GraphQL Sorting: A Beginner's Guide
Sorting data in GraphQL is a powerful tool that enhances the usability and performance of your applicatio ...
Learn more

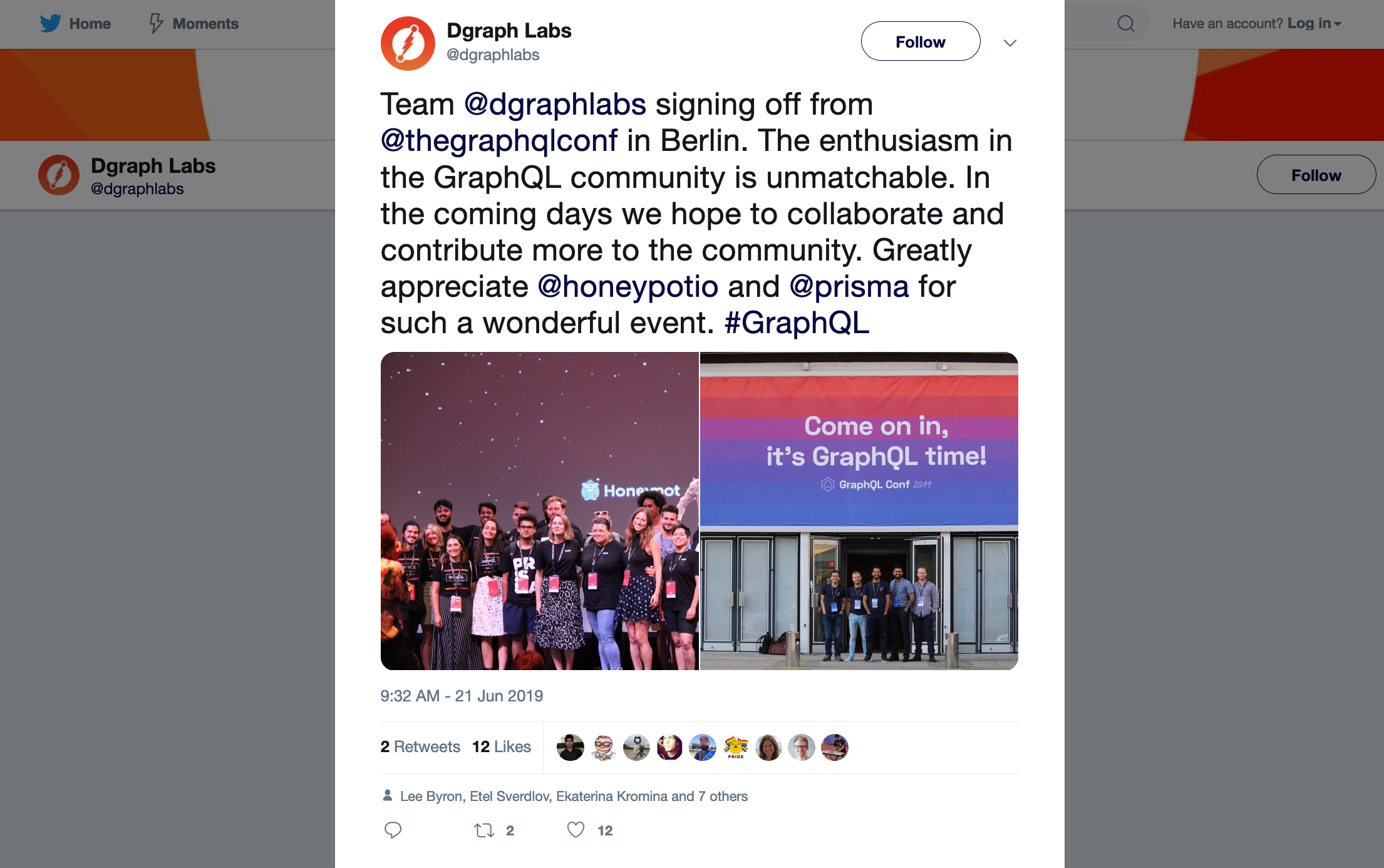
We took part in the recently held GraphQL conference in Berlin. The experience was fascinating, and we were amazed by the high voltage enthusiasm in the GraphQL community. Now, we couldn’t help ourselves from sharing this with Dgraph’s community! This is the story of the GraphQL conference in Berlin.
If you’re wondering what does Dgraph has to do with GraphQL, here’s the answer. Dgraph had set its eyes and placed its bet on GraphQL very early. Back in 2015, when GraphQL was still hot and new, we were intrigued by its intuitiveness and expressiveness to query application Graphs.
But, the simplicity of GraphQL makes it infeasible to express all database operations with it. Rather than exposing a subset of functionalities through complete GraphQL spec compatibility, we chose to sway away a bit, and this led to GraphQL+-. This love affair with GraphQL over the years has been full of flavors. But it never has been bitter :) The GraphQL community constantly desired for the full spec compatibility. And we obliged.
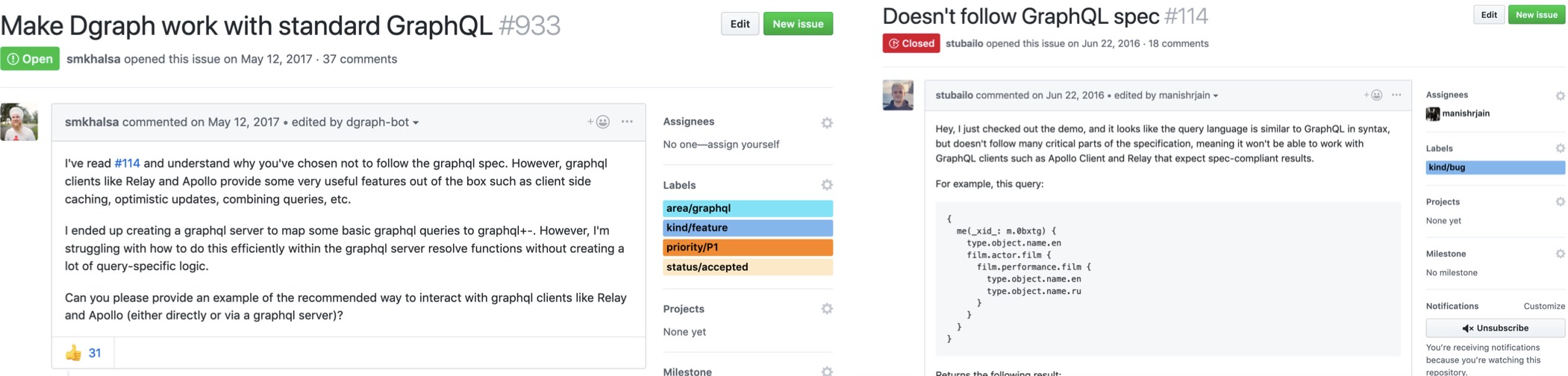
Dgraph is currently a member of the GraphQL Foundation. As we head towards shipping a layer that would completely adhere to GraphQL spec, we decided it was time for us to participate more actively within the GraphQL community.
The yearning to be amidst the community brought 5 of us from 4 different continents to fly to Berlin for the conference.
For most of us in the team, it was our first time in Berlin. The liveliness and vivacity of Berlin are indeed limitless.

As a precursor to GraphQL conf, we attended the Prisma day. The interaction with the Prisma team and the community was wonderful.

The first glimpse at the conference was thrilling! It was all set for a splendid show.

The talks touched upon a diverse set of topics, here are the broad categories,
History and reasons why GraphQL kicked off in one’s company or how GraphQL brings efficiency to their existing practices. These talks took us through the GraphQL journey, the set of pain points one faced in their organizations, and how the adoption of GraphQL solved it.
The co-creators of GraphQL, Dan Schafer and Lee Byron took the audience through their journey at Facebook during which GraphQL evolved
One of the real advantages of adhering to GraphQL spec is its rich ecosystem of tooling.
Here’s one such talk around GraphQL tooling,
Some of the talks touched upon scaling challenges with GraphQL. These talks were particular interest to us. I’ll dig more into why later in the article.

The GraphQL documentary screening was one of the highlights of the conference.

We didn’t miss the chance to live-tweet the event :) Here are the threads,
The show was indeed a GraphQL carnival. A big shoutout to [Etel Sverdlov] https://twitter.com/etelsverdlov, Ekaterina Kromina, and Johanna Dahlroos. The three wonderful organizers who made the event a grand success.

The adoption and growth of GraphQL have been tremendous. The community is very enthusiastic and dynamic. We are witnessing a trend wherein a large number of companies are gearing up to adopt GraphQL at scale.
GraphQL encourages one to think, visualize, and query by imagining an entire organization’s data as one big graph, and this changes the whole view of one’s business domain. In a short period post GraphQL adoption, one would be implicitly accustomed to think “Graph"ically! In due course, there is a great possibility that the nature of the database and server-side workloads start to change.
But it looks evident that amidst the GraphQL excitement, the new set of challenges that could potentially be posed by the change in the nature of workload at the database layer has been underplayed.
The staggering adoption of GraphQL has renewed the need for a distributed engine which in one sweep could resolve arbitrary depth GraphQL queries, without having to compromise on the scale, throughput, and speed.
Hence, we are excited about the way GraphQL has kicked off in the last couple of years. We look forward to making active participation and impactful contributions to the vibrant GraphQL community.
We signed off with impressions of great experiences and the mandatory bye bye tweet :)