
What Is Vertical Scaling
When your system starts to lag, you need a straightforward solution. Vertical scaling, or “scaling ...
Learn more

One of the cornerstones of Dgraph is that it allows a flexible schema, which
can be modified in a live system, without any downtime. This involves changing
data types and adding or removing indices with a single ALTER command to match
the needs of an application developer.
Dgraph supports indexing natively, which means common use cases around full-text search, regular expressions, date matching, geolocation queries, etc. can all be executed within Dgraph, while maintaining transactional guarantees. That is, once a transaction is committed, not only the data, but also the indices are updated and available to be queried. Indices are important to provide access to various functions that Dgraph supports. Users can specify the types of indices they want to build along with their schema. For example, take a look at the following schema:
name: string @index(term, exact) .
post: string @index(fulltext) .
The schema specifies two predicates. The name predicate has indices to check
for equality and for terms in a name. The post predicate on the other hand
generates an index that understands full text and is capable of checking for
related word (e.g a search for the word think would return posts with the word
thinking).
To build indices, Dgraph exposes a simple interface, called Tokenizer.
Every tokenizer has a unique name and identifier, supports a certain type of
data (int, float, string, date, geo, etc.), and is sortable and/or lossy. That
answers if the output from the tokenizer can be used to run inequality functions
(sortable) and if tokens do not match the value of data exactly (lossy). In the
above case, exact index tokenizer is sortable, and not lossy. term
tokenizer is not sortable and is lossy. Dgraph internally uses these to
determine how to best execute various queries.
Dgraph currently supports 13 tokenizers in total, including trigram for
regular expressions and geo for geolocation indexing. It also
allows users to further extend this list by creating their own custom tokenizers
and attaching them to Dgraph process via Go plugins. You can see the available
tokenizers and the functions they support here.
Previously, when the schema was updated, Dgraph searched if the list of
tokenizers (i.e term, fulltext) had changed and regenerated the entire index
if that was the case. A tokenizer refers to a strategy that is used to generate
tokens to insert into the index. For example, if {"name": "Barack Obama"}
was added, the exact tokenizer would generate a single token with
value Barack Obama while the term tokenizer would generate two tokens
(Barack and Obama). These tokens are used to generate a key that links
the token to the node containing the original data.
Rebuilding the entire index meant that Dgraph was performing a lot of extra work in cases where only a portion of the previous tokenizers were added or removed. As part of our continuous efforts to improve Dgraph, starting with upcoming version 1.0.12, only the parts of the predicate index that need to be modified are affected by schema updates. Along the way, we have refactored the reindexing logic to make it follow better coding practices and a more strict separation of concerns.
This blog entry will explore some of the strategies we used to clean up the code and eventually support partial reindexing.
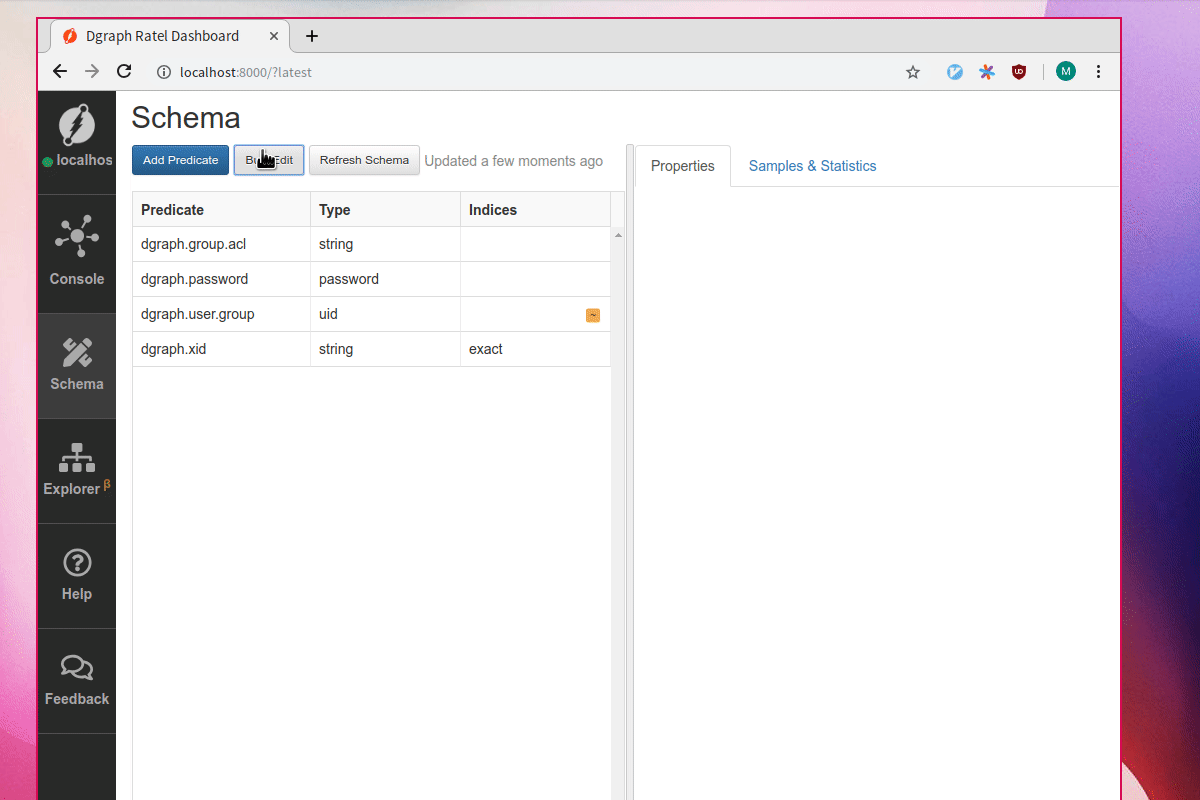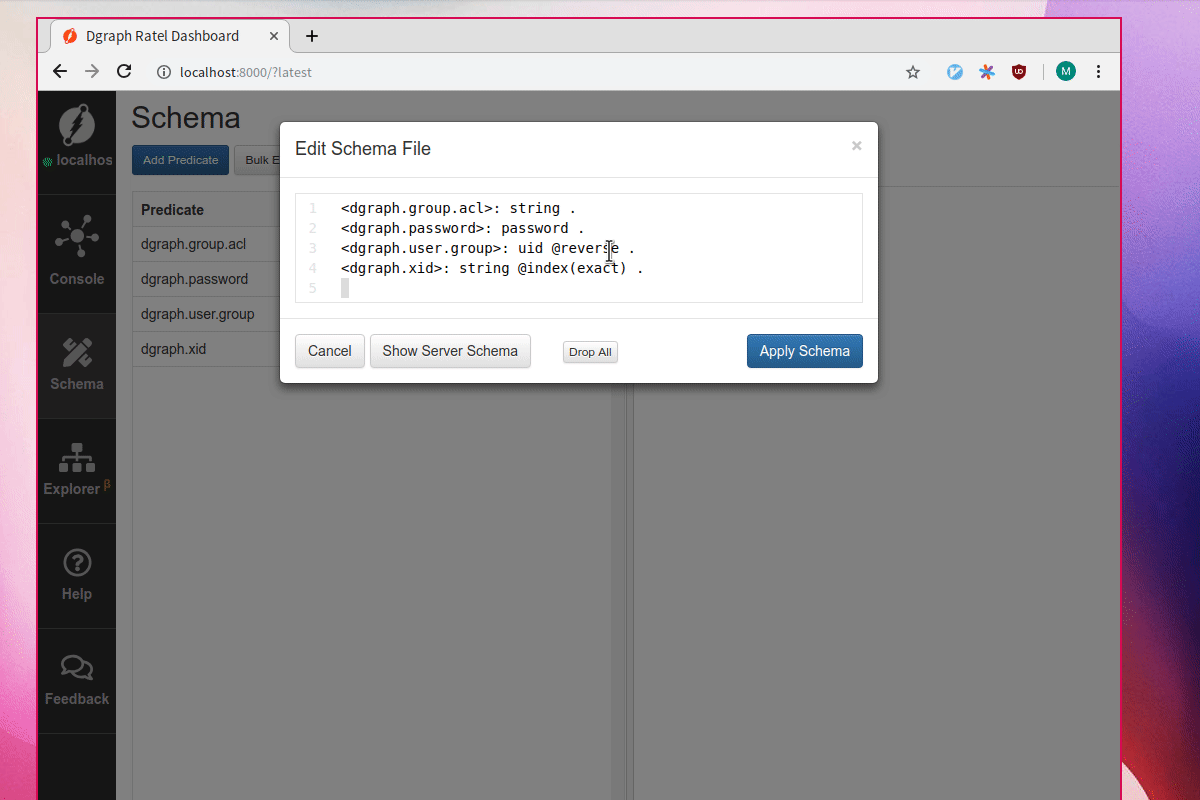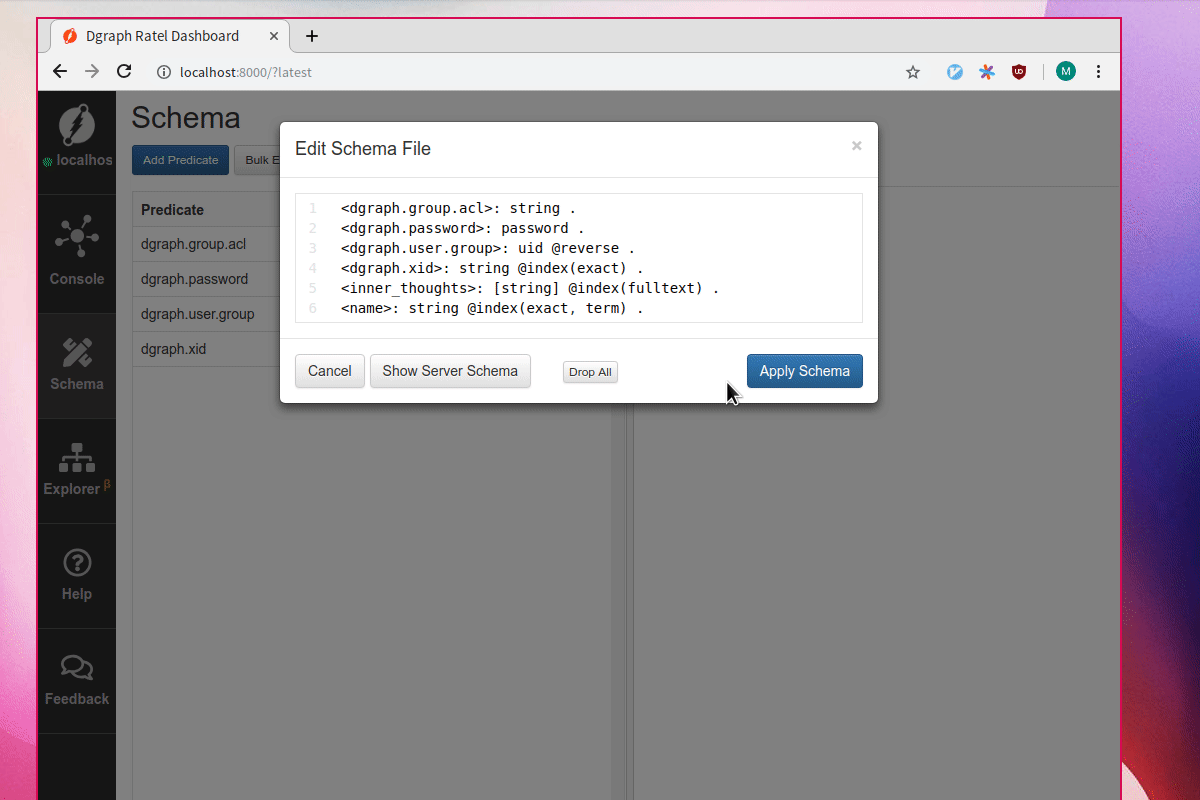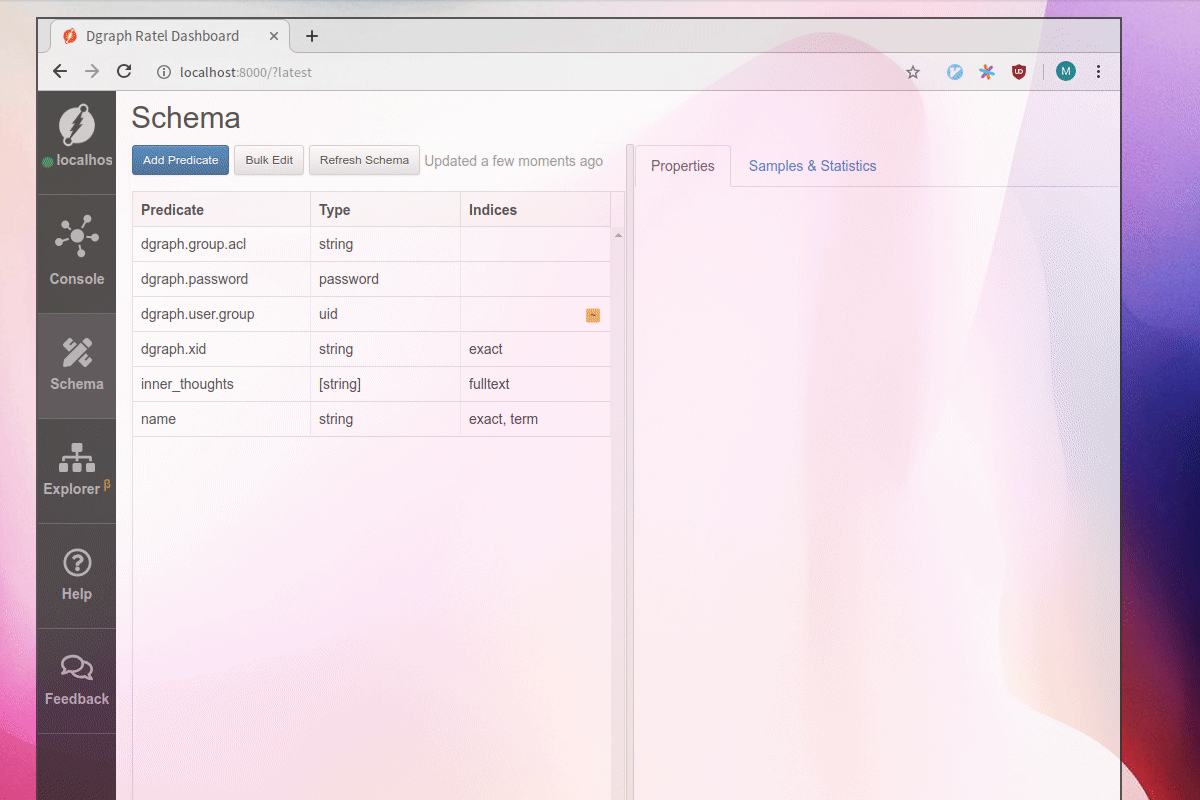
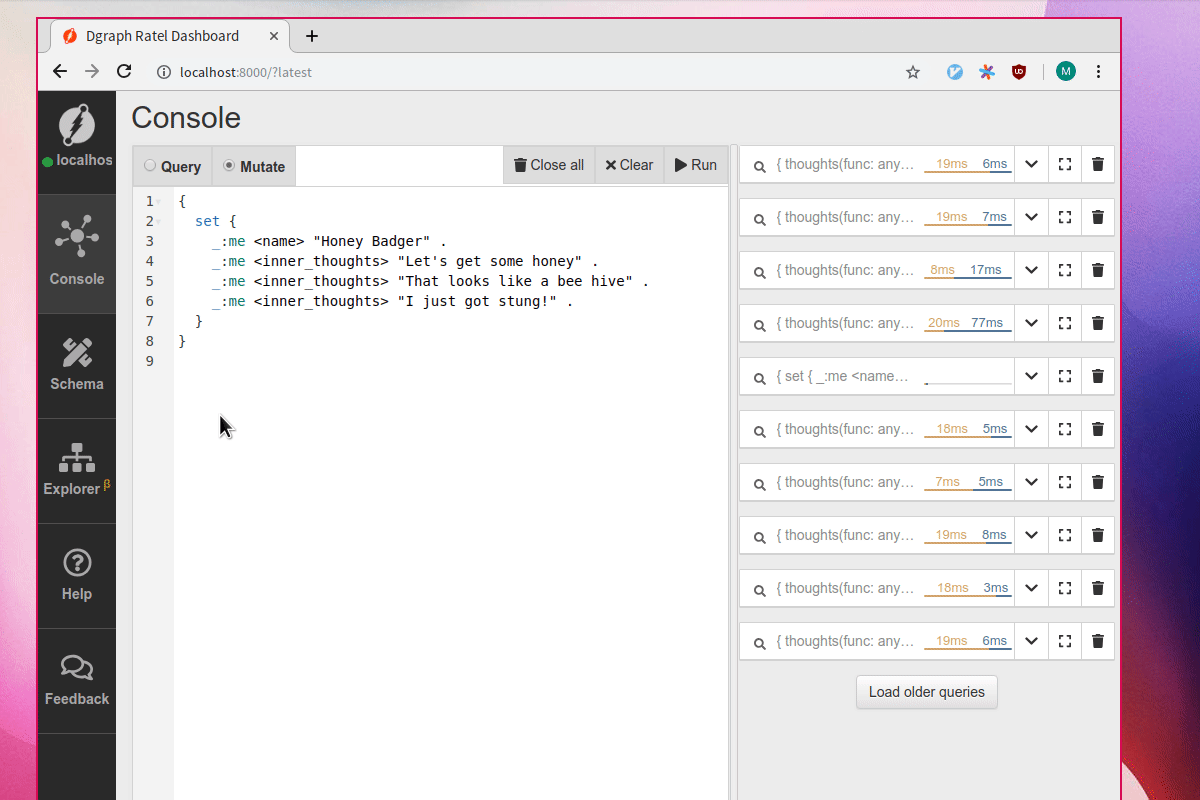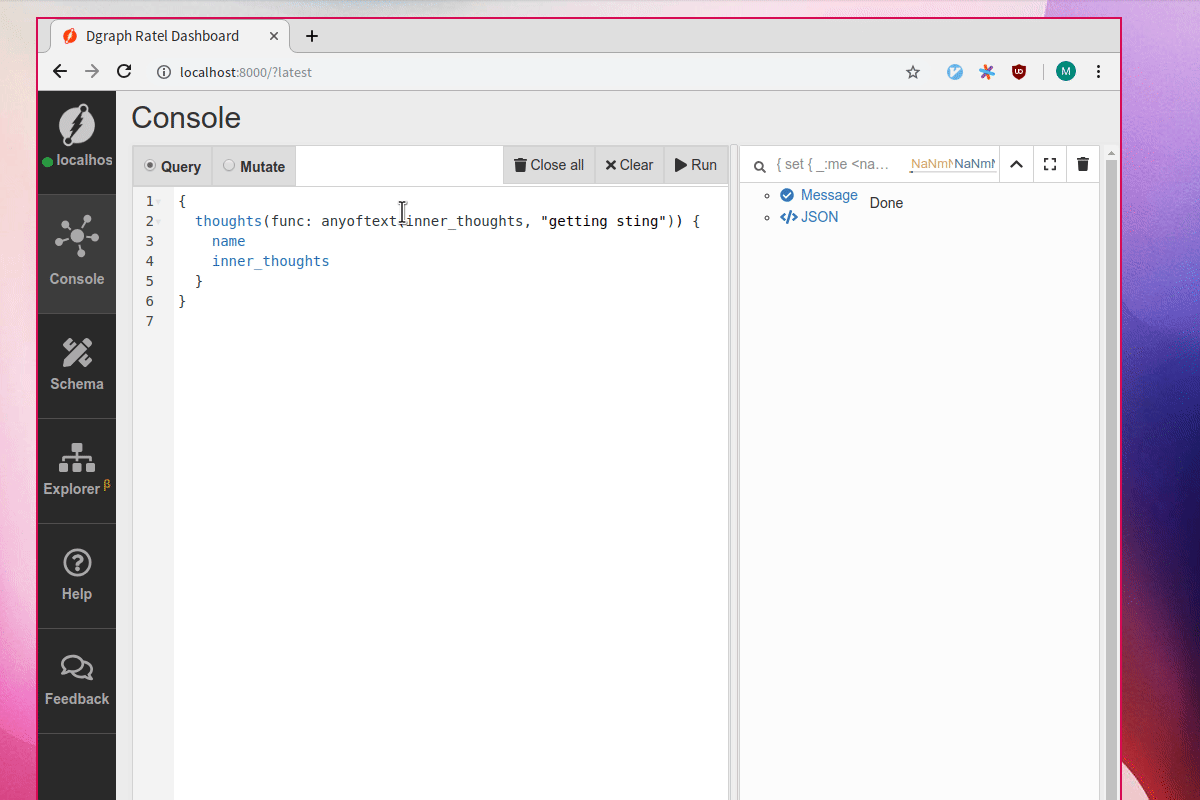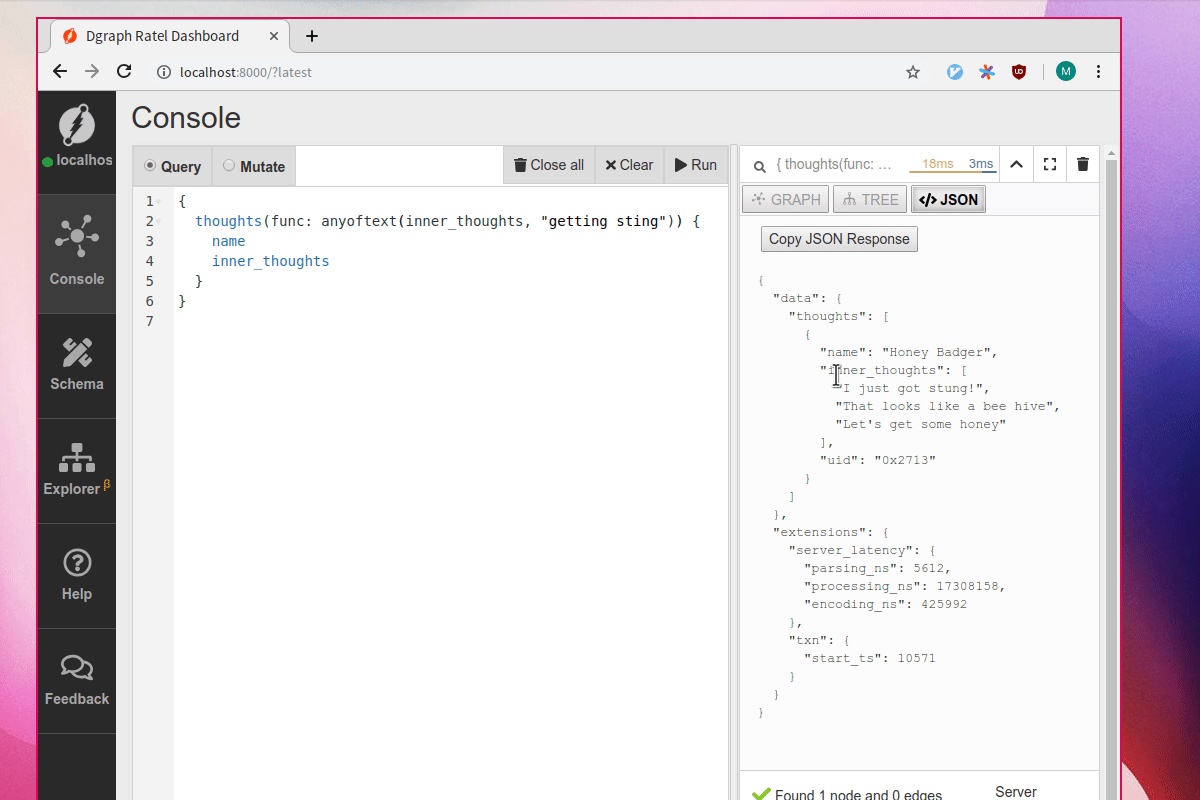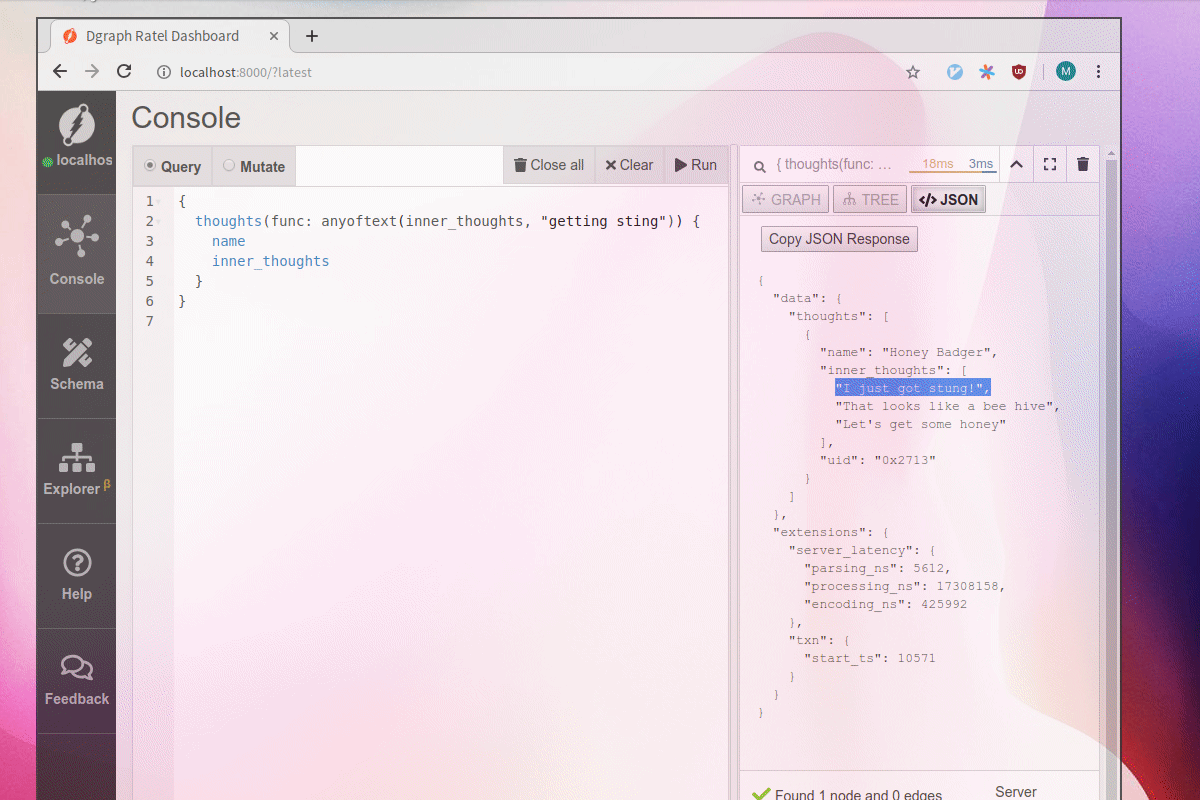
First let’s add two new predicates, name and inner_thoughts. Let’s index inner_thoughts with the fulltext tokenizer.
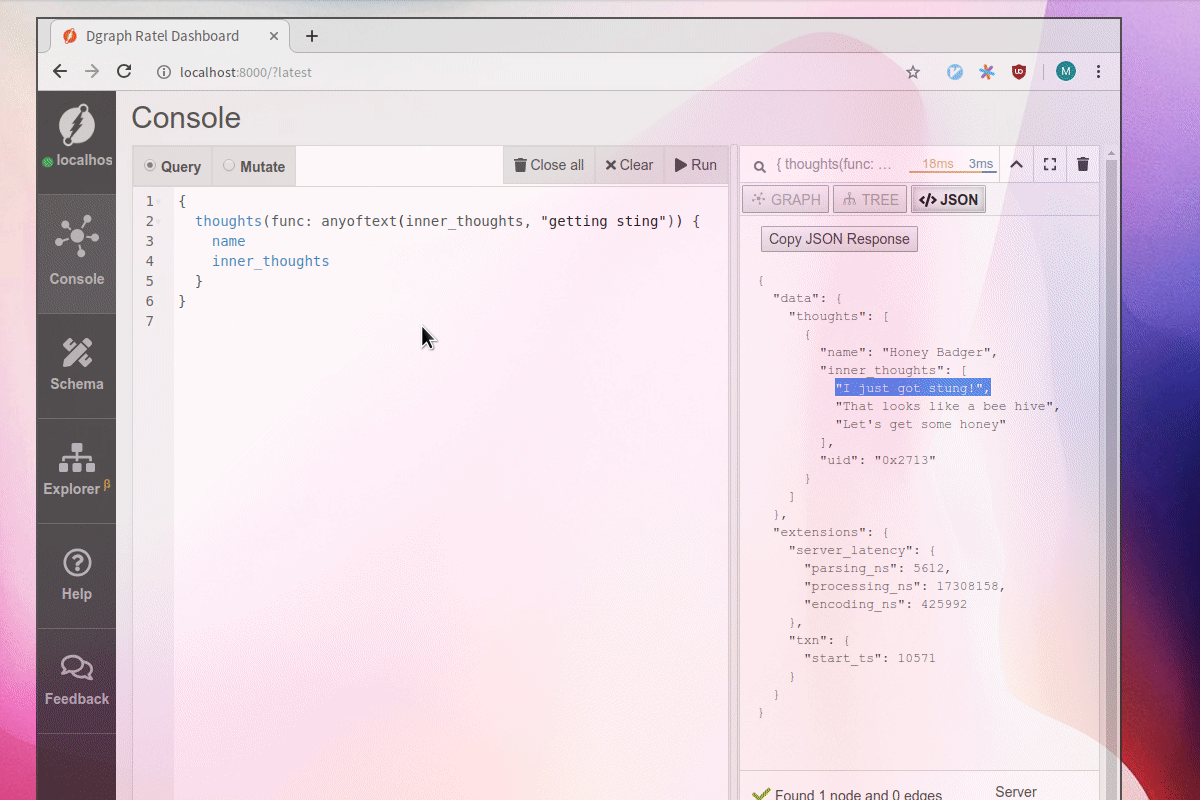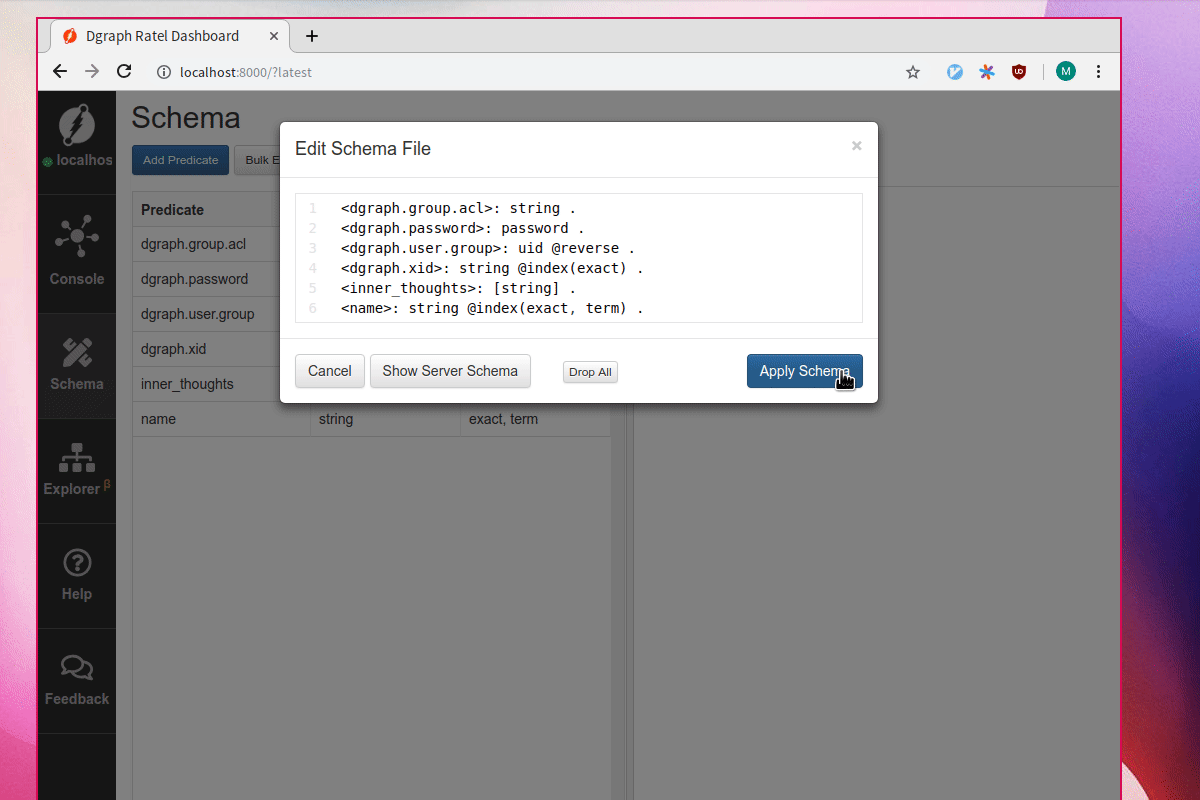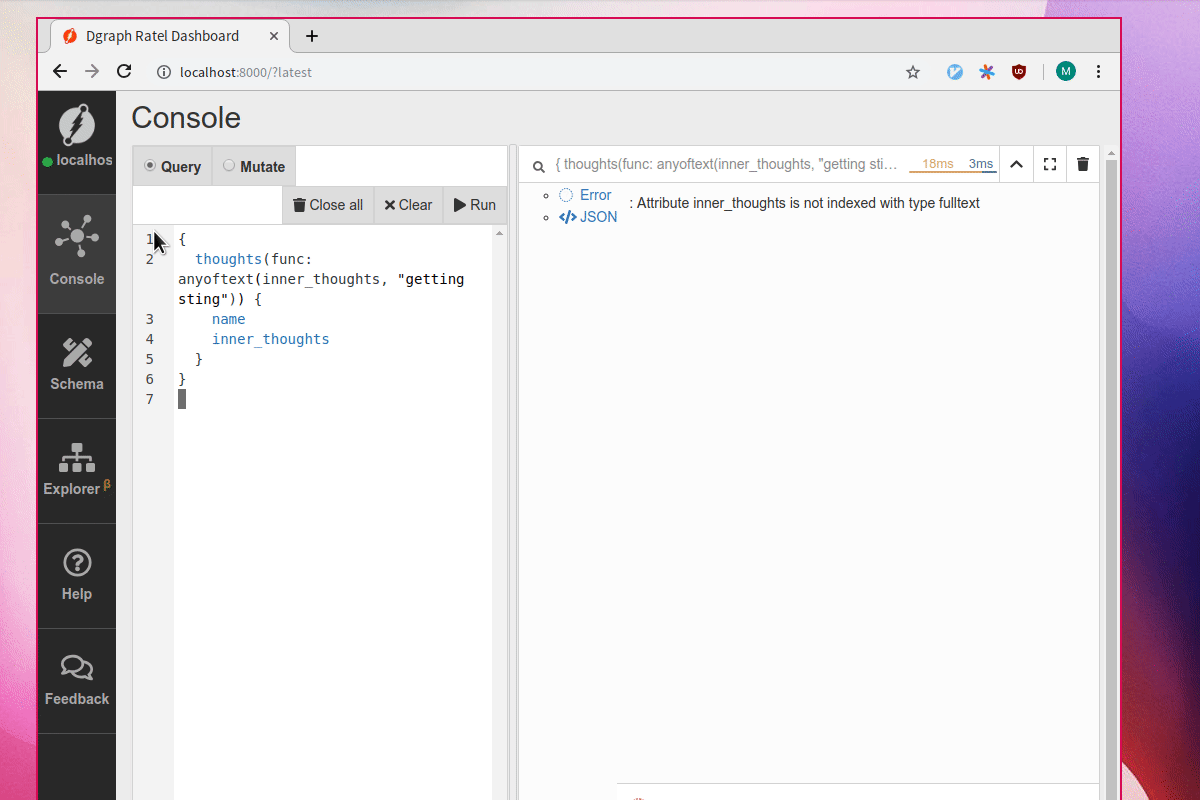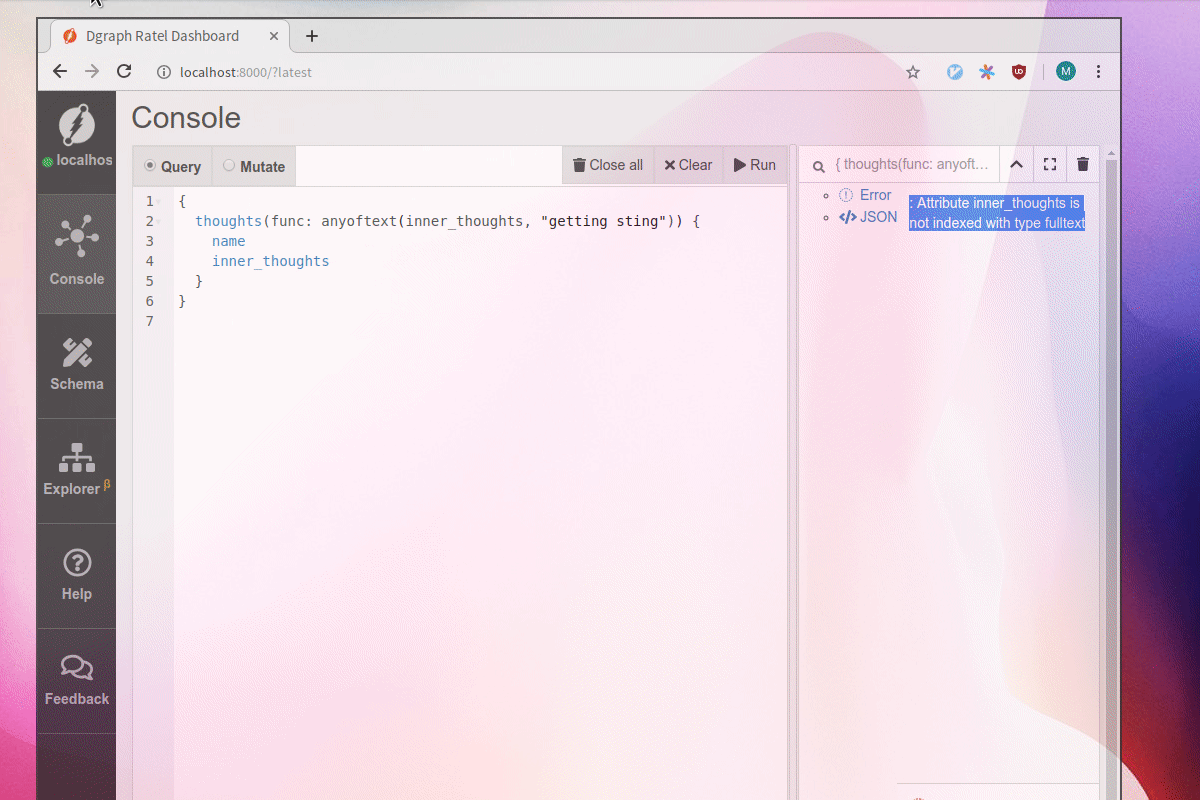
Let’s add a new node named “Honey Badger” and add its thoughts to the database.
Afterwards, we can query its thoughts using the fulltext capabilities.
For example, a search for “getting” will return this node because the words “get” and “got” appear inside the values of inner_thoughts.
Let’s delete some of the indices.
Afterwards, the previous query does not work anymore because it requires the fulltext index to function properly.
From the logs, we can observe that only the indices that changed were touched by the reindexing process.
Logs for adding schema (set fulltext on inner_thoughts and exact, term on name):
I0128 19:33:13.908820 1 index.go:700] Deleting index for attr inner_thoughts and tokenizers []
I0128 19:33:13.908853 1 index.go:718] Rebuilding index for attr inner_thoughts and tokenizers [fulltext]
I0128 19:33:13.908958 1 mutation.go:146] Done schema update predicate:"inner_thoughts" value_type:STRING directive:INDEX tokenizer:"fulltext" list:true
I0128 19:33:13.912481 1 index.go:700] Deleting index for attr name and tokenizers []
I0128 19:33:13.912511 1 index.go:718] Rebuilding index for attr name and tokenizers [exact term]
I0128 19:33:13.912672 1 mutation.go:146] Done schema update predicate:"name" value_type:STRING directive:INDEX tokenizer:"exact" tokenizer:"term"
...
Logs for modifying schema (deleted fulltext on inner_thoughts and exact on name):
I0128 19:33:40.578193 1 index.go:700] Deleting index for attr inner_thoughts and tokenizers [fulltext]
I0128 19:33:40.578261 1 mutation.go:146] Done schema update predicate:"inner_thoughts" value_type:STRING list:true
I0128 19:33:40.581631 1 index.go:700] Deleting index for attr name and tokenizers [term]
I0128 19:33:40.581695 1 mutation.go:146] Done schema update predicate:"name" value_type:STRING directive:INDEX tokenizer:"exact"
Previously, reindexing logic was split among three files.
worker/mutation.go: This file decided whether the reindexing needed to happen by comparing the old and new schema updates. The logic was different depending on whether the schema previously existed, further complicating things.
worker/index.go:
This file contained the reindexing functions that were called by worker/mutation.go.
These functions in turn were just very light wrappers around the functions in the postings package that do most of the work.
posting/index.go: This file contained the main logic to delete and rebuild the indices.
Before I embarked on the main task of supporting partial reindexing, I refactored the existing logic. Out of the gate, there were several avenues to simplify the logic.
worker/index.go could be removed entirely.
The file was little more than a wrapper around other functions and obfuscated the logic without offering a compelling argument to keep using it.
posting/index.go had multiple entry points to delete and rebuild each type of index (i.e reverse or count indices).
Instead, there should only be one exported function which decides which of these other functions should be called.
worker/mutation.go had different logic for new predicates than for predicates that existed already, even though a lot of this logic was replicated.
This file was also tasked with comparing the old and new schemas and deciding whether each type of index needs to be rebuilt.
However, this is something that could be easily be done in posting/index.go, which would hide a lot of complexity from the worker package.
The basic idea behind the refactor was to let worker/mutation.go simply compile a list of the required information to perform the rebuild and move most of the logic to posting/index.go.
I settled on the following struct:
type IndexRebuild struct {
Attr string // Predicate name.
StartTs uint64 // Start timestamp of the current transaction.
OldSchema *pb.SchemaUpdate
CurrentSchema *pb.SchemaUpdate
}
This struct has a single method called Run that executes the entire reindexing process, which allowed me to get rid of the file worker/index.go.
The functions that rebuild each type of index are called by Run, thus preventing the caller from being exposed to unnecessary details.
Each of these functions, figures out what operation (i.e. no-op, delete index, or rebuild index) needs to be performed. These functions share a similar pattern, expressed here in pseudo-code.
type indexOp int
const (
indexNoop indexOp = iota // Index should be left alone.
indexDelete = iota // Index should be deleted.
indexRebuild = iota // Index should be deleted and rebuilt.
)
func performRebuildOfSomeIndexType(rb *IndexRebuild) err {
op := rb.needsIndexRebuildOfThisType()
// Nothing to do so just return
if op == indexNoop {
return nil
}
// Logic to delete the index goes here
// In this case the index only needs to be deleted. For example, in the case
// a predicate is deleted entirely.
if op == indexDelete {
return nil
}
// Logic to rebuild the index goes here
}
indexOp is central to how I was able to get rid of the duplicate logic.
In the refactored code, a value of indexRebuild is returned when the schema is new or when the index needs to be rebuilt.
Thus, both cases can be handled by the same logic.
indexNoop and indexDelete do not cause the code to go into separate methods or large branches but rather cause the function to exit early depending on the circumstances.
At this point I had cleaned up the code, but functionally Dgraph worked just as
before. The function that adds the index tokens is called addIndexMutations
and is located inside posting/index.go. At this point the function generated
the new index using the complete list of tokenizers from the schema. So in order
to support partial reindexing I did the following.
needsIndexRebuild was changed to not just an operation but a list of
tokenizers whose tokens need to be deleted and a list of tokenizers whose
tokens need to be rebuilt.
These lists are computed by calculating the difference between the set of
current and previous tokenizers.
The function that deletes the existing index was modified so that it accepts the name of a tokenizer. This new function only deletes the entries that were previously added by that tokenizer. Deletion happens by calling that function over all the tokenizers marked for deletion.
addIndexMutations was changed to receive a list of tokenizers as a new argument (or rather, a new field in the struct passed to the function).
Only these tokenizers will be used to generate the tokens that need to be added to the index.
Interfaces should be as small as possible: Previously, the worker
package was exposed to a lot of the internal details of the logic inside the
postings package.
The split not only caused the code to be more difficult to understand but it
made the code brittle since changes inside of posting required changes to
other packages. After refactoring, the changes to support partial reindexing
were completely transparent to other packages to the point I did not have to
modify worker/mutations.go at all.
Structs are your friends: Functions arguments and return values can quickly get out of hand. The more arguments or return values a function has the more brittle it becomes during refactorings. Structs are a great way to reduce the number of arguments or return values by allowing us to aggregate related values under a single value. We give up a little safety since the compiler will not know which of the struct’s members are required to be passed or returned. However, the flexibility is worth the extra error-checking code.
Refactoring pays off: As mentioned above, investing time in simplifying the code eventually helped me implement partial reindexing a great deal. I could have tackled this task without refactoring, but I would only have made it more difficult for myself and for future contributors.
As we strive to improve the performance of Dgraph, it is also important that we manage and reduce the complexity of the code and follow best practices to the best of our ability. Not only does that make our jobs easier, but it makes our codebase more welcoming to newcomers.
As always, we welcome contributions and pull requests from the community.
