GraphQL 101: What is GraphQL?
Most people within the tech world have heard of GraphQL at this point. Adoption is also booming at steady ...
Learn more

Welcome to the sixth episode of getting started with Dgraph.
In the previous episode, we learned about building social graphs in Dgraph, by modeling tweets as an example.
We queried the tweets using the hash and exact indices, and implemented a keyword-based search to find your favorite tweets using the term index and its functions.
In this tutorial, we’ll continue from where we left off and learn about advanced text search features in Dgraph.
Specifically, we’ll focus on two advanced features:
Before we dive in, let’s do a quick recap of how to model the tweets in Dgraph.
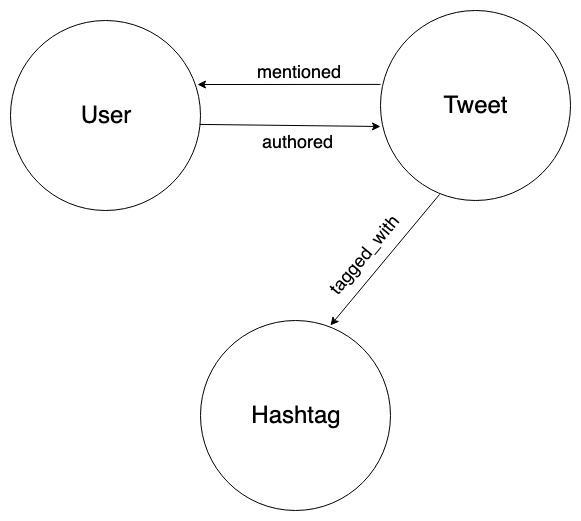
In the previous episode, we took three real tweets as a sample dataset and stored them in Dgraph using the above graph as a model.
In case you haven’t stored the tweets from the previous episode into Dgraph, here’s the sample dataset again.
Copy the mutation below, go to the mutation tab and click Run.
{
"set": [
{
"user_handle": "hackintoshrao",
"user_name": "Karthic Rao",
"uid": "_:hackintoshrao",
"authored": [
{
"tweet": "Test tweet for the fifth episode of getting started series with @dgraphlabs. Wait for the video of the fourth one by @francesc the coming Wednesday!\n#GraphDB #GraphQL",
"tagged_with": [
{
"uid": "_:graphql",
"hashtag": "GraphQL"
},
{
"uid": "_:graphdb",
"hashtag": "GraphDB"
}
],
"mentioned": [
{
"uid": "_:francesc"
},
{
"uid": "_:dgraphlabs"
}
]
}
]
},
{
"user_handle": "francesc",
"user_name": "Francesc Campoy",
"uid": "_:francesc",
"authored": [
{
"tweet": "So many good talks at #graphqlconf, next year I'll make sure to be *at least* in the audience!\nAlso huge thanks to the live tweeting by @dgraphlabs for alleviating the FOMO😊\n#GraphDB ♥️ #GraphQL",
"tagged_with": [
{
"uid": "_:graphql"
},
{
"uid": "_:graphdb"
},
{
"hashtag": "graphqlconf"
}
],
"mentioned": [
{
"uid": "_:dgraphlabs"
}
]
}
]
},
{
"user_handle": "dgraphlabs",
"user_name": "Dgraph Labs",
"uid": "_:dgraphlabs",
"authored": [
{
"tweet": "Let's Go and catch @francesc at @Gopherpalooza today, as he scans into Go source code by building its Graph in Dgraph!\nBe there, as he Goes through analyzing Go source code, using a Go program, that stores data in the GraphDB built in Go!\n#golang #GraphDB #Databases #Dgraph ",
"tagged_with": [
{
"hashtag": "golang"
},
{
"uid": "_:graphdb"
},
{
"hashtag": "Databases"
},
{
"hashtag": "Dgraph"
}
],
"mentioned": [
{
"uid": "_:francesc"
},
{
"uid": "_:dgraphlabs"
}
]
},
{
"uid": "_:gopherpalooza",
"user_handle": "gopherpalooza",
"user_name": "Gopherpalooza"
}
]
}
]
}
Note: If you’re new to Dgraph, and this is the first time you’re running a mutation, we highly recommend reading the first episode of the series before proceeding.
Voilà! Now you have a graph with tweets, users, and hashtags. It is ready for us to explore.
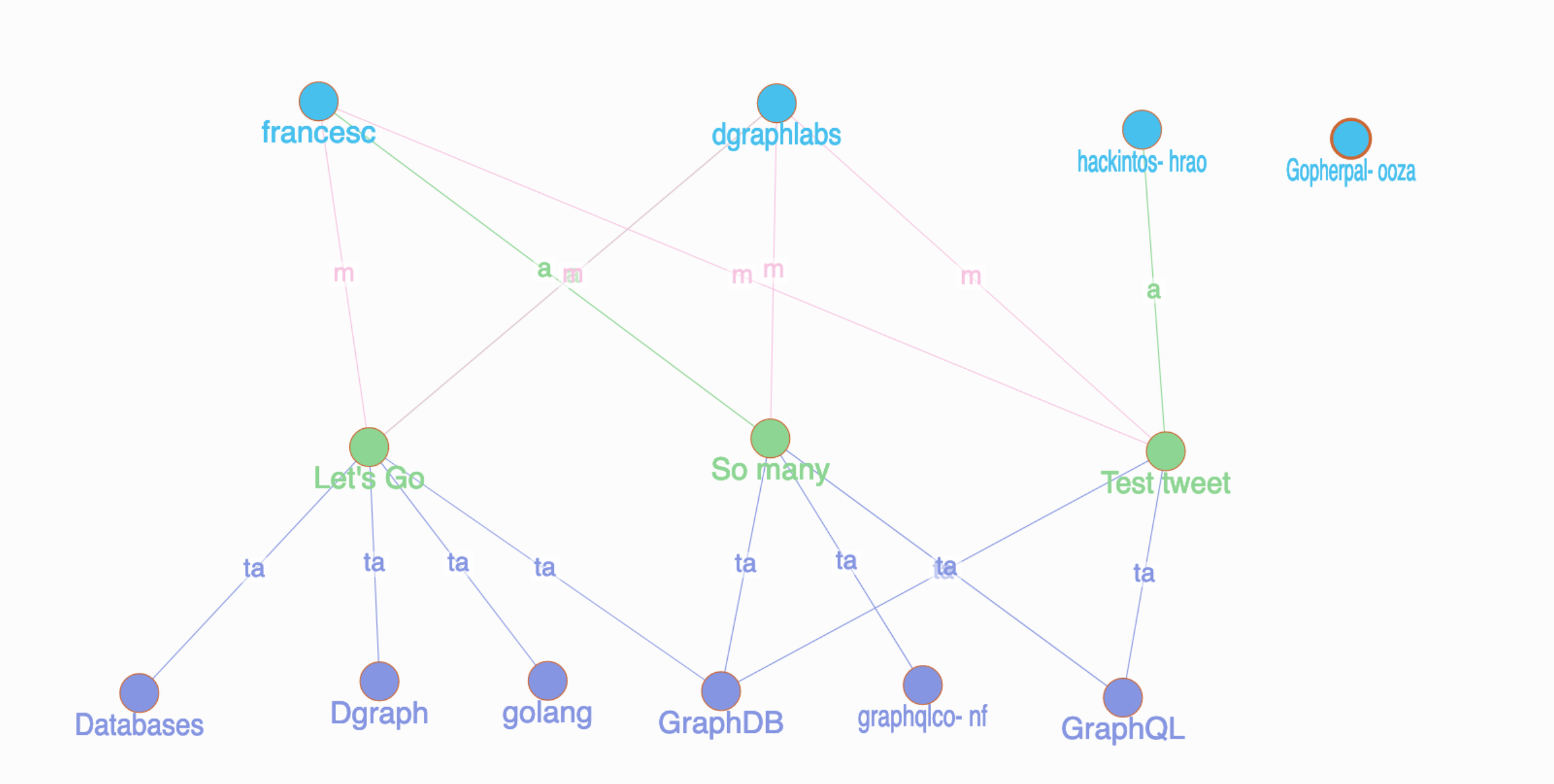 Note: If you’re curious to know how we modeled the tweets in Dgraph, refer to the previous episode.
Note: If you’re curious to know how we modeled the tweets in Dgraph, refer to the previous episode.
Let’s start by finding your favorite tweets using the full-text search feature first.
Before we learn how to use the Full-text search feature, it’s important to understand when to use it.
The length and the number of words in a string predicate value vary based on what the predicates represent.
Some string predicate values have only a few terms (words) in them.
Predicates representing names, hashtags, twitter handle, city names are a few good examples. These predicates are easy to query using their exact values.
For instance, here is an example query.
Give me all the tweets where the user name is equal to John Campbell.
You can easily compose queries like these after adding either the hash or an exact index to the string predicates.
But, some of the string predicates store sentences. Sometimes even one or more paragraphs of text data in them. Predicates representing a tweet, a bio, a blog post, a product description, or a movie review are just some examples. It’s relatively hard to query these predicates.
It’s not practical to query such predicates using the hash or exact string indices.
A keyword-based search using the term index is a good starting point to query such predicates.
We used it in our previous episode to find the tweets with an exact match for keywords like GraphQL, Graphs, and Go.
But, for some of the use cases, just the keyword-based search may not be sufficient. You might need a more powerful search capability, and that’s when you should consider using Full-text search.
Let’s write some queries and understand Dgraph’s Full-text search capability in detail.
To be able to do a Full-text search, you need to first set a fulltext index on the tweet predicate.
Creating a fulltext index on any string predicate is similar to creating any other string indices.
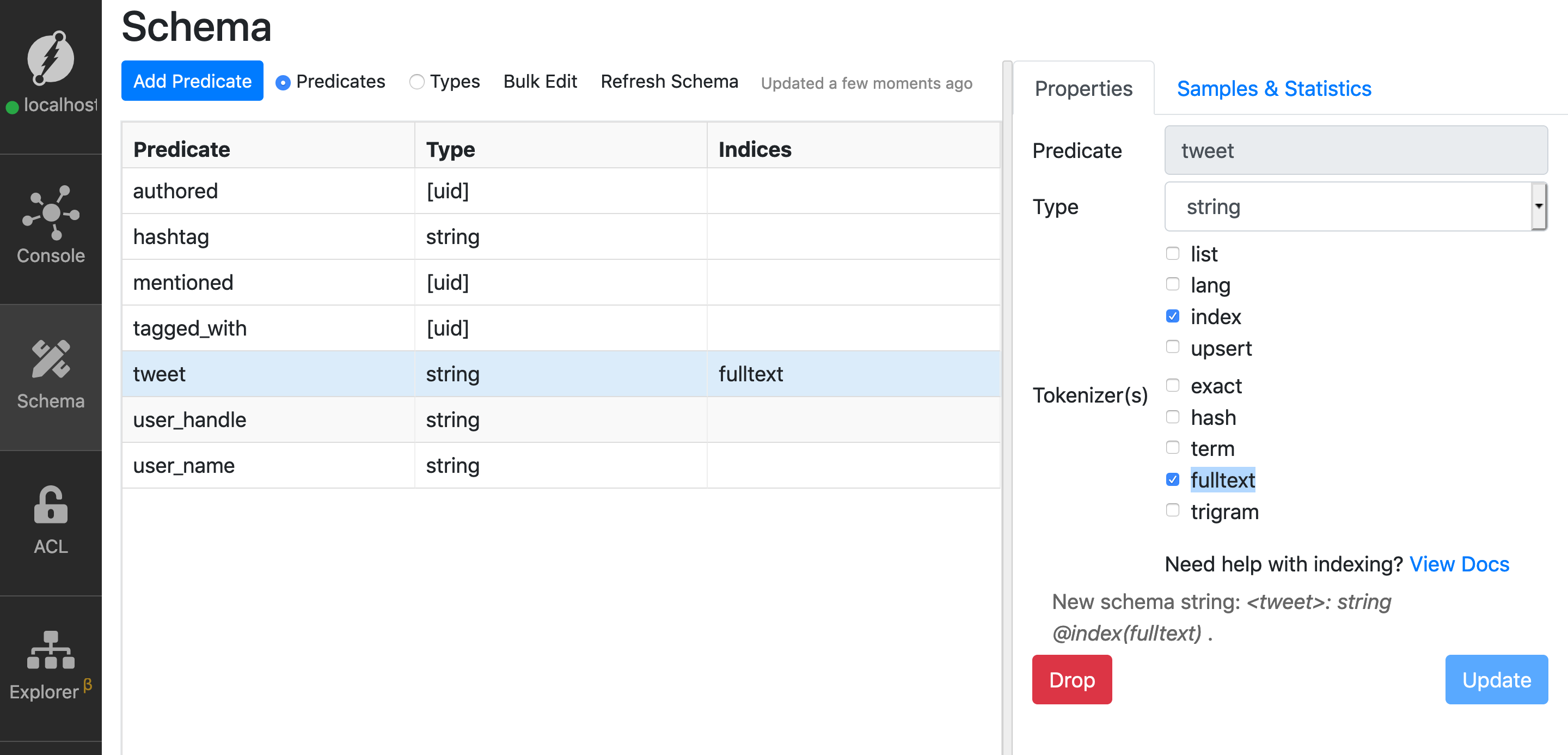 Note: Refer to the previous episode if you’re not sure about creating an index on a string predicate.
Note: Refer to the previous episode if you’re not sure about creating an index on a string predicate.
Now, let’s do a Full-text search query to find tweets related to the following topic: graph data and analyze it in graphdb.
You can do so by using either of alloftext or anyoftext in-built functions.
Both functions take two arguments.
The first argument is the predicate to search.
The second argument is the space-separated string values to search for, and we call these as the search strings.
- alloftext(predicate, "space-separated search strings")
- anyoftext(predicate, "space-separated search strings")
We’ll look at the difference between these two functions later. For now, let’s use the alloftext function.
Go to the query tab, paste the query below, and click Run.
Here is our search string: graph data and analyze it in graphdb.
{
search_tweet(func: alloftext(tweet, "graph data and analyze it in graphdb")) {
tweet
}
}
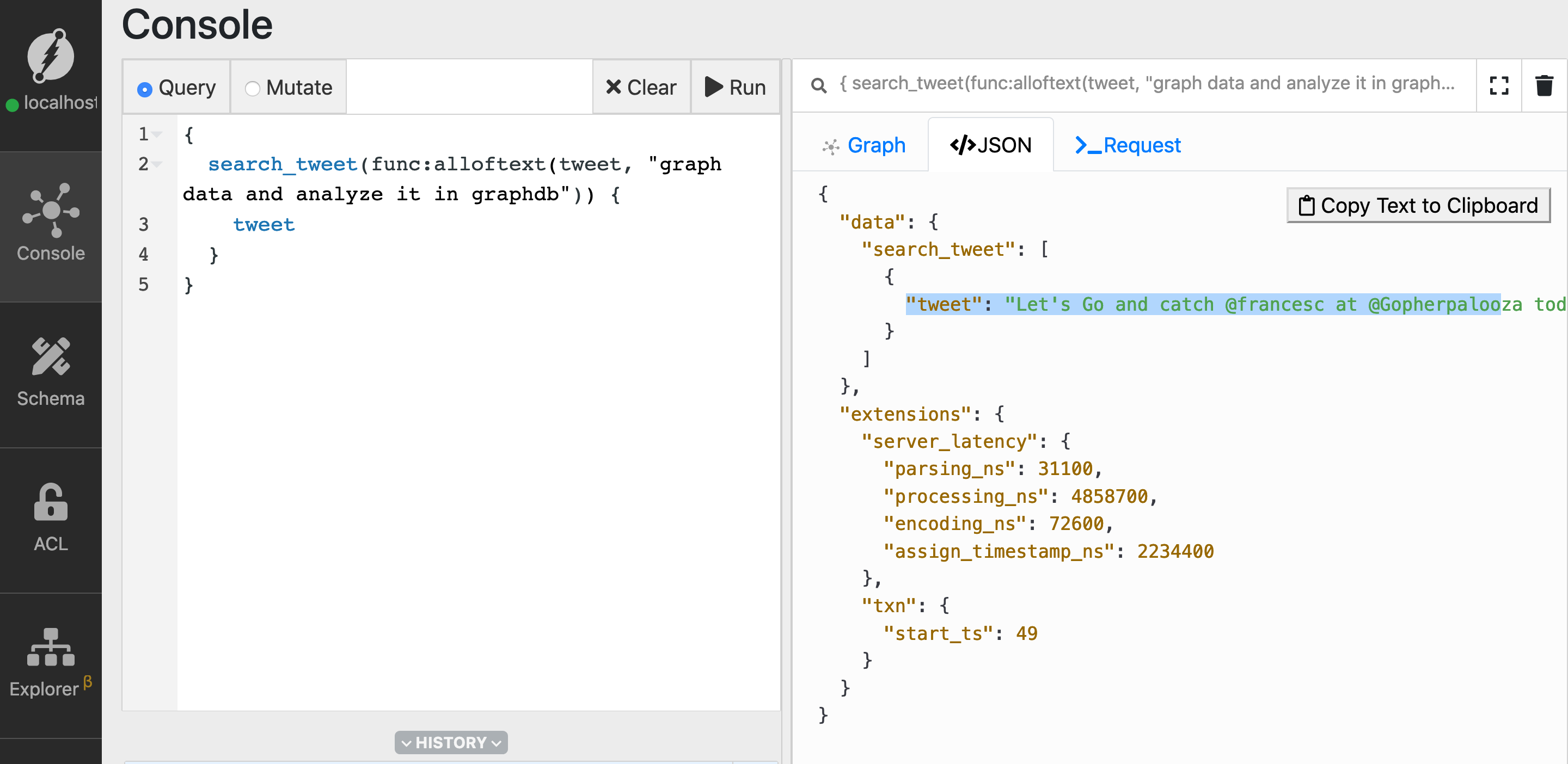
Here’s the matched tweet, which made it to the result.
Let's Go and catch @francesc at @Gopherpalooza today, as he scans into Go source code by building its Graph in Dgraph!
— Dgraph Labs (@dgraphlabs) November 8, 2019
Be there, as he Goes through analyzing Go source code, using a Go program, that stores data in the GraphDB built in Go!#golang #GraphDB #Databases #Dgraph pic.twitter.com/sK90DJ6rLs
If you observe, you can see some of the words from the search strings are not present in the matched tweet, but the tweet has still made it to the result.
To be able to use the Full-text search capability effectively, we must understand how it works.
Let’s understand it in detail.
Once you set a fulltext index on the tweets, internally, the tweets are processed, and fulltext tokens are generated.
These fulltext tokens are then indexed.
The search string also goes through the same processing pipeline, and fulltext tokens generated them too.
Here are the steps to generate the fulltext tokens:
You would have seen in the fourth episode that Dgraph allows you to build multi-lingual apps.
The stemming and stop words removal are not supported for all the languages. Here is the link to the docs that contains the list of languages and their support for stemming and stop words removal.
Below is the table with the matched tweet and its search string in the first column.
The second column contains their corresponding fulltext tokens generated by Dgraph.
| Actual text data | fulltext tokens generated by Dgraph |
|---|---|
| Let’s Go and catch @francesc at @Gopherpalooza today, as he scans into Go source code by building its Graph in Dgraph!\nBe there, as he Goes through analyzing Go source code, using a Go program, that stores data in the GraphDB built in Go!\n#golang #GraphDB #Databases #Dgraph | [analyz build built catch code data databas dgraph francesc go goe golang gopherpalooza graph graphdb program scan sourc store todai us] |
| graph data and analyze it in graphdb | [analyz data graph graphdb] |
As you can see from the table, you can see that the tweets are reduced to an array of strings or tokens (Dgraph internally uses Bleve package to do the stemming).
There are four fulltext tokens generated for our search string: [analyz, data, graph, graphdb], and all four tokens exist in the matched tweet.
Hence, the alloftext function returns a positive match for the tweet. It would not have returned a positive match even if one of the tokens in the search string is missing for the tweet.
However, on the other hand, the anyoftext function would’ve returned a positive match as long as the tweets and the search string have at least one of the tokens in common.
If you’re interested to see Dgraph’s fulltext tokenizer in action, here is the gist containing the instructions to use it.
Dgraph generates the same fulltext tokens even if the words in a search string is differently ordered.
Hence, using the same search string with different order would not impact the query result.
As you can see, all three queries below are the same for Dgraph.
{
search_tweet(func: alloftext(tweet, "graph analyze and it in graphdb data")) {
tweet
}
}
{
search_tweet(func: alloftext(tweet, "data and data analyze it graphdb in")) {
tweet
}
}
{
search_tweet(func: alloftext(tweet, "analyze data and it in graph graphdb")) {
tweet
}
}
Next, let’s move onto the second advanced text search feature of Dgraph: regular expression based queries.
We will use them to find all the hashtags containing the following substring: graph.
Regular expressions are powerful ways of expressing search patterns.
Dgraph allows you to search for string predicates based on regular expressions.
You need to set the trigram index on the string predicate to be able to perform regex-based queries.
Using regular expression based search, let’s match all the hashtags that have this particular pattern: Starts and ends with any characters of indefinite length, but with the substring graph in it.
Here is the regex expression we can use: ^.*graph.*$
Check out this tutorial if you’re not familiar with writing a regular expression.
Let’s first find all the hashtags in the database using the has() function.
{
hash_tags(func: has(hashtag)) {
hashtag
}
}
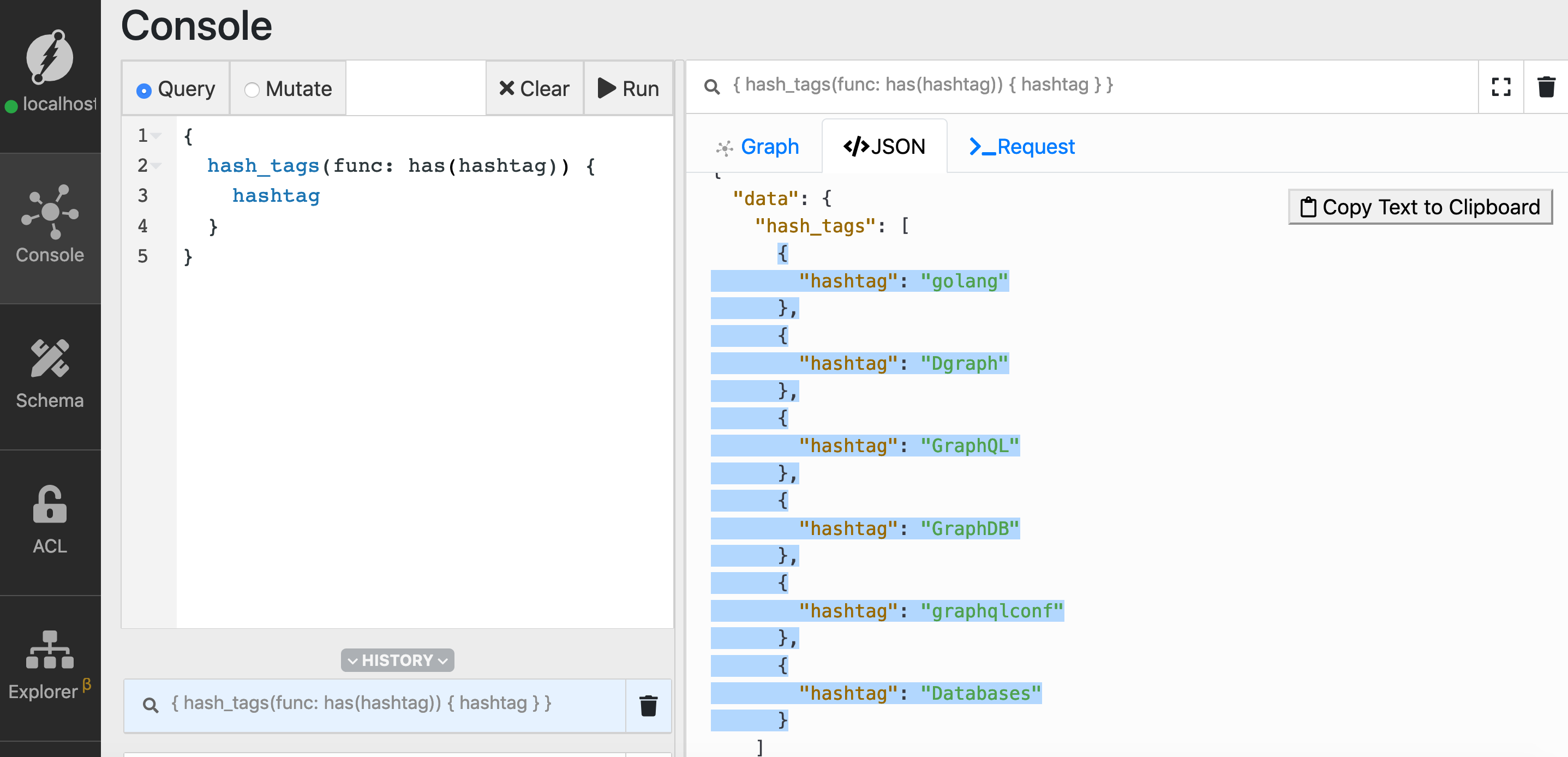 If you’re not familiar with using the
If you’re not familiar with using the has() function, refer to the first episode of the series.
You can see that we have six hashtags in total, and four of them have the substring graph in them: Dgraph, GraphQL, graphqlconf, graphDB.
We should use the built-in function regexp to be able to use regular expressions to search for predicates.
This function takes two arguments, the first is the name of the predicate, and the second one is the regular expression.
Here is the syntax of the regexp funtion: regexp(predicate, /regular-expression/)
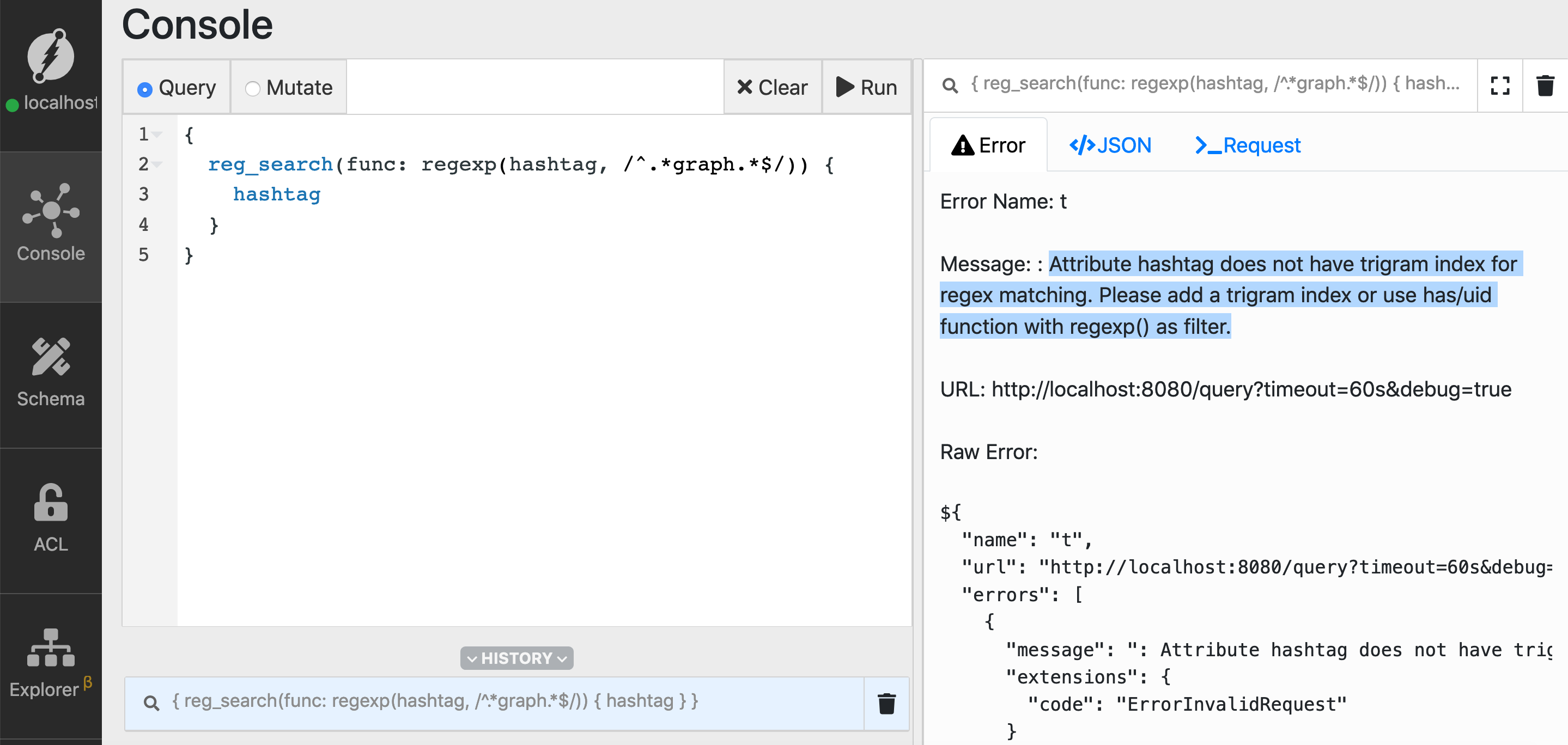
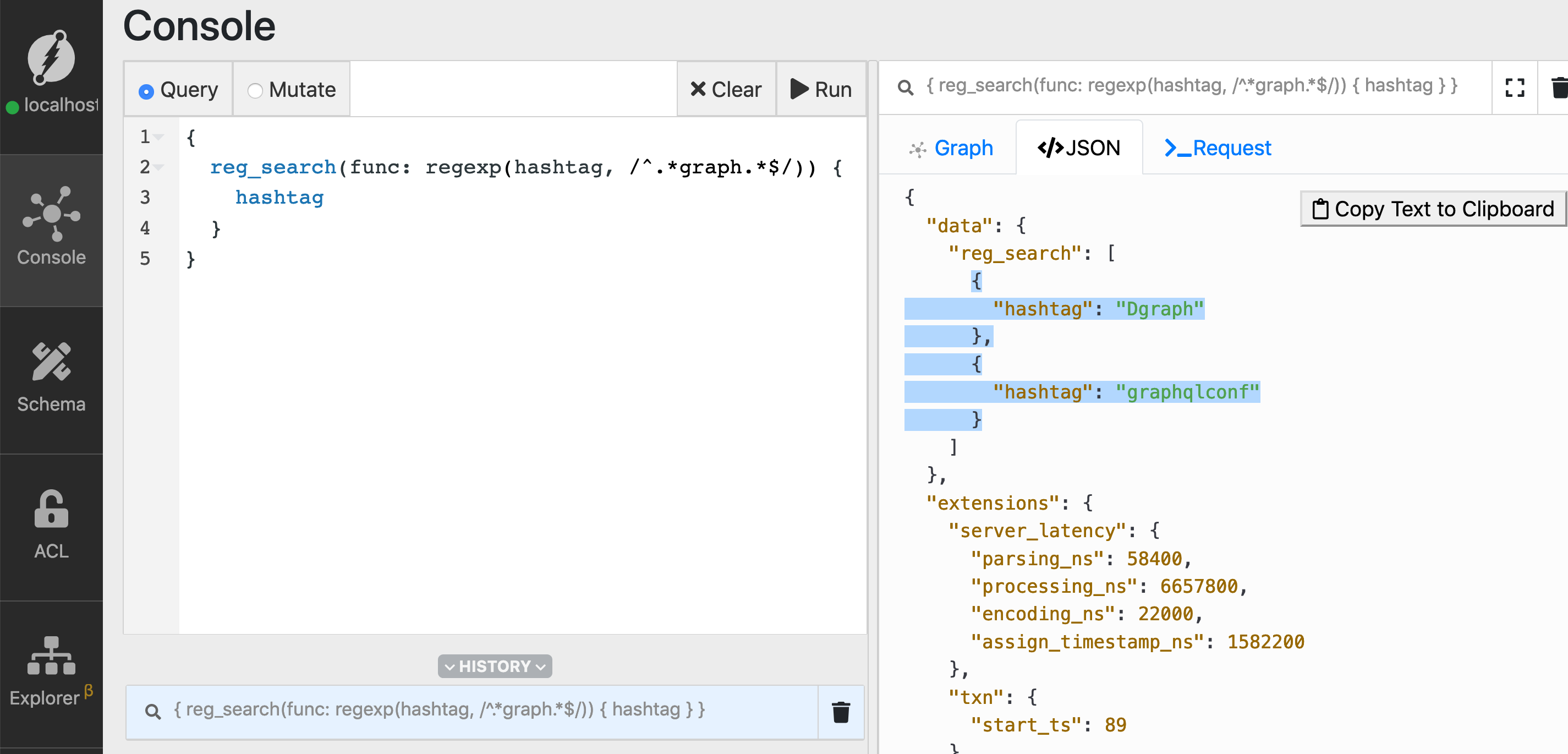
Let’s execute the following query to find the hashtags that have the substring graph.
Go to the query tab, type in the query, and click Run.
{
reg_search(func: regexp(hashtag, /^.*graph.*$/)) {
hashtag
}
}
Oops! We have an error!
It looks like we forgot to set the trigram index on the hashtag predicate.
Again, setting a trigram index is similar to setting any other string index, let’s do that for the hashtag predicate.
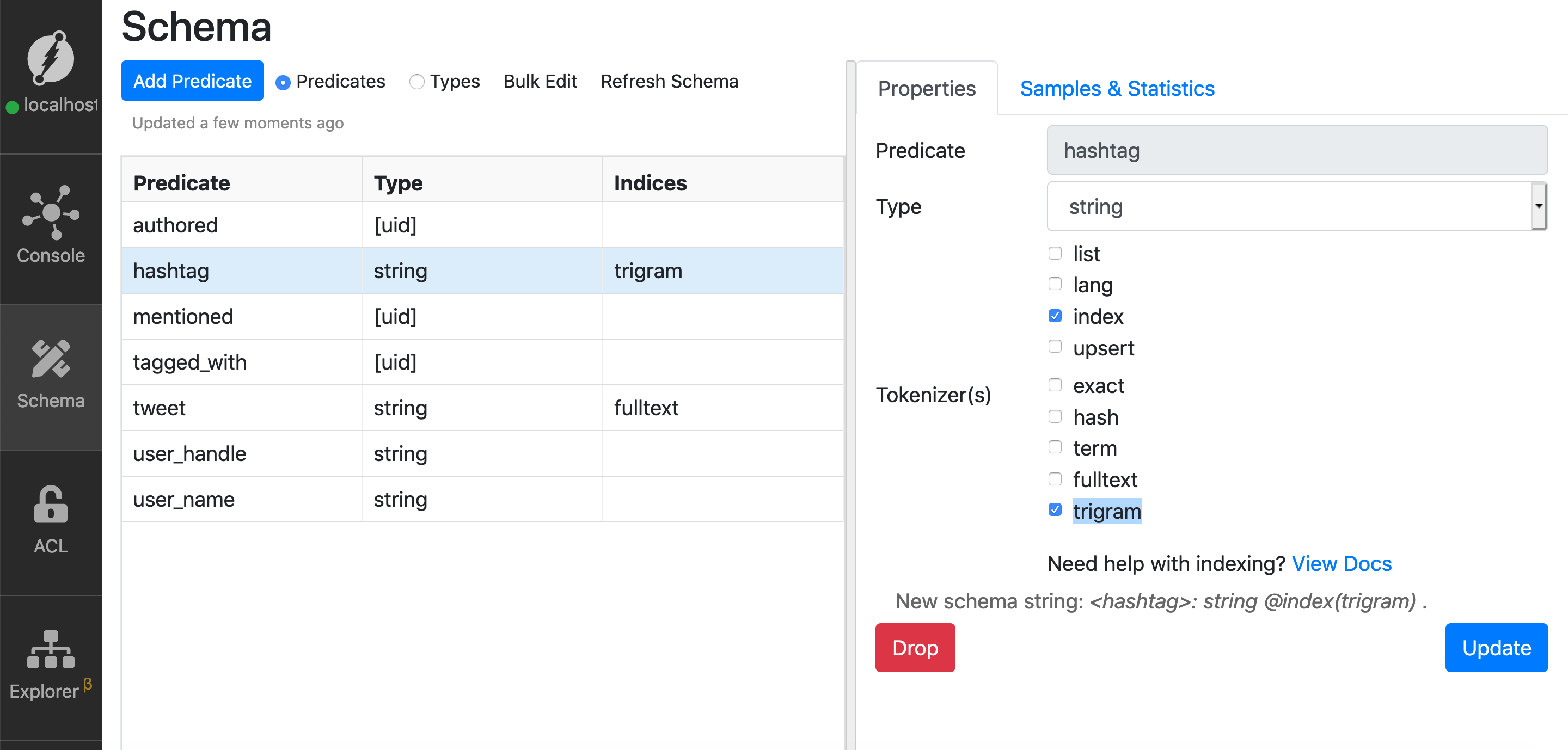 Note: Refer to the previous episode if you’re not sure about creating an index on a string predicate.
Note: Refer to the previous episode if you’re not sure about creating an index on a string predicate.
Now, let’s re-run the regexp query.
 Note: Refer to the first episode if you’re not familiar with the query structure in general.
Note: Refer to the first episode if you’re not familiar with the query structure in general.
Now we have success!
But why do we only have the following hashtags Dgraph and graphqlconf in the result?
That’s because regexp function is case-sensitive by default.
Add the character i at the the end of the second argument of the regexp function to make it case insensitive: regexp(predicate, /regular-expression/i)
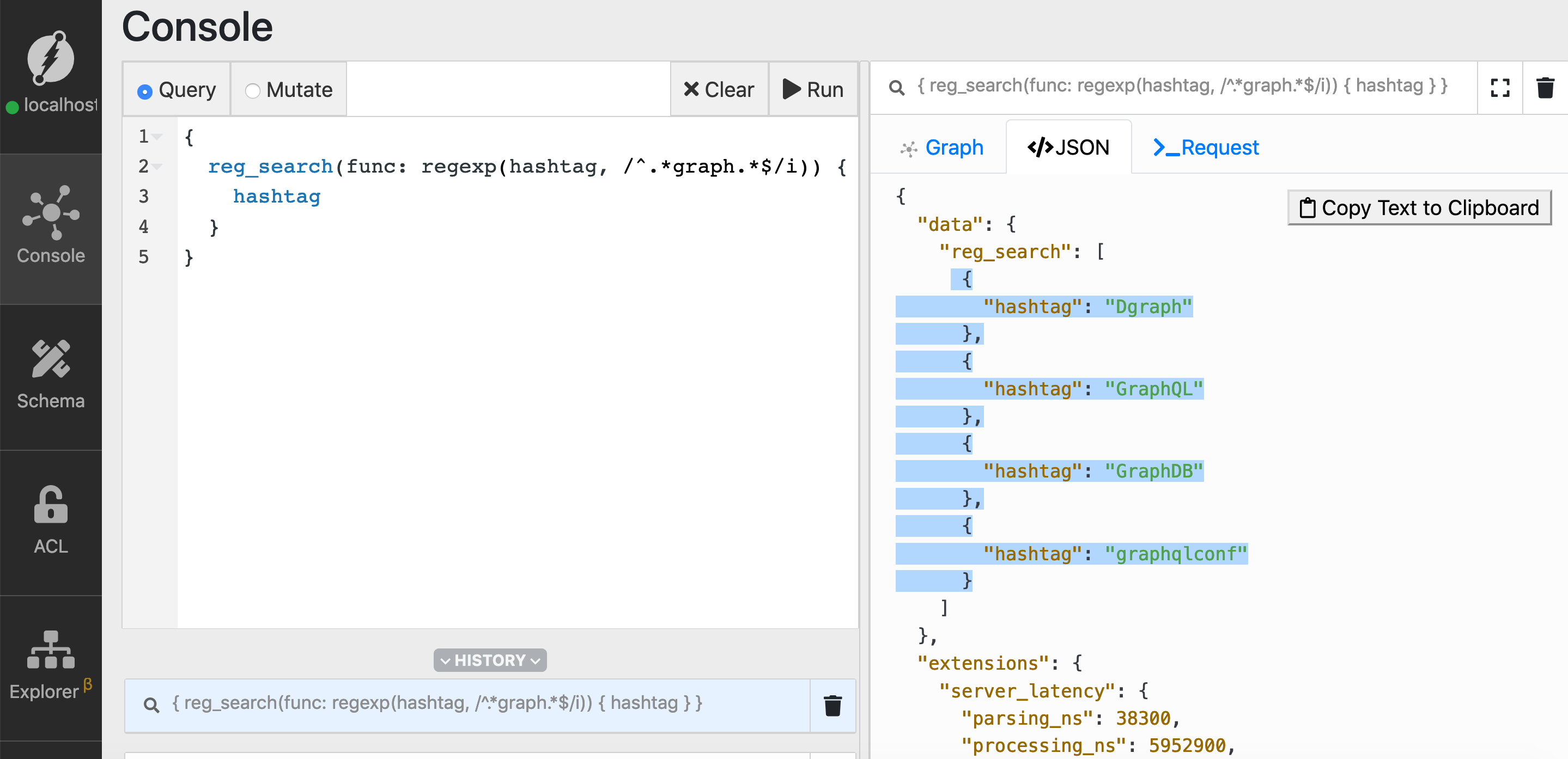
Now we have the four hashtags with substring graph in them.
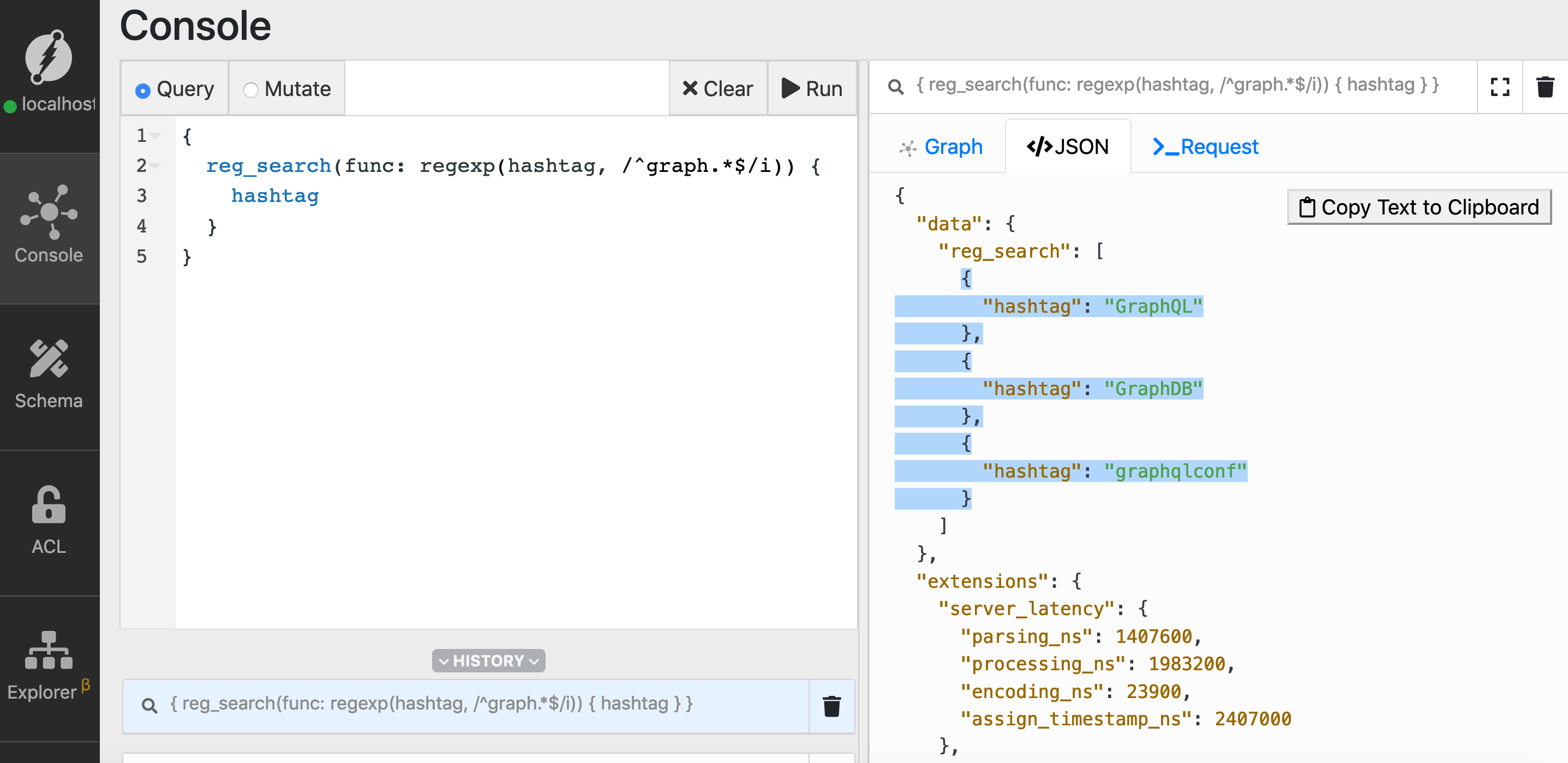
Let’s modify the regular expression to match only the hashtags which have a prefix called graph.
{
reg_search(func: regexp(hashtag, /^graph.*$/i)) {
hashtag
}
}
In this tutorial, we learned about Full-text search and regular expression based search capabilities in Dgraph.
Did you know that Dgraph also offers fuzzy search capabilities, which can be used to power features like product search in an e-commerce store? Let’s learn about it in our next tutorial.
Till then, happy Graphing!
Remember to click the “Join our community” button below and subscribe to our newsletter to get the latest tutorial right to your inbox.
