
GraphQL Sorting: A Beginner's Guide
Sorting data in GraphQL is a powerful tool that enhances the usability and performance of your applicatio ...
Learn more

With GraphQL being a client-centric technology, it allows you to have fine control over how you request your data. Query responses in GraphQL contain the exact data you’ve asked for, no more and no less. In GraphQL, responses strictly follow the shape of the requests, and this is one of its superpowers. This approach is highly efficient, solves the over and under-fetching problems of traditional API approaches, and much more.
That’s great and all, but most modern applications demand even more flexibility. What if you don’t know exactly what you want to retrieve or are looking for? What if you want to search through data so that you can figure out what you need? All of these tasks can be delivered through GraphQL!
Dgraph makes GraphQL super easy. Besides auto-generating all the query types from your schema types, it also builds search and filtering capabilities into your API. This gives you more power and control over your use of data, out-of-the-box.
You can also specify the kind of search. This enables you to search based on terms (words), regular expressions, and so on. You can even do range-based queries. For example, you could query for films with scores between 70 and 80 percent on Rotten Tomatoes.
Here are the topics we’re going to look at in this article:
@search directiveExcited? Let’s go!
Firstly, we need to create an API to use as a playground. To do so, head over to the signup page and sign up if you haven’t done so already. Then click on Launch a Backend.
In the next window, select the Free tier to get started. Give your backend a name and click Launch.
Give it a few seconds to spin up. You’ll see a dashboard soon with details of your new backend. Note down the GraphQL endpoint at the top—that’s where all your requests will go when issuing GraphQL queries and mutations.
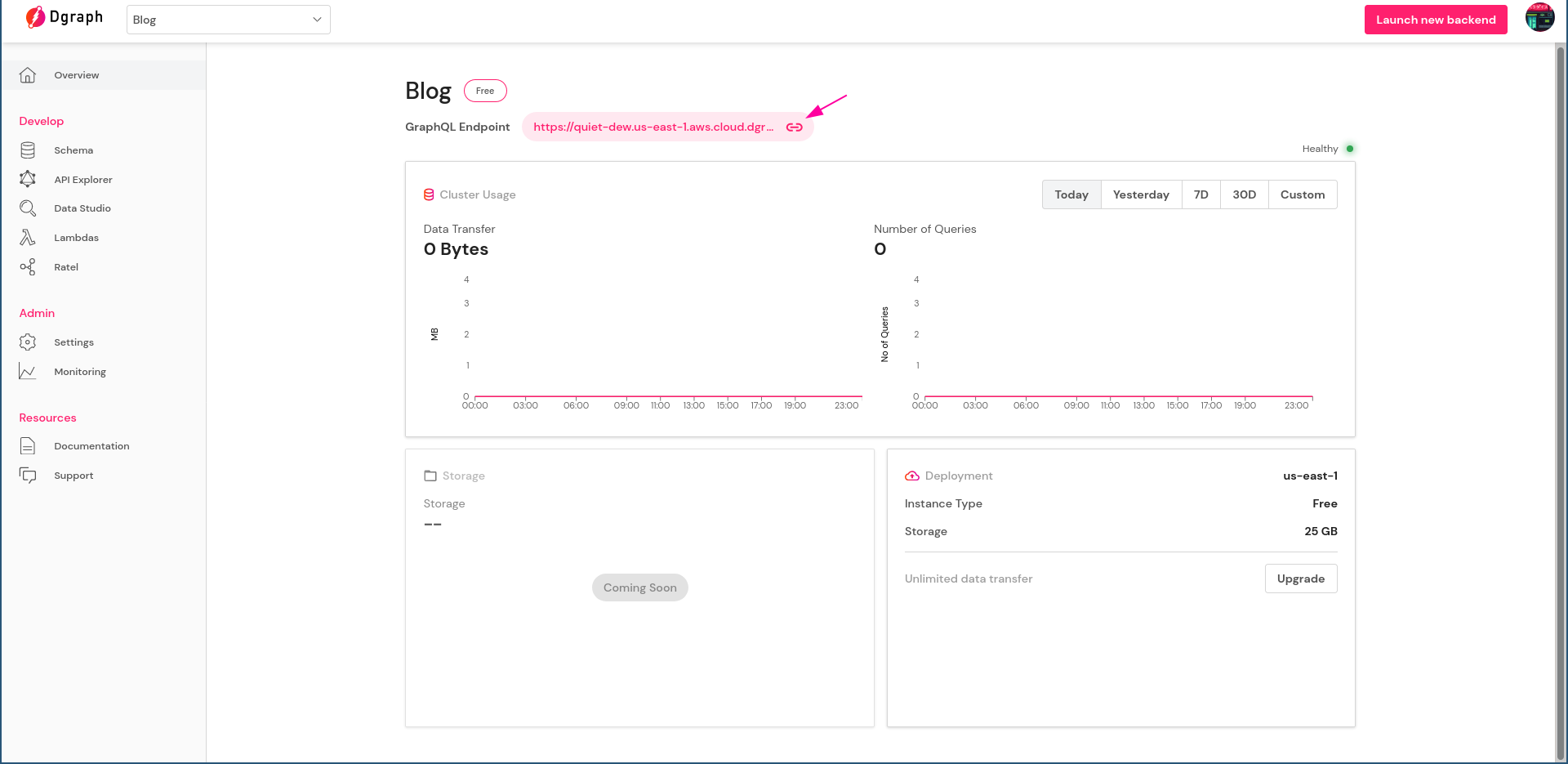
Click on the Schema from the left sidebar and paste the schema we just prepared:
type Article {
id: String! @id
title: String! @search
author: Author!
score: Int! @search
}
type Author {
id: String! @id
name: String! @search
articles:[Article] @hasInverse(field: author)
}
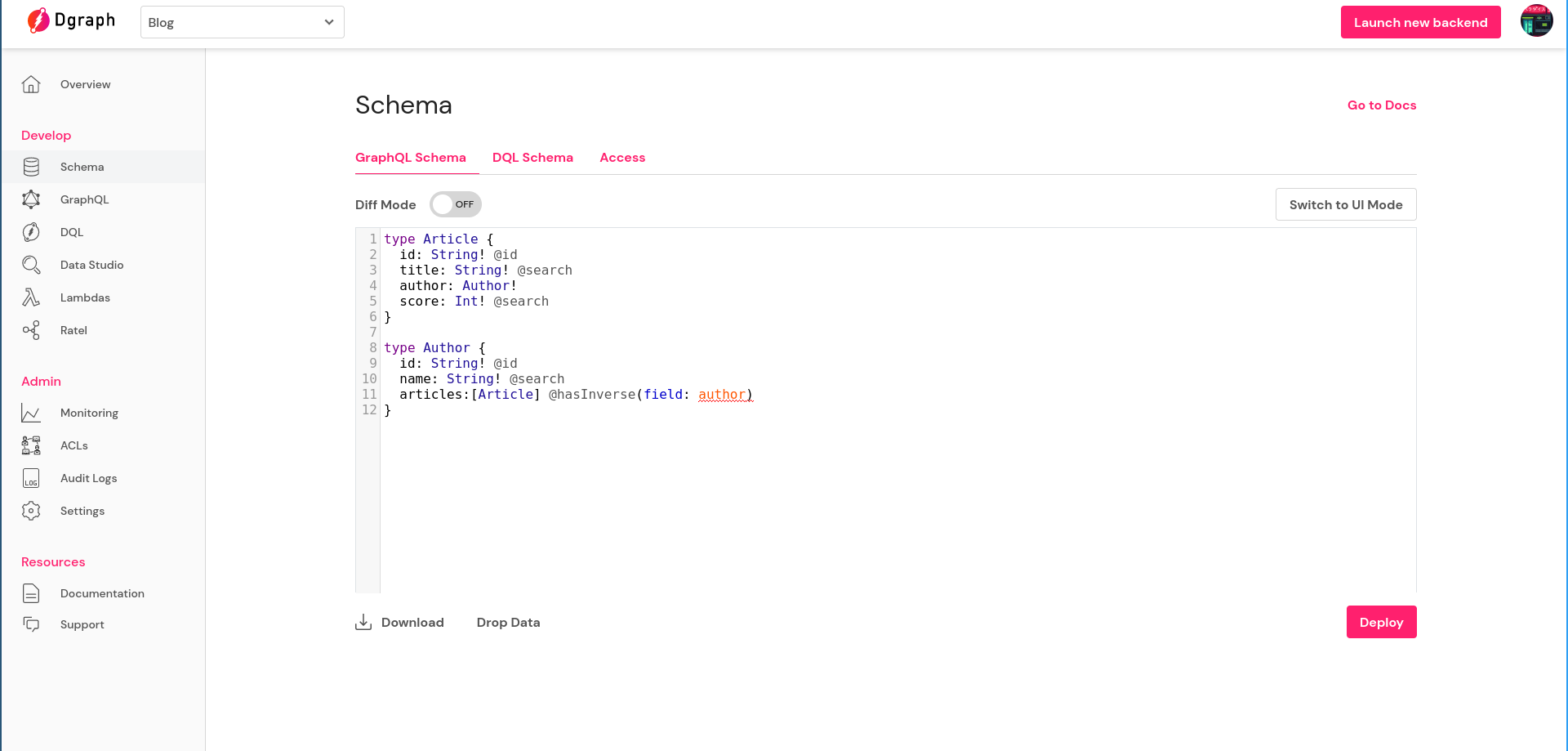
Then click on Deploy.
There you go! You now have a fully functional GraphQL API and a databasethat is ready to be used. You’ll see a dashboard with an overview of your backend (the Overview section on the left sidebar).
At this point, we don’t have any data. Let’s go ahead and add some sample data.
From your Dgraph Cloud dashboard, click on API Explorer. Then select Mutation from the Explorer section as the operation type and paste the following:
mutation AddAuthors($authorInput: [AddAuthorInput!]!) {
addAuthor(input: $authorInput) {
author {
id
name
articles {
title
score
}
}
}
}
You’ll also want to paste the following value for the authorInput into the query variable text area. That data will look like this:
{
"authorInput": [
{
"id": "0x1F",
"name": "Will Graham",
"articles": [
{
"id": "0x8E",
"title": "How to exit Vim",
"score": 8
},
{
"id": "0x10",
"title": "Vim scripts made easy",
"score": 7
},
{
"id": "0xBE",
"title": "The complete guide to Markdown",
"score": 9
},
{
"id": "0x1E",
"title": "Fish: The better shell",
"score": 9
}
]
},
{
"id": "0x1D",
"name": "Anthony Hopkins",
"articles": [
{
"id": "0x2",
"title": "How to get started with GraphQL",
"score": 9
},
{
"id": "0x5",
"title": "Authorization and authentication in Dgraph",
"score": 10
}
]
},
{
"id": "0x5A",
"name": "Manish R. Jain",
"articles": [
{
"id": "0x3",
"title": "Dgraph: GraphQL without the hassle",
"score": 10
},
{
"id": "0xB",
"title": "Building a native-GraphQL database",
"score": 10
}
]
},
{
"id": "0x8",
"name": "Howard Shore",
"articles": [
{
"id": "0x7C",
"title": "Concurrency and parallelism",
"score": 7
},
{
"id": "0x7A",
"title": "Understanding the Adapter Design Pattern",
"score": 7
}
]
},
{
"id": "0xE",
"name": "Jon Philips",
"articles": [
{
"id": "0x9F",
"title": "The future of machine learning",
"score": 5
},
{
"id": "0x10F",
"title": "MLOps: Things you should know",
"score": 7
}
]
}
]
}
Once your query and query variables are populated, hit Ctrl+Enter or click on the red Play icon.
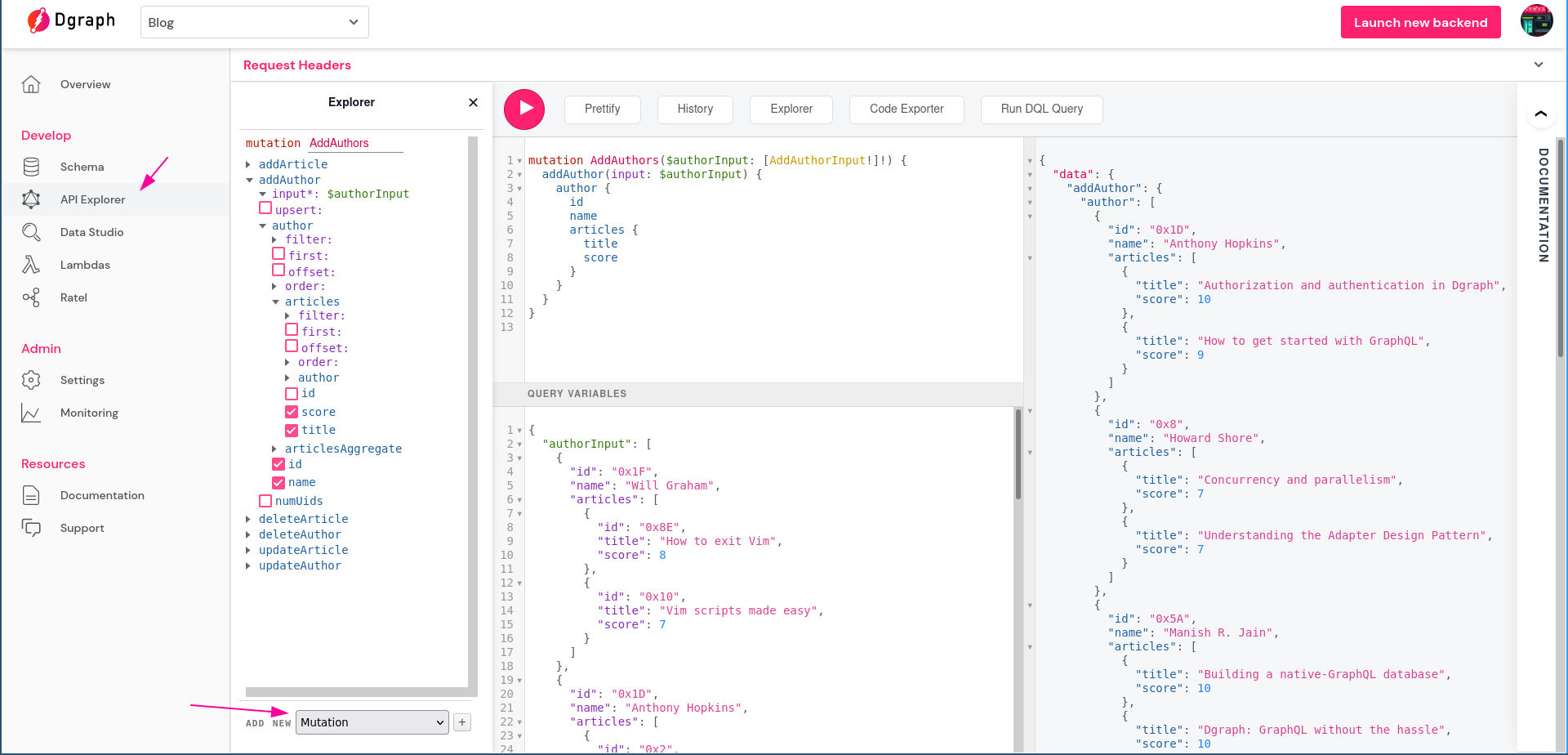
The @search directive tells Dgraph the type of search functionality to build into the API. We’ve attached this directive to several fields within the schema.
If you notice, you’ll see that the directive is attached to String and Int types. For Strings, Dgraph offers the following search options:
hashtermregexpexactfulltextYou can specify these as arguments to @search. For example, if you want the ability to search by regular expressions, you can do this:
type Author {
...
name: String! @search(by: [regexp])
}
Our schema doesn’t have any arguments to @search. In that case, the term option is used implicitly for String types, and lt, le, eq, in, between, ge, and gt options for Int types. We’ll discuss each of these options and how to use them for filtering in the subsequent sections.
From the mutation data above, we see that there’s an author with the ID 0x2. Let’s fetch the author’s details.
Select Query from the Explorer section and paste the following:
query {
getArticle(id: "0x2") {
id
title
author {
name
articles {
title
score
}
}
}
}
This gives us:
{
"data": {
"getArticle": {
"id": "0x2",
"title": "How to get started with GraphQL",
"author": {
"name": "Anthony Hopkins",
"articles": [
{
"title": "Authorization and authentication in Dgraph",
"score": 10
},
{
"title": "How to get started with GraphQL",
"score": 9
}
]
}
}
}
}
We can also filter by multiple IDs and fetch objects that match those IDs by using the in filter function.
For example, the following query requests articles with IDs 0x7A and 0x7C:
query {
queryArticle(filter: {id: {in: ["0x7C", "0x7A"]}}) {
id
title
score
author {
name
}
}
}
The response for this one is:
{
"data": {
"queryArticle": [
{
"id": "0x7C",
"title": "Concurrency and parallelism",
"score": 7,
"author": {
"name": "Howard Shore"
}
},
{
"id": "0x7A",
"title": "Understanding the Adapter Design Pattern",
"score": 7,
"author": {
"name": "Howard Shore"
}
}
]
}
}
The in function is useful for cases when you want objects that match specific field values, for example in this case ids. the in function works for any field that has the @id directive.
We could’ve declared the id field as the ID type, which is a built-in scalar type, in the following way:
type Article {
id: ID!
...
}
These IDs will automatically be generated by Dgraph. For ID scalar types, we can fetch by multiple IDs in the following way, without requiring the in function:
query {
queryArticle(filter: {id: ["0x1", "0x2", "0x3", "0x4"]}) {
id
title
score
author {
name
}
}
}
As mentioned earlier, with no arguments, the @search directive enables us to conduct searches based on one or more keywords (terms) for String types.
Dgraph has two utilities for this:
anyofterms andalloftermsallofterms searches for all the keywords that you specify in the query. In order to get a successful match, the field in question must contain all the terms.
For example, we can get a list of articles that has both GraphQL and Dgraph in their title:
query {
queryArticle(filter: {title: {allofterms: "GraphQL Dgraph"}}) {
title
score
author {
name
}
}
}
Let’s see the result:
{
"data": {
"queryArticle": [
{
"title": "Dgraph: GraphQL without the hassle",
"score": 10,
"author": {
"name": "Manish R. Jain"
}
}
]
}
}
Just as we expected!
On the other hand, anyofterms returns results that match any of the keywords.
Let’s fire the same query as before but using anyofterms instead.
query {
queryArticle(filter: {title: {anyofterms: "GraphQL Dgraph"}}) {
title
score
author {
name
}
}
}
Can you guess the results? This query asks for articles with titles that have either GraphQL or Dgraph in them. Each positive result should contain at least one of these two words.
{
"data": {
"queryArticle": [
{
"title": "Building a native-GraphQL database",
"score": 10,
"author": {
"name": "Manish R. Jain"
}
},
{
"title": "Dgraph: GraphQL without the hassle",
"score": 10,
"author": {
"name": "Manish R. Jain"
}
},
{
"title": "Authorization and authentication in Dgraph",
"score": 10,
"author": {
"name": "Anthony Hopkins"
}
},
{
"title": "How to get started with GraphQL",
"score": 9,
"author": {
"name": "Anthony Hopkins"
}
}
]
}
}
Both allofterms and anyofterms ignore case and special characters, meaning that you can write your keywords as graphql,dgraph or graphql&dgraph instead and it’ll still work.
Let’s explore the other options of searching other than by keywords. In order to do that, add the following modifications to the schema and re-deploy:
type Article {
...
title: String! @search(by: [regexp, fulltext])
...
}
type Author {
...
name: String! @search(by: [exact])
...
}
Notice that you can add more than one search option (except hash and exact; they can’t be used together). Here we’ve added both regexp and fulltext as options so that we can perform both types of searches on article titles. Notice that now you can’t use anyofterms or allofterms unless you specify the term option explicitly.
You can perform lexicographical searches on strings by providing the exact argument to @search in the schema. This exposes the following filtering functions for performing lexicographical search:
lt (less than)ge (greater than or equal)gt (greater than)From API Explorer, run the following query:
query {
queryAuthor(filter: {name: {ge: "H"}}) {
name
articles {
title
}
}
}
This will fetch Author objects whose names start with letters that are alphabetically greater than or equal to “H”. Notice the following results:
{
"data": {
"queryAuthor": [
{
"name": "Howard Shore",
},
{
"name": "Manish R. Jain",
},
{
"name": "Will Graham",
},
{
"name": "Jon Philips",
}
]
}
}
Both hash and exact provide the eq filtering function. This enables us to request for an object whose field value exactly matches the value we specify in the query.
For example, we can request for all the articles by “Howard Shore”:
query {
queryAuthor(filter: { name: { eq: "Howard Shore"}}) {
articles {
title
score
}
}
}
This yields:
{
"data": {
"queryAuthor": [
{
"articles": [
{
"title": "Concurrency and parallelism",
"score": 7
},
{
"title": "Understanding the Adapter Design Pattern",
"score": 7
}
]
}
]
}
}
We can use regular expressions for search on the title field due to the regex argument.
Execute the following query from API Explorer. This searches for articles containing the word “graph” or “Graph” in them:
query {
queryArticle(filter: {title: {regexp: "/(g|G)raph/"}}) {
title
}
}
This will fetch the following four articles:
{
"data": {
"queryArticle": [
{
"title": "Authorization and authentication in Dgraph"
},
{
"title": "How to get started with GraphQL"
},
{
"title": "Building a native-GraphQL database"
},
{
"title": "Dgraph: GraphQL without the hassle"
}
]
}
}
The fulltext option works like search engine searches, where you can specify space-separated words and it’ll match, regardless of case or special characters. Like term, this has two functions:
anyoftextalloftextFor the text you try to match against, anyoftext will yield results that match any part of that text, while alloftext matches the entire one.
The following query uses anyoftext to find articles whose titles contain “vim script”:
query {
queryArticle(filter: { title: { anyoftext: "vim script"}}) {
title
score
}
}
The result is both articles on Vim:
{
"data": {
"queryArticle": [
{
"title": "Vim scripts made easy",
"score": 7
},
{
"title": "How to exit Vim",
"score": 8
}
]
}
}
What happens if you do the same search but with alloftext?
query {
queryArticle(filter: { title: { alloftext: "vim script"}}) {
title
score
}
}
It will only yield one result:
{
"data": {
"queryArticle": [
{
"title": "Vim scripts made easy",
"score": 7
}
]
}
}
This is because the other article doesn’t contain the words “vim” and “script” side by side. alloftext tries to match all of the given text.
You can fetch authors whose names fit in a range, with the upper bound excluded. Notice the following query:
query {
queryAuthor(filter: {name: {between: {min: "H", max: "W"}}}) {
name
}
}
This gives:
{
"data": {
"queryAuthor": [
{
"name": "Howard Shore"
},
{
"name": "Manish R. Jain"
},
{
"name": "Jon Philips"
}
]
}
}
This is also possible on Int types. The @search directive doesn’t have any argument on the score field of Article. This makes the following filtering functions available, similar to how we saw for String types with the exact argument:
ltlegtgeeqbetweeninFor example, we can fetch articles with scores between 8 and 10:
query {
queryArticle(filter: { score: { between: { min: 8, max: 10}}}) {
title
score
author {
name
}
}
}
This returns seven articles:
{
"data": {
"queryArticle": [
{
"title": "How to get started with GraphQL",
"score": 9,
"author": {
"name": "Anthony Hopkins"
}
},
{
"title": "How to exit Vim",
"score": 8,
"author": {
"name": "Will Graham"
}
},
{
"title": "Authorization and authentication in Dgraph",
"score": 10,
"author": {
"name": "Anthony Hopkins"
}
},
{
"title": "Dgraph: GraphQL without the hassle",
"score": 10,
"author": {
"name": "Manish R. Jain"
}
},
{
"title": "Building a native-GraphQL database",
"score": 10,
"author": {
"name": "Manish R. Jain"
}
},
{
"title": "Fish: The better shell",
"score": 9,
"author": {
"name": "Will Graham"
}
},
{
"title": "The complete guide to Markdown",
"score": 9,
"author": {
"name": "Will Graham"
}
}
]
}
}
Notice that both lower and upper limits are included in the results.
You can combine searches and add filters as you traverse your data deeper to further fine-tune your results. For example, you can query for articles of a specific author with scores greater than 8:
query {
queryAuthor(filter: { name: { eq: "Will Graham" } }) {
name
articles(filter: { score: { gt: 8 } }) {
title
score
}
}
}
This gives:
{
"data": {
"queryAuthor": [
{
"name": "Will Graham",
"articles": [
{
"title": "Fish: The better shell",
"score": 9
},
{
"title": "The complete guide to Markdown",
"score": 9
}
]
}
]
}
}
In this article, I’ve tried to give you a taste of the search and filtering options Dgraph offers. You can take a look at the schema docs and query docs to learn more and how to use them to define search features of your API.
A flexible system of being able to filter through your data as you see fit on top of the unique philosophy of GraphQL, makes it a more powerful tool for various use cases. You get fast, efficient data fetching and a strong control over interpreting information from that data.
If all of this sounds good, check out Dgraph Cloud. It’s the fastest way to get started with GraphQL, with a rich set of features built-in. You don’t need to write a bunch of boilerplate code to set up a functional API, or worry about backend infrastructure. You just need a schema, and Dgraph Cloud takes care of everything else.
So sign up and start building today. We’ve also prepared a quick start for you to start sailing smoothly by building a todo application with Dgraph Cloud.
