
We’re seeing more and more users who want to load massive data sets into Dgraph. Many users want to load billions of edges, and some even want to load up to 50 billion edges! When we heard about the size of these datasets, we knew we needed to have a solid data loading story so that we could support the most extreme demands from our users.
In a previous blog post, we discussed some of the challenges that we met on our journey towards loading massive datasets into Dgraph. In this post, we will discuss an alternate approach that has yielded significantly faster loading times.
TL;DR: We created a new tool called Bulkloader to populate Dgraph with an initial dataset. It’s highly performant and is able to load the entire Stack Overflow dataset in just over 1 hour on a single 64 core machine. The Stack Overflow dataset is massive and consists of ~2 billion RDFs. An additional ~1 billion edges are created for indexing and other internal usages. This gives ~3 billion edges in total. This equates to a loading rate of ~820k edges per second! Note that we had a significant skew in the predicate distribution which slowed the load down (all the text for questions, answers and comments was on the same predicate). Better results can likely be achieved on datasets with a more even predicate distribution.
All of our previous approaches have involved writing batch mutations to a running Dgraph instance. This is a convenient approach; we just have to iterate over the RDFs we want to load, batch them up, then send them to Dgraph.
We were able to achieve over 50k edges per second, which is really good throughput for a live system. But doing so seemed insufficient when you’re starting out with billions of edges and just want to bulk load them up into a new Dgraph instance.
Our previous approaches at speeding up the loading process had a focus on performance improvements to Dgraph’s mutation handling capabilities. We made great strides here, facing some tough challenges related to memory management along the way. Ultimately we hit some speed roadblocks though. We had to propose the mutations via Raft, which would write to a WAL for durability (to deal with crashes) and achieve consensus for consistency. We also needed to read the key to merge the new mutations coming in. Some of these keys (particularly index keys) were in such high demand that they’d become stragglers for the entire bulk load operation.
A key observation about loading massive datasets is that Dgraph does not have to be live while the loading happens. This is because loading large amounts of data is usually a step taken by users when migrating from another database technology stack (whether a graph database or otherwise).
Because Dgraph doesn’t have to be up and running while data is being loaded, this opens up lots of avenues for alternate (faster!) approaches.
This is where Bulkloader comes in. It’s a new program that performs the initial population of a Dgraph instance. It runs very quickly and scales well on high-end hardware.
Bulkloader utilises the map/shuffle/reduce paradigm. The diagram below shows the data flow through the system, from RDFs in files all the way to posting lists stored in Badger (Dgraph’s key-value store).
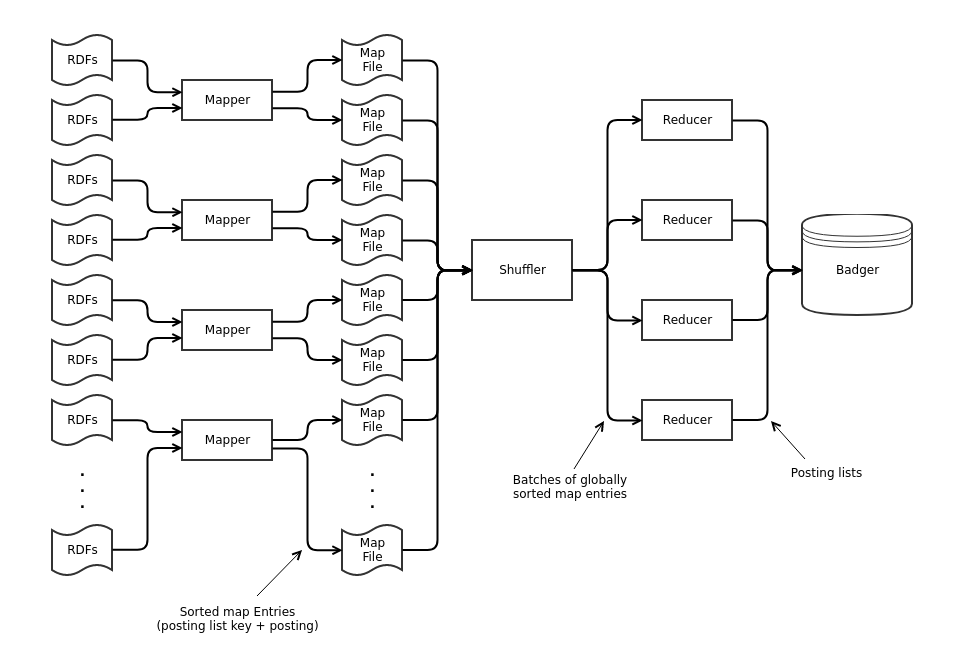
There’s a lot going on here, so let’s break it down:
The map phase takes RDFs as its input. It creates the edges that will eventually become part of the final Dgraph instance. Each RDF can correspond to one or more edges. The additional edges are for indexing and reverse edge traversal. Each edge is output along with the key of the posting list it will eventually become part of (this combination of edge and posting list key is referred to as a map entry). Map entries are bundled up into reasonably sized batches (e.g. 100MB), sorted, then written out to disk in map files. Sorting is only local for each map file since edges can be split between the map files in arbitrary ways. The sorting is important, and critical to the speed of the shuffler.
The shuffle phase combines all map files into a single globally sorted stream of map entries. Because each map file is sorted internally, a min heap data structure can be used to quickly assemble the stream. The stream is then broken up into batches that are passed on to the reduce phase.
The reduce phase takes batches of sorted map entries from the shuffle phase. It collects up groups of map entries with the same posting list key and then builds the corresponding posting list. To do this, the reducer iterates through the batch and generates a posting list whenever the posting list key changes. The posting lists are then written directly to Badger, Dgraph’s key-value store.
There are some additional complexities in the architecture that aren’t shown in the diagram. These are all related to bottlenecks in the processing where all data must flow through a single point or exclusive access to a single resource is needed. The bottlenecks don’t show themselves when running on regular quad-core machines but are must be removed in order to achieve full hardware utilization on high-end machines (e.g. machines with 64 cores).
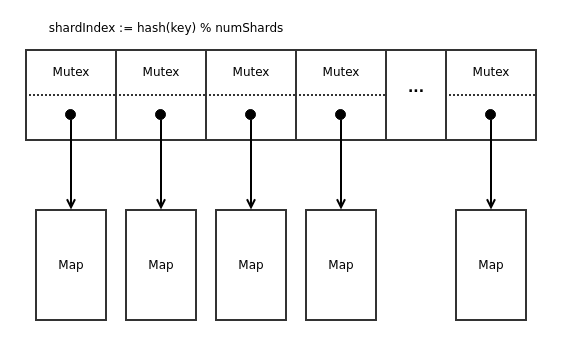
The first bottleneck is in the map phase. As part of this phase, blank nodes must be mapped to 64-bit UIDs. The first time a particular blank node (a string) is seen, a new UID must be assigned. When that blank node is seen again in a subsequent RDF, the same UID must be used. Since the input RDF files can be split up in any arbitrary way, the same blank node could be processed by two different mappers that are running concurrently. Because of this, the management of UID assignment must be shared between all mappers.
The original design was to use a map (from string to uint64) protected by a
mutex. With many concurrent mappers (e.g. 64), profiling showed large amounts
of contention on the lock.
We solved this problem by using a sharded map. The idea is to break the map
into two levels. The first level is a fixed size array e.g. of length 256. A
hash of the key determines which entry in the array to use. Each array element
is a mutex and a regular hash map, which stores the final string to uint64
mapping (i.e. a single shard of the sharded map). Assuming the hash function
gives a reasonable key distribution, access is spread out evenly among the
different map shards, and contention is no longer a problem.
Another bottleneck in the program is the shuffling. The architecture diagram above just shows a single shuffler for simplicity. This was the original design and showed up as a bottleneck when running on a machine with 64 cores. All data has to flow through a single code path in a single thread in order to get a globally sorted stream of map entries.
The reason we wanted a globally sorted stream was so that the reducer could quickly scan the stream and assemble posting lists from entries with the same posting list key.
The solution was to split up the entire Bulkloader into shards, separated by predicates. Since edges with different predicates can never appear in the same posting list, this is safe to do. There are a separate set of map entry files for each shard that can be picked up by multiple shufflers, 1 per shard. If there are more predicates than the requested number of shards, then multiple predicates are placed in each shard. Automatic predicate balancing results in shards that are as evenly sized as possible.
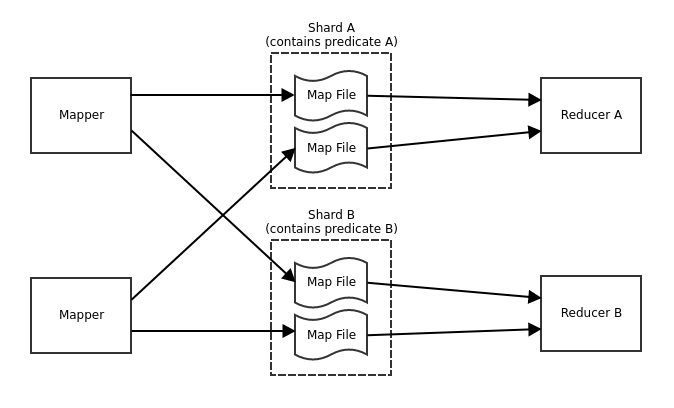
For big datasets, users typically want to split up the data among multiple servers. So splitting the output from multiple shufflers into multiple Badgers allows us to produce multiple shards of Dgraph; which a user can use to run a Dgraph cluster.
This also significantly improves the reduce phase, because multiple Badgers are concurrently being written to. So many badgers!

We used Bulkloader to load the entire Stack Overflow dataset in just over 1 hour.
Machine details:
Bulkloader performance:
Bulkloader is super fast, and we recommend it as the way to do the initial data loading for new Dgraph instances.
It is available from Dgraph v0.8.3 onwards.
There are lots of different knobs and dials that can be tweaked to get maximum
performance out of different hardware setups (look at the output when using the
--help flag). You can have a look at the code for the bulkloader here. Give it
a go and be amazed!