
GraphQL Sorting: A Beginner's Guide
Sorting data in GraphQL is a powerful tool that enhances the usability and performance of your applicatio ...
Learn more
Dgraph’s flagship product is a native graph database written purely in Go. For any database product, the query language is at its heart that provides access to the stored data. Without a robust and error-free query language, the database has little to no value. Enabling Fuzzing on this query language is of immense value to Dgraph as a database company that people have come to love and rely upon. And doing so cheaply and continuously is the cherry on top!
One of the first projects I worked on at Dgraph was to introduce Continuous Fuzzing in our CI/CD pipeline. This article will walk you through the entire journey. It will introduce Fuzzing and the benefits of Continuous Fuzzing followed by a brief overview of the fuzzing tools; go-fuzz, a go based fuzzer and Fuzzit , a service that offers continuous fuzzing as a service. Finally, I list the steps on how these tools were stitched into our CI/CD pipeline to enable Continuous Fuzzing and what future improvements can be made.
Fuzzing (or Fuzz Testing) is a black box automated software testing method. It is generally used to test software that parses complex inputs that follow a particular format, protocol, or are otherwise structured. Any crash, exceptions, memory leaks, or assertions are reported as bugs in the software. From a security standpoint, Fuzzing is also used to uncover security vulnerabilities in programs that parse inputs from untrusted sources (e.g., from the internet).
Fuzzing for long periods without any bugs being reported increases the confidence in the stability of the code. However, no amount of Fuzzing can guarantee an absence of bugs in the code. On the other hand, a bug reported by Fuzzing is a genuine issue that should be fixed and never a false positive.
Fuzzing is a good candidate for some classes of software. Especially the ones that include networking protocols, file formats, and query languages. These software classes require input to follow a strictly defined format adhering to the specifications defined in an RFC/IETF, a Standard, formal Grammar, or finite state machine.
Dgraph uses a query language named GraphQL+-. It is a derivative of Facebook’s GraphQL specification since GraphQL’s graph-like syntax makes it suitable as Dgraph’s query language of choice. The gql package in the Dgraph repository parses the queries sent by its clients such as Ratel and dgo over the network. This package is an ideal candidate for fuzz testing the robustness of the query parser method.
Continuous Fuzzing, as the name suggests, incorporates Fuzzing in a CI/CD pipeline. The ability to continuously fuzz testing unlocks several benefits.
A Fuzzer is defined as the test driver that blasts a large variety of inputs in a short span of time to the program under test and observes the outcome for crashes or bugs. The beauty of Fuzzers and where Fuzz testing shines is that the Fuzzers automatically generate new inputs based on the initial seed inputs (called seed corpus). Fuzzers can be generation-based or mutation-based, depending on whether inputs are generated from scratch or by modifying existing given seed corpus. The latter is more common.
go-fuzz is a mutation-based fuzzer, i.e., it generates new inputs based on existing seed inputs (a.k.a seed corpus). It is coverage driven. So, if an input increases the code coverage, then it is considered interesting, added to the corpus and mutated upon to generate additional inputs to test. The diversity of inputs in the seed corpus is key to getting the most out of the go-fuzz testing tool.
go-fuzz is a fuzzer for Go packages. Since Dgraph is a pure Go-based Graph database, it is a good choice for us to use it for fuzz testing.
At Dgraph, we used go-fuzz to create an archive file that can be used with libFuzzers, an in-process, coverage-guided, evolutionary fuzzing engine.
At Dgraph, we used fuzzit that enables continuous fuzzing as a service. In the simplest terms, fuzzit is a SaaS platform that executes an authenticated fuzzer indefinitely, runs reports, and makes the seed and current corpus available to download. It also allows running the current corpus against the code under test to check for any regressions locally and synchronously with the CI. The platform updates logs every minute and merges the corpus every hour between all workers automatically. It focuses on making sure bugs are fixed and alerts you if bugs are introduced again in a pull request.
Technically, fuzzit is a wrapper on libFuzzer that operates on the archive file generated by go-fuzz and provides a CLI agent to interact with the service. As we shall see below, the service is very easy to use and integrate with any CI.
Here are the steps that I implemented to get the Continuous Fuzzing up and running.
1. Fuzz Function to integrate go-fuzz
We wanted to test the query parser in the gql Go package. The first step was to create a Fuzzing function of the form below that is needed as the hook for go-fuzz
func Fuzz(data []byte) int
The snippet below shows the Fuzz() function in the gql package’s parser_fuzz.go file.
const (
fuzzInteresting = 1
fuzzNormal = 0
fuzzDiscard = -1
)
func Fuzz(in []byte) int {
_, err := Parse(Request{Str: string(in)})
if err == nil {
return fuzzInteresting
}
return fuzzNormal
}
This function is very simple. It calls the query Parse() method which is the main entry point for GraphQL+- query parsing that we wanted to fuzz test. If a query was parsed successfully, we return 1 indicating an interesting input that is valid and should be added to the corpus. Otherwise, it is 0.
2. Seed the initial corpus
As mentioned earlier, go-fuzz will be far more effective if the initial seed corpus is robust and diverse. We started with a set of 207 query samples as our initial seed corpus. This corpus was manually added by our engineering team. Shown below is the size of the initial seed corpus in use at Dgraph.
paras@pshahX1:~/go/src/github.com/dgraph-io/dgraph/gql/fuzz-data/corpus$ ls -l | wc -l
207
At this point, we have everything needed for go-fuzz to do its magic. The next step is to incorporate it in a Continuous manner.
3. Build a fuzzit target
To get started with the fuzzit SaaS platform, I created an account on https://app.fuzzit.dev/. This account will then spit out an API key, FUZZIT_API_KEY, that can be used for authentication and to access the service. Needless to say, the API key must be kept safe and secret.
Further, this account allows for creating fuzzing targets. Targets allow multiple fuzzing jobs to be run on different projects and is a form of segregation. These targets, along with the FUZZIT_API_KEY, allows executing long running fuzzing jobs on the platform as well as local-regression jobs.
For Dgraph, I created just one target parser-fuzz-target for the gql package fuzzing.
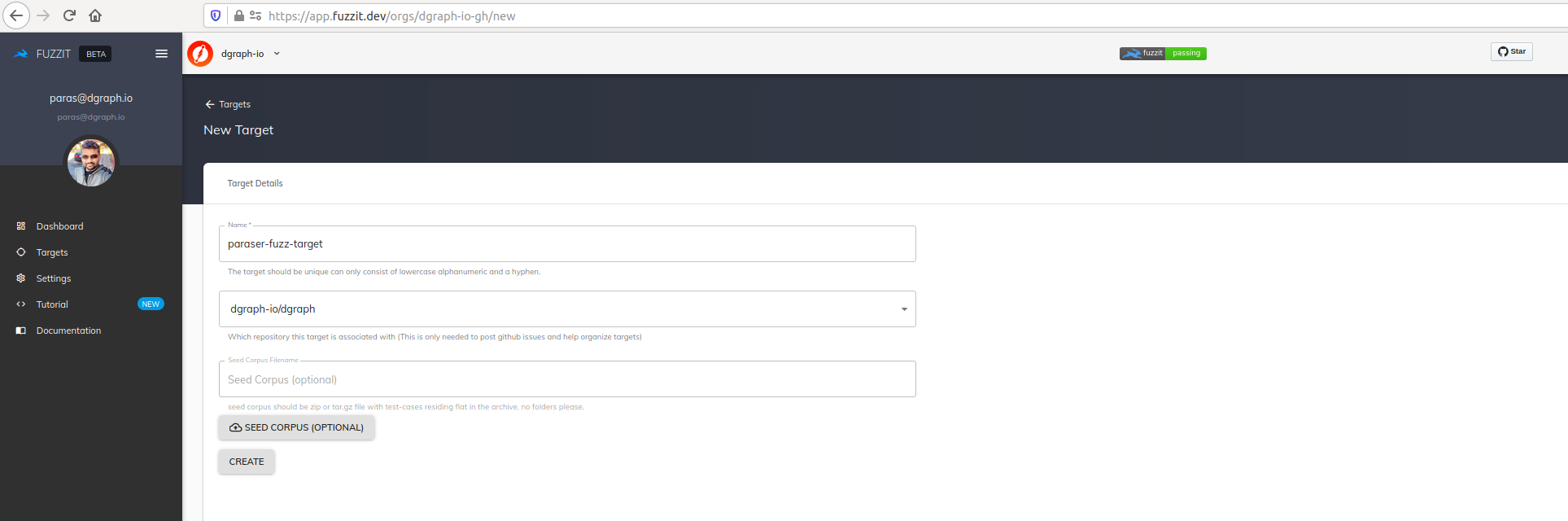
Note: Alternatively, fuzzit has a CLI agent, also called fuzzit that allows for target creation. For example,
./fuzzit create target --seed ./gql/fuzz-data/corpus.tar.gz parser-fuzz-target
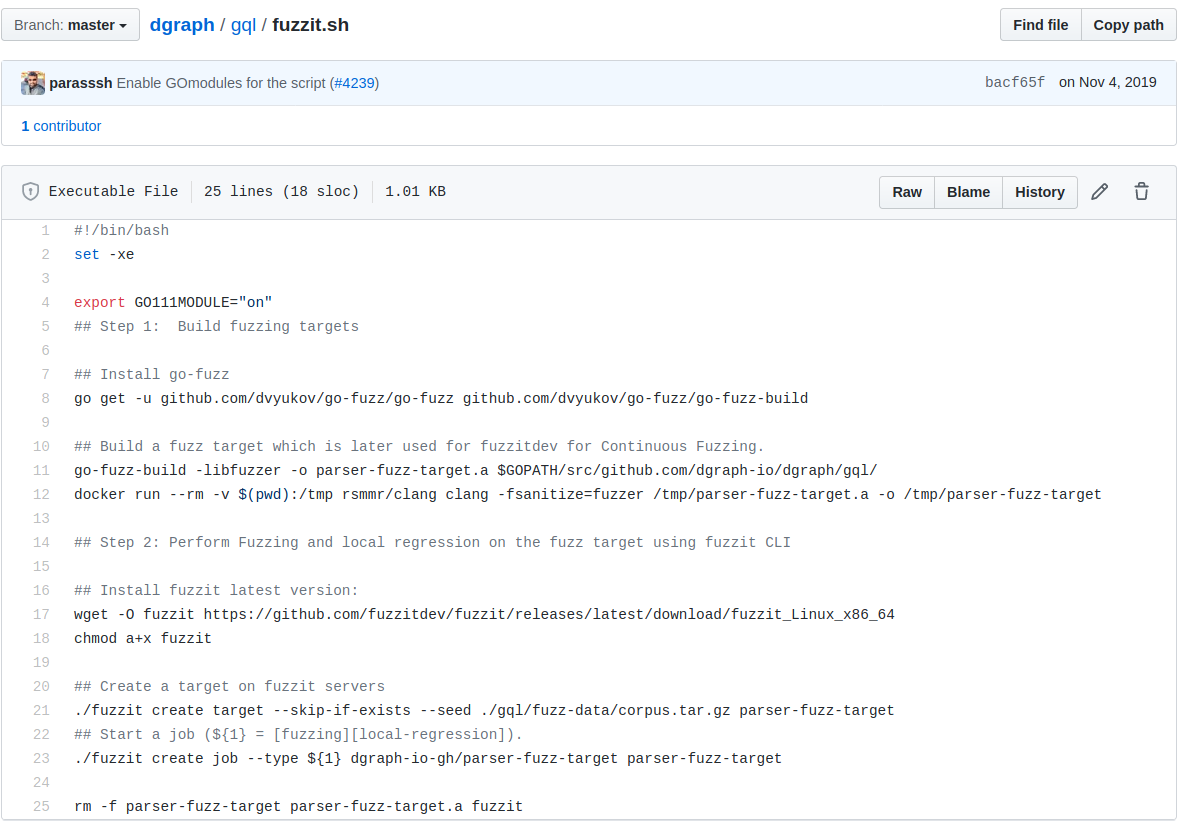
4. fuzzit.sh Script
I wrote a simple script, fuzzit.sh, that stitches everything together. It is basically a wrapper on go-fuzz and fuzzit CLI. The script uses go-fuzz to create an archive for use with libFuzzer which in turn then spits out a fuzzing target parser-fuzz-target locally. It then uses the fuzzit CLI to start the fuzzing or local-regression jobs.
The script usage is as follows:
usage: fuzzit.sh [local-regression | fuzzing]
local-regression : A local job that runs the corpus against the target.
fuzzing : A long running asynchronous job on the fuzzit platform.
and its contents are in the screenshot below:
5. Fuzzing CI Step
The last step is to invoke the fuzzit.sh script from the CI platform. In the case of Dgraph, we use TeamCity for CI.
First, Set FUZZIT_API_KEY as an environment variable on the Team City platform parameters (not shown here). Next, I, then, added a Fuzzing CI Step. This step is a very simple custom script that simply invoked fuzzit.sh script described above as follows.
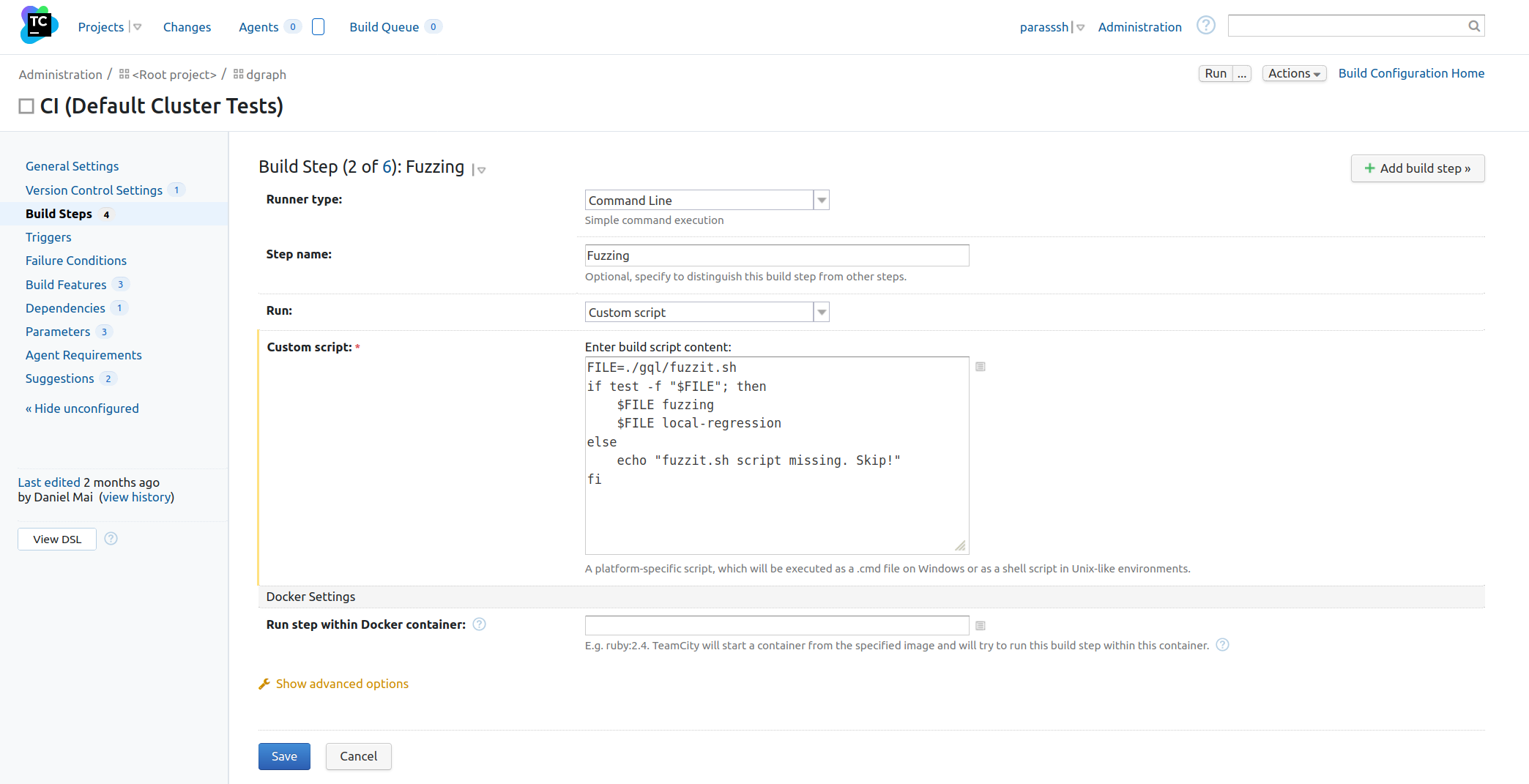
As seen in the screenshot above, it invokes the fuzzit.sh script twice for every PR, once for the fuzzing job and once for the local-regression job. They are explained below.
a. Fuzzing Job: For every PR, a new fuzzing job is started and the last one is stopped. This is a never-ending job running on the fuzzit server. Any crashes are reported on the fuzzit dashboard and alerted back to us. These are real bugs that must be fixed. The input (in binary and quoted text format) that caused the crash and the output from the crash is available on the fuzzit dashboard. Note that this does not block the PR.
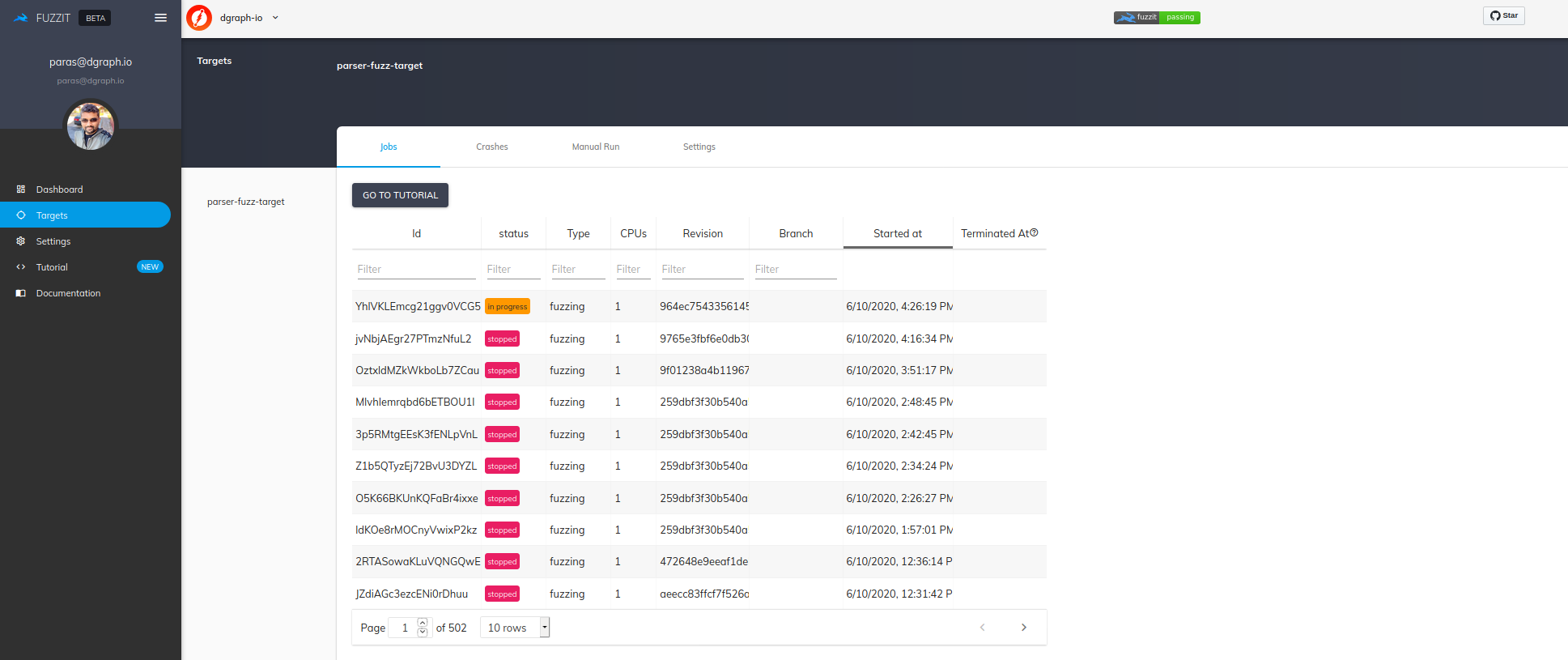
b. Local-Regression Job: It downloads the latest/current corpus from fuzzit servers and runs each input locally against the gql package. Any failures are reported and are an indication of a regression. The CI Fuzzing step will fail and the PR will be blocked. NOTE: This is not fuzzing. It only executed the gql package against a fixed set of inputs from the corpus that fuzzing helped build. See below for a local-regression run for the gql package.
paras@pshahX1: export FUZZIT_API_KEY=******; ./fuzzit.sh local-regression
+ export GO111MODULE=on
+ GO111MODULE=on
+ go get -u github.com/dvyukov/go-fuzz/go-fuzz github.com/dvyukov/go-fu
...
<snip>
...
FUZZER: ./fuzzer: Running 3707 inputs 1 time(s) each.
FUZZER: Running: corpus/000ccc6e7a16d33a59788db251204211934ff8e8
FUZZER: Executed corpus/000ccc6e7a16d33a59788db251204211934ff8e8 in 0 ms
...
...
...
FUZZER: Executed seed/corpus/test178.in in 0 ms
FUZZER: Running: seed/corpus/test179.in
FUZZER: Executed seed/corpus/test179.in in 0 ms
FUZZER: ***
FUZZER: *** NOTE: fuzzing was not performed, you have only
FUZZER: *** executed the target code on a fixed set of inputs.
FUZZER: ***
FUZZER: stat::number_of_executed_units: 3707
FUZZER: stat::average_exec_per_sec: 0
FUZZER: stat::new_units_added: 0
FUZZER: stat::slowest_unit_time_sec: 0
FUZZER: stat::peak_rss_mb: 42
2020/06/10 17:46:55 Waiting for container
2020/06/10 17:46:55 Regression for parser-fuzz-target took 18.255644498s seconds
+ rm -f parser-fuzz-target parser-fuzz-target.a fuzzit
(Note: the FUZZIT_API_KEY in the snippet above is redacted. You need to paste your API KEY.)
As seen from the output, the local-regression ran the corpus against the gql package. An interesting observation to make is that the current corpus now consists of 3707 inputs growing from the initial 207 inputs in the seed corpus that we started with. Fuzzing found ~3500 more inputs for us. This is the power of fuzzing in action!
And that was it. We now have successfully incorporated Continuous Fuzzing for every Pull Request coming in on Dgraph’s GitHub repository.
The following are some best practices to follow.
fuzzit. This is the gold mine consisting of hours and hours of fuzzing test inputs which can be used to re-seed and also for regression testing.fuzzit should be addressed. They indicate real issues. In our case, we have yet to find a bug in the gql package since Continuous Fuzzing was introduced. This is great and speaks to the robustness of the parser.While what was achieved is a good place to be, there are some future enhancements/improvements that can be made. Listed below are some of them:
Improving Seed Corpus Diversity: In our case, that means finding a variety of queries. Some ideas to improve the seed include
Conditional Continuous Fuzzing: As of now, the Fuzzing CI step is unconditional and runs on every PR. This is wasteful. Instead, we could make it conditional based on whether the PR touches the gql package.
Automation: Automate downloading the corpus and re-seeding it.
go-fuzz: https://github.com/dvyukov/go-fuzz
fuzzit: https://fuzzit.dev/
Libfuzzer: https://llvm.org/docs/LibFuzzer.html
Top image: Shining a Light on Dark Matter
