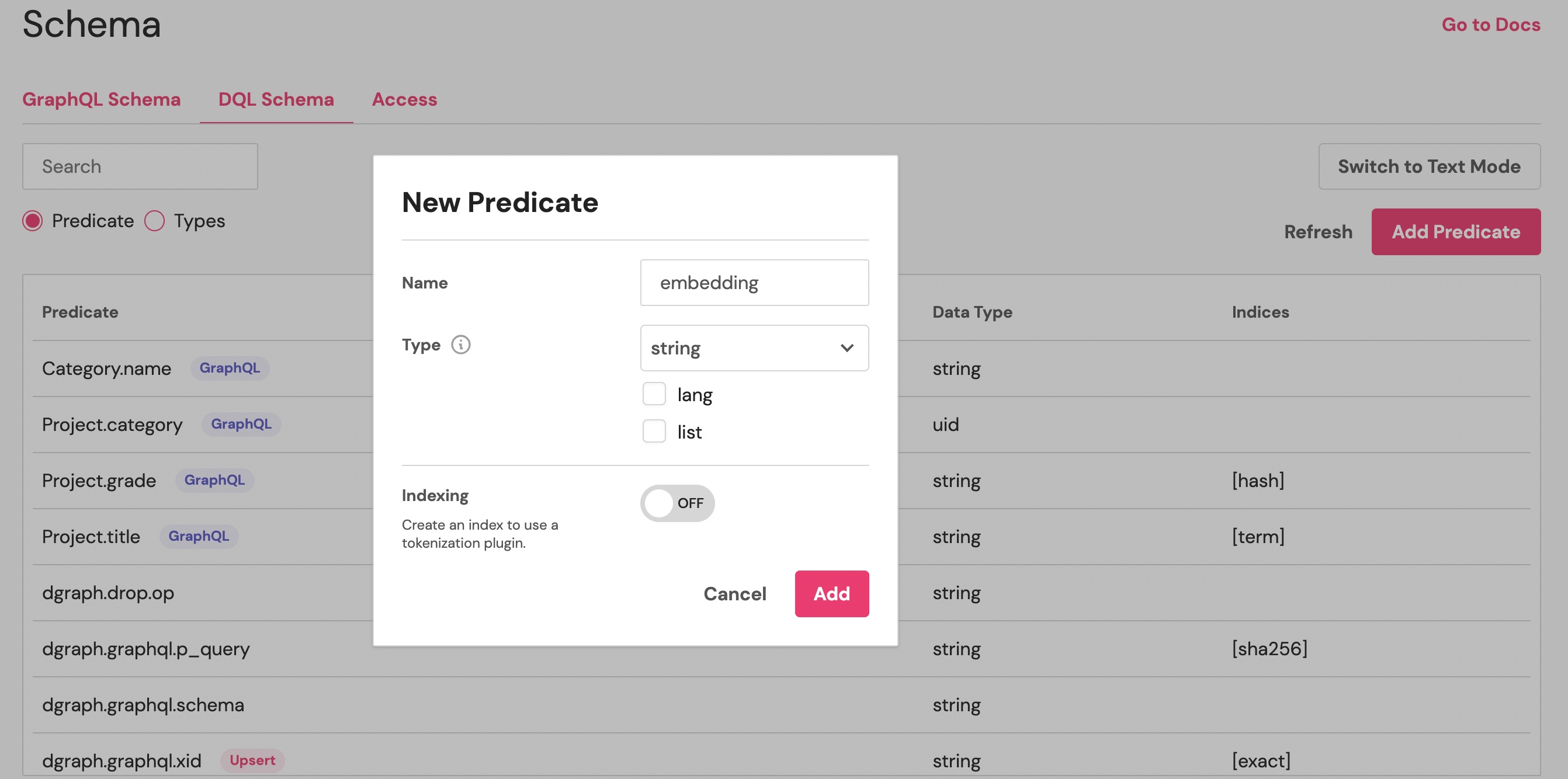
We need to declare those two predicates: access the DQL Schema tab in your Dgraph Cloud dashboard, and click Add predicate.
Add the predicate embedding of type String:
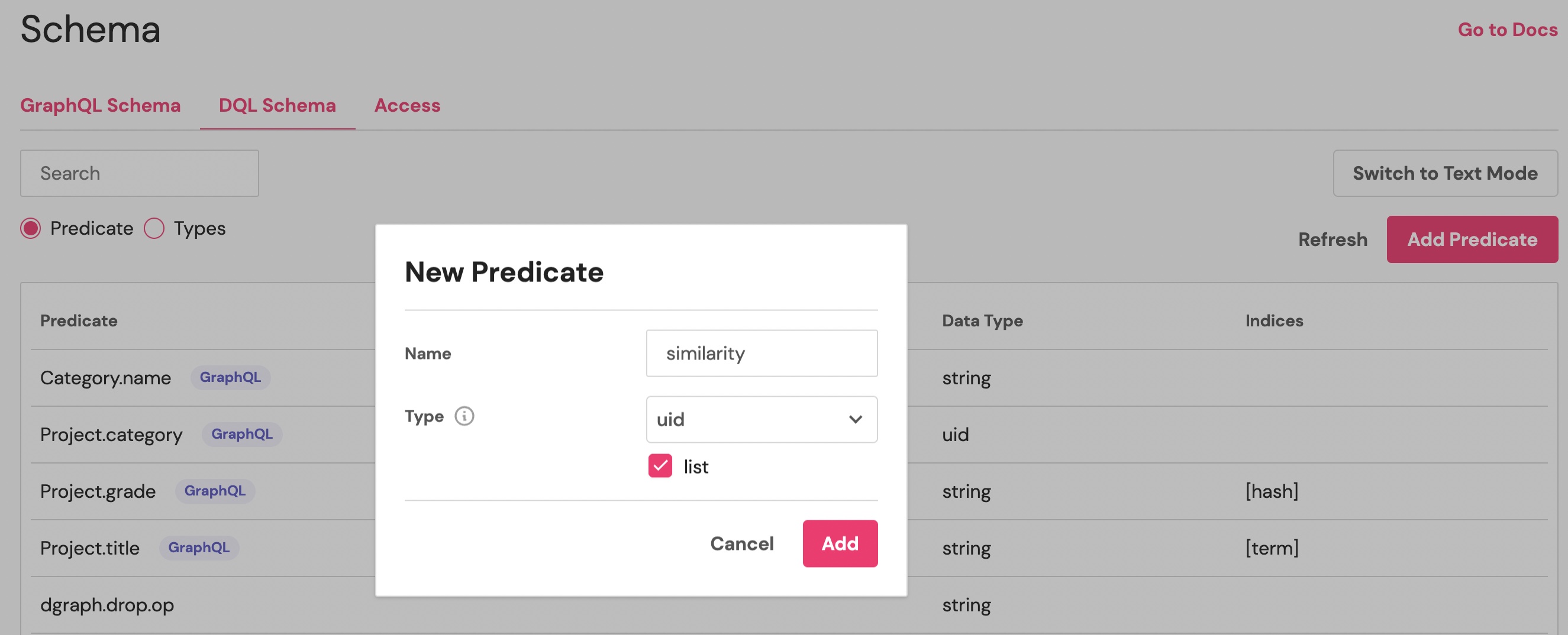
Do the same for the predicate similarity of type uid and declare it as a list:
adding the embedding predicate
Lambda code
Here is the complete code of our lambda.
Copy this code, set you OpenAI API key in the"Authorization": "Bearer " line.
Paste the code with you OpenAI API key in the Script section of Dgraph lambda configuration and save.
function dotProduct(v,w) {
return v.reduce((l,r,i)=>l+r*w[i],0)
// as openapi embedding vectors are normalized
// dot product = cosine similarity
}
async function mutateRDF(dql,rdfs) {
//
if (rdfs !== "") {
return dql.mutate(`{
set {
${rdfs}
}
}`)
}
}
async function embedding(text) {
let url = `https://api.openai.com/v1/embeddings`;
let response = await fetch(url,{
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": "Bearer <--- replace by your OpenAI API key ----->"
},
body: `{ "input": "${text}", "model": "text-embedding-ada-002" }`
})
let data = await response.json();
console.log(`embedding = ${data.data[0].embedding}`)
return data.data[0].embedding;
}
async function addProjectWebhook({event, dql, graphql, authHeader}) {
const categoriesData = await dql.query(`{
categories(func:type(Category)) {
uid
name:Category.name
embedding
}
}`)
for (let c of categoriesData.data.categories ) {
c.vector = JSON.parse(c.embedding);
}
var rdfs = "";
for (let i = 0; i < event.add.rootUIDs.length; ++i ) {
console.log(`adding embedding for Project ${event.add.rootUIDs[i]} ${event.add.input[i]['title']}`)
var uid = event.add.rootUIDs[i];
const v1 = await embedding(event.add.input[i].title);
const serialized = JSON.stringify(v1);
if (event.add.input[i]['category'] == undefined) {
let category="";
let max = 0.0;
let similarityMutation = "";
for (let c of categoriesData.data.categories ) {
const similarity = dotProduct(v1,c.vector);
similarityMutation += `<${uid}> <similarity> <${c.uid}> (cosine=${similarity}) .\n`;
if (similarity > max) {
category = c.uid;
max = similarity;
}
}
console.log(`set closest category`)
rdfs += `${similarityMutation}
<${uid}> <embedding> "${serialized}" .
<${uid}> <Project.category> <${category}> .
`;
} else {
console.log(`Project ${event.add.rootUIDs[i]} added with category ${event.add.input[i]['category'].name}`)
rdfs += `<${uid}> <embedding> "${serialized}" .
`;
}
}
await mutateRDF(dql,rdfs);
}
async function addCategoryWebhook({event, dql, graphql, authHeader}) {
var rdfs = "";
// webhook may receive an array of UIDs
// apply the same logic for each node
for (let i = 0; i < event.add.rootUIDs.length; ++i ) {
console.log(`adding embedding for ${event.add.rootUIDs[i]} ${event.add.input[i]['name']}`)
const uid = event.add.rootUIDs[i];
// retrieve the embedding for the category name
const data = await embedding(event.add.input[i]['name']);
const serialized = JSON.stringify(data);
// create a tripple to associate the embedding to the category using the predicate <embedding>
rdfs += `<${uid}> <embedding> "${serialized}" .
`;
}
// use a single mutation to save all the embeddings
await mutateRDF(dql,rdfs);
}
self.addWebHookResolvers({
"Project.add": addProjectWebhook,
"Category.add": addCategoryWebhook
})
Let’s examine what this code is doing:
self.addWebHookResolvers({
"Project.add": addProjectWebhook,
"Category.add": addCategoryWebhook
})
Registers the JS functions for each operations declared in the @lambdaOnMutate directives.
function dotProduct(v,w) {
return v.reduce((l,r,i)=>l+r*w[i],0)
// as openapi embedding vectors are normalized
// dot product = cosine similarity
}
An elegant way to compute a dot product!
async function embedding(text) {
let url = `https://api.openai.com/v1/embeddings`;
let response = await fetch(url,{
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": "Bearer <--- replace by your OpenAI API key ----->"
},
body: `{ "input": "${text}", "model": "text-embedding-ada-002" }`
})
let data = await response.json();
console.log(`embedding = ${data.data[0].embedding}`)
return data.data[0].embedding;
}
Retrieves the embedding for a given text using OpenAI /v1/embeddings API and text-embedding-ada-002 model.
That’s where you have to set you OpenAI API key.
async function mutateRDF(dql,rdfs) {
if (rdfs !== "") {
return dql.mutate(`{
set {
${rdfs}
}
}`)
}
}
Is an helper function to execute a mutation and save the provided RDFs. We are using dql which is an helper object provided to the webhook.
async function addCategoryWebhook({event, dql, graphql, authHeader}) {
var rdfs = "";
// webhook may receive an array of UIDs
// apply the same logic for each node
for (let i = 0; i < event.add.rootUIDs.length; ++i ) {
console.log(`adding embedding for ${event.add.rootUIDs[i]} ${event.add.input[i]['name']}`)
const uid = event.add.rootUIDs[i];
// retrieve the embedding for the category name
const data = await embedding(event.add.input[i]['name']);
const serialized = JSON.stringify(data);
// create a tripple to associate the embedding to the category using the predicate <embedding>
rdfs += `<${uid}> <embedding> "${serialized}" .
`;
}
// use a single mutation to save all the embeddings
await mutateRDF(dql,rdfs);
}
addCategoryWebhook applies our logic when a new Category is added. The Webhook may be invoked with an array of add events. We simply compute the embedding for each Category name added and create an RDF to save this information.
addProjectWebhook is computing the embedding of the project title, the similarity to all the categories and set the project’s category to the most similar.
We can now add some categories using the GraphQL API generated by Dgraph from the GraphQL schema.
Doing so, Dgraph will automatically associate a semantic representation ( the embedding) to the new categories.
You can use any GraphQL client with the GraphQL endpoint found on the Cloud dashboad
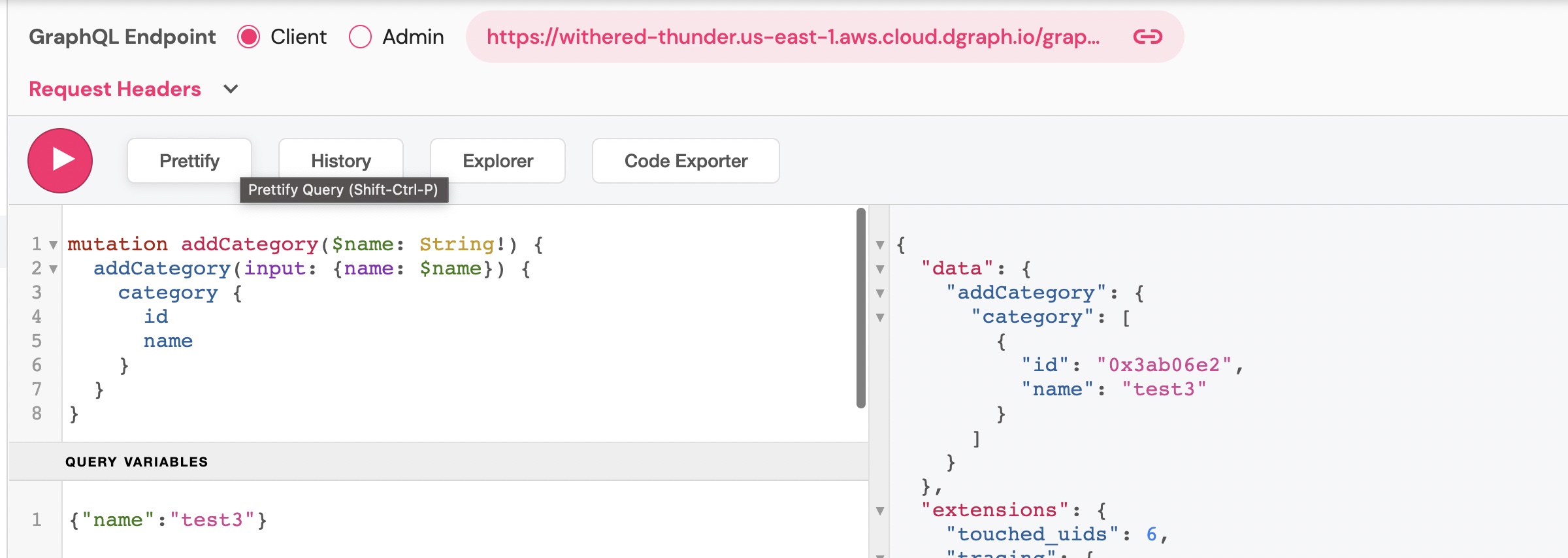
We are just using the GraphQL explorer, paste the following mutation and run it:
mutation addCategory($name: String!) {
addCategory(input: {name: $name}) {
category {
id
name
}
}
}
Paste the following JSON in the variables section
{"name":"Math & Science"}
Re-run the mutation for different category names
We can now verify that Dgraph has added embedding information to every category. embedding is not exposed through our GraphQL schema, so we must use Dgraph Query Language (DQL) to directly read the database.
Copy-paste the following DQL query in the DQL section of the dashboard, and execute it.
{
categories(func:type(Category)) {
uid
name:Category.name
embedding
}
}
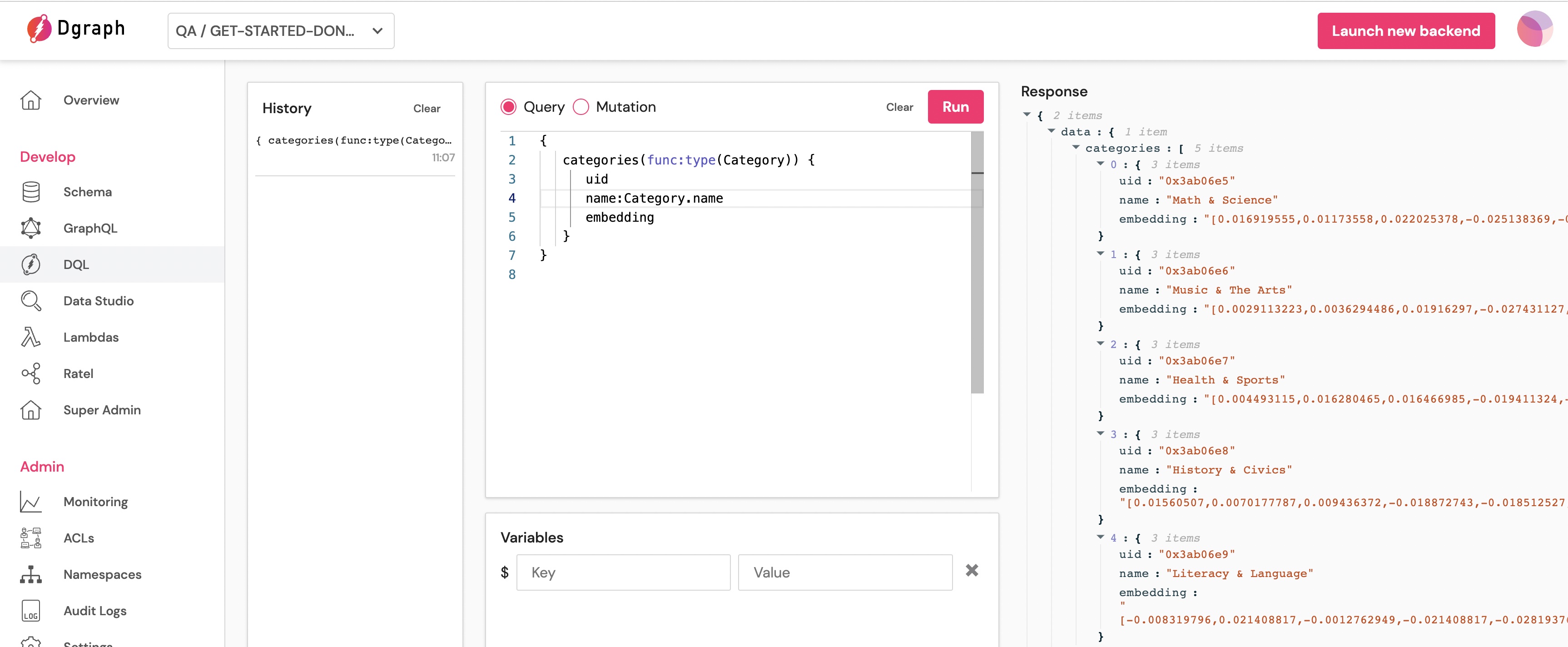
You can see that each category has an embedding.
Returning to the GraphQL explorer, paste the following mutation and run it to create a Project
mutation AddProject($title: String!) {
addProject(input: {title: $title}) {
project {
id
}
}
}
with the variables
{"title":"Fund a Much Needed Acid Cabinet & Save Us from Corrosion!"}

In the Data Studio you can see that your project has been created and that it has a Category.
The Category automatically selected for this project is “Math & Science” in our case.
You can also run a GraphQL query
query MyQuery {
queryProject(first: 10) {
title
category {
name
}
}
}
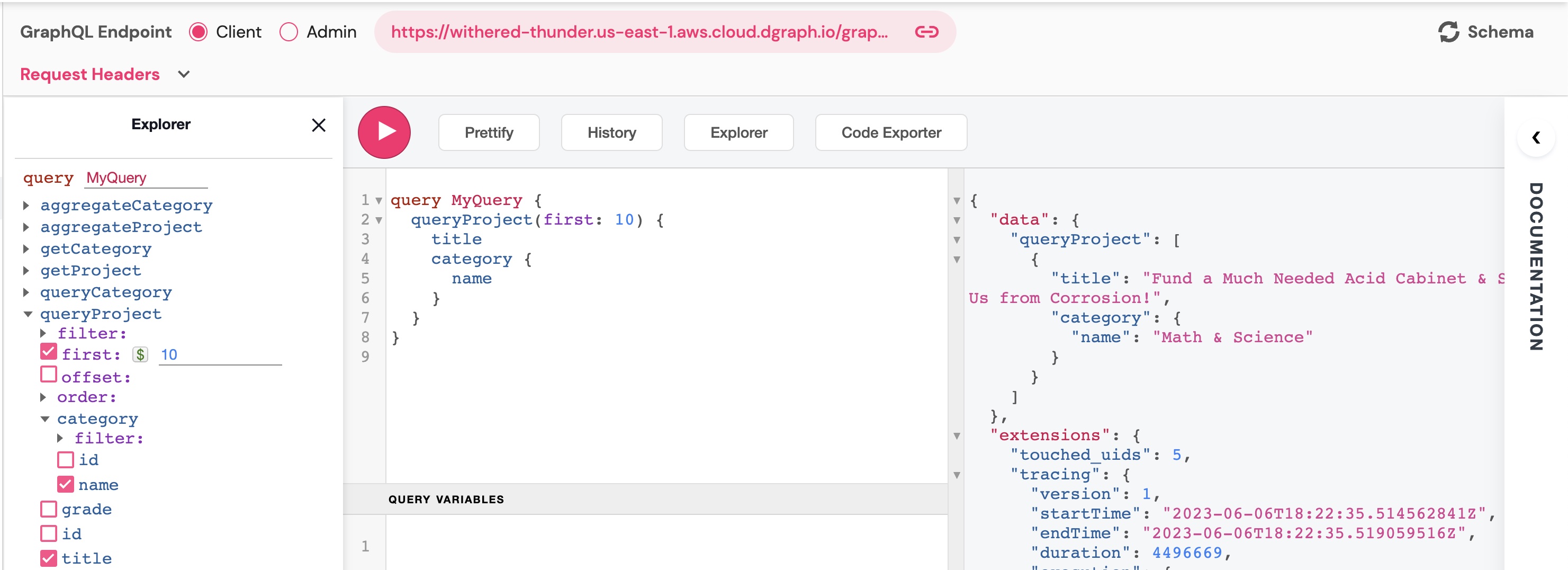
With the ease of use of GraphQL API generation and the power of javascript custom resolvers (Dgraph lambda), boosting your graph data with AI is an easy task in Dgraph.
In this Blog, we showed how to use OpenAI API to compute word embeddings when data is added to Dgraph, to use the embeddings to evaluate semantic similarity between project’s title and category’s name, and finally to automatically create the correct relationships between projects and categories.
Photo by Pixabay
