
As Dgraph is nearing its v0.8 release, we wanted to spend some time comparing it against Neo4j, which is the most popular graph database.
We have divided this post into five parts:
We wanted to load a dense graph data set involving real world data. We at Dgraph have been using the Freebase film data for our development and testing. We feel this data is highly interconnected and makes a good use case for storing in a graph database.
The first problem we faced was that Neo4j doesn’t accept data in RDF format directly 3.1 . The loader for Neo4j accepts data in CSV format which is essentially what SQL tables have. In our 21 million dataset, we have 50 distinct types of entities and 132 types of relationships between these entities. If we were to try and convert it to CSV format, we would end up with 100s of CSV files. One file for each type of entity, and one file per relationship between two types of entities. While this is okay for relational data, this doesn’t work for graph data sets, where each entity can be of multiple types, and relationships between entities are fluid.
So, we looked into the next best option to load graph data into Neo4j. We wrote a small program similar to the Dgraphloader which reads N-Quads, batches them and tries to load them concurrently into Neo4j. This program used Bolt, a new protocol by Neo4j. It is the fastest way we could find to load RDF data into Neo4j. In the video below, you can see a comparison of loading 1.1 million N-Quads on Dgraph vs. Neo4j.
Note that we only used 20 concurrent connections and batched 200 N-Quads for each request because Neo4j doesn’t work well if we increase either the number of connections or N-Quads per connection beyond this. In fact, that’s a sure way to make Neo4j data corrupt and hang the system 3.2 . For Dgraph, we typically send 1000 N-Quads per request and have 500 concurrent connections.
With the golden data set of 1.1 million N-Quads, Dgraph outperformed Neo4j 46.7k to 280 N-Quads per second. In fact, the Neo4j loader process never finished (we killed it after a considerable wait).
Dgraph is 160x faster than Neo4j for loading graph data.
We would have ideally liked to load up the entire 21 million RDF dataset so that we could compare the performance of both databases at scale. But given the difficulties we faced loading large amounts of data into Neo4j, we resorted to a subset dataset of 1.3 million N-Quads containing only certain types of entities and relationships. After a painful process, we converted our data into five CSV files, one for each type of entity (film, director, and genre) and two for the relationships between them; so that we could do some queries. We loaded these files into Neo4j using their import tool.
./neo4j start
./neo4j-admin import --database film.db --id-type string --nodes:Film $DATA/films.csv --nodes:Genre $DATA/genres.csv --nodes:Director $DATA/directors.csv --relationships:GENRE $DATA/filmgenre.csv --relationships:FILMS $DATA/directorfilm.csv
Then we created some indexes in Neo4j for the best query performance.
CREATE INDEX ON :Director(directorId)
CREATE INDEX ON :Director(name)
CREATE INDEX ON :Film(release_date)
We tested Neo4j twice. Once with query caching turned off, and then with query caching turned on. Generally, it does not make sense to benchmark queries with caching turned on, but we decided to set it because that’s the default behavior Neo4j users see. You can set it by modifying the following variable in conf/neo4j.conf.
dbms.query_cache_size=0
Dgraph does not do any query caching. We loaded an equivalent data set into Dgraph using the following schema and the commands below.
scalar (
type.object.name.en: string @index
film.film.initial_release_date: date @index
)
The schema file specifies creation of an index on the two predicates.
# Start Dgraph with a schema which specifies the predicates to index.
dgraph --schema ~/work/src/github.com/dgraph-io/benchmarks/data/goldendata.schema
# Load the data
dgraphloader -r ~/work/src/github.com/dgraph-io/benchmarks/data/neo4j/neo.rdf.gz
With data loaded up into both the databases, we benchmarked both simple and complex queries. The results didn’t surprise us.
The benchmarks for Neo4j and Dgraph were run separately so that both processes could utilize full CPU and RAM resources. Each sub-benchmark was run for 10s so that sufficient iterations could be run. We also monitored the memory usage for both the processes using a simple shell script.
go test -v -bench=Dgraph -benchtime=10s .
go test -v -bench=Neo -benchtime=10s .
| Id | Description |
|---|---|
| SQ | Get all films and genres of films directed by Steven Spielberg. |
| SQM | Runs the query above and changes the name of one of the films. |
| GS1Q | Search for directors with name Steven Spielberg and get their films sorted by release date. |
| GS1QM | Runs the query above and also changes the name of one of the films. |
| GS2Q | Search for directors with name Steven Spielberg and only their films released after 1984-08 sorted by release date. |
| GS2QM | Runs the query above and also changes the name of one of the films. |
| GS3Q | Search for directors with name Steven Spielberg and only their movies released between 1984-08 and 2000 sorted by release date. |
| GS3QM | Runs the query above and also changes the name of one of the films. |
Note: If the test id has a P suffix, it was run in parallel.
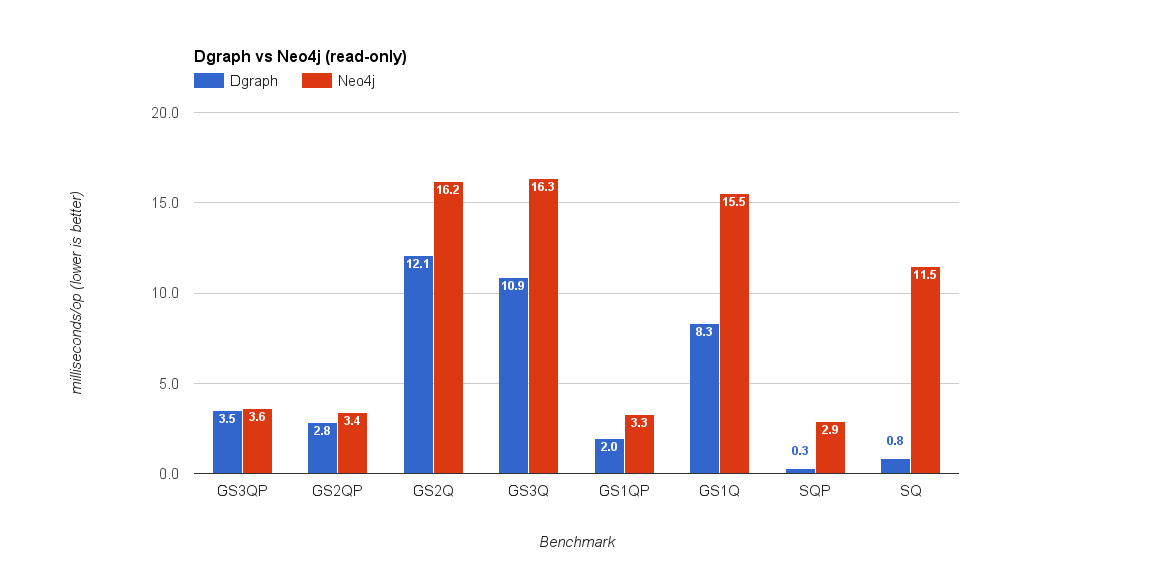
Query caching turned off for Neo4j
Query caching on for Neo4j
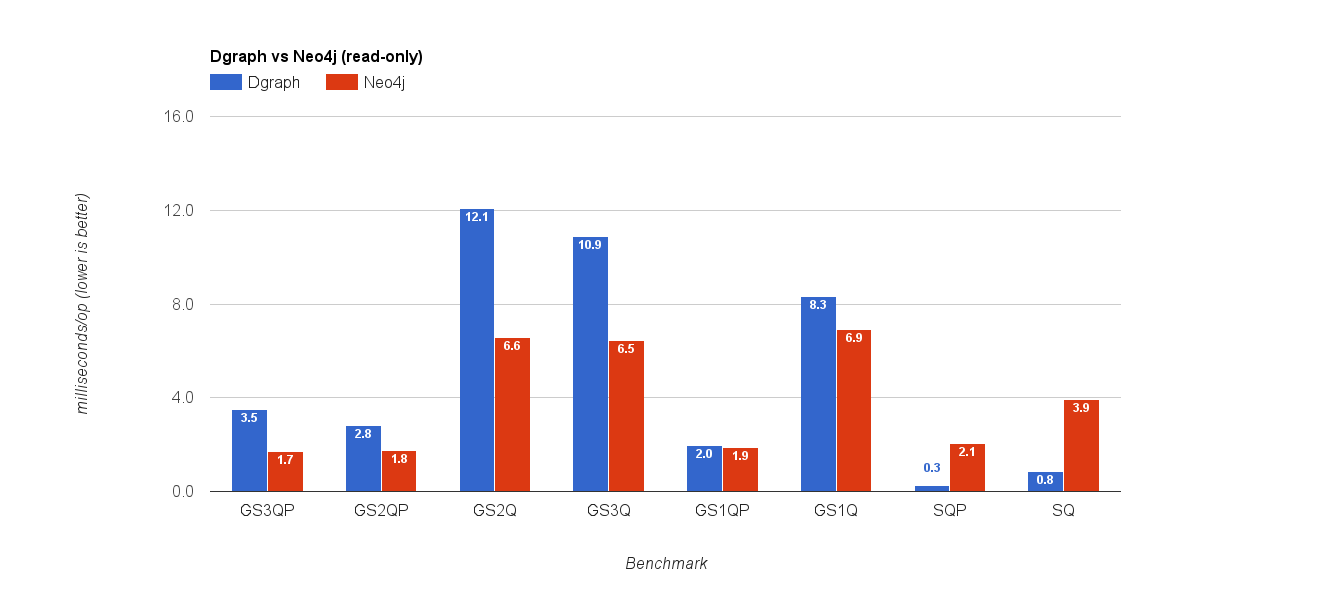
Queries to Dgraph took the same amount of time, as expected in the both cases. But, Neo4j query latency was at least halved. That’s not surprising given all the subsequent runs were using query cache. Thence, Neo4j latency was better than Dgraph with query caching turned on, and worse when off.
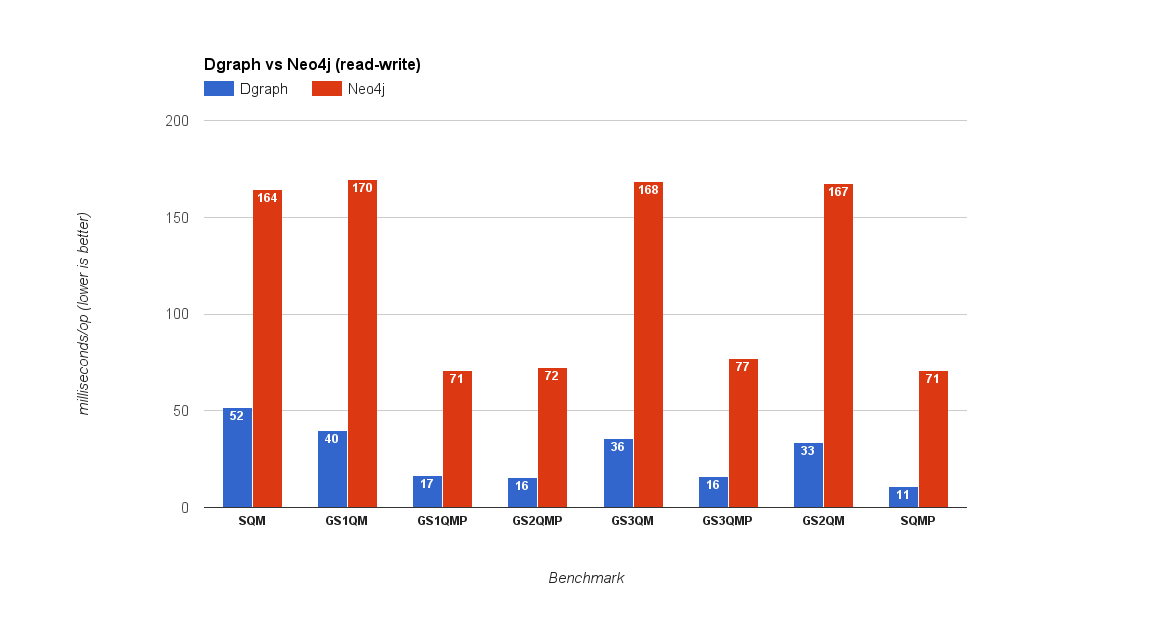
Query caching turned off for Neo4j
Query caching on for Neo4j
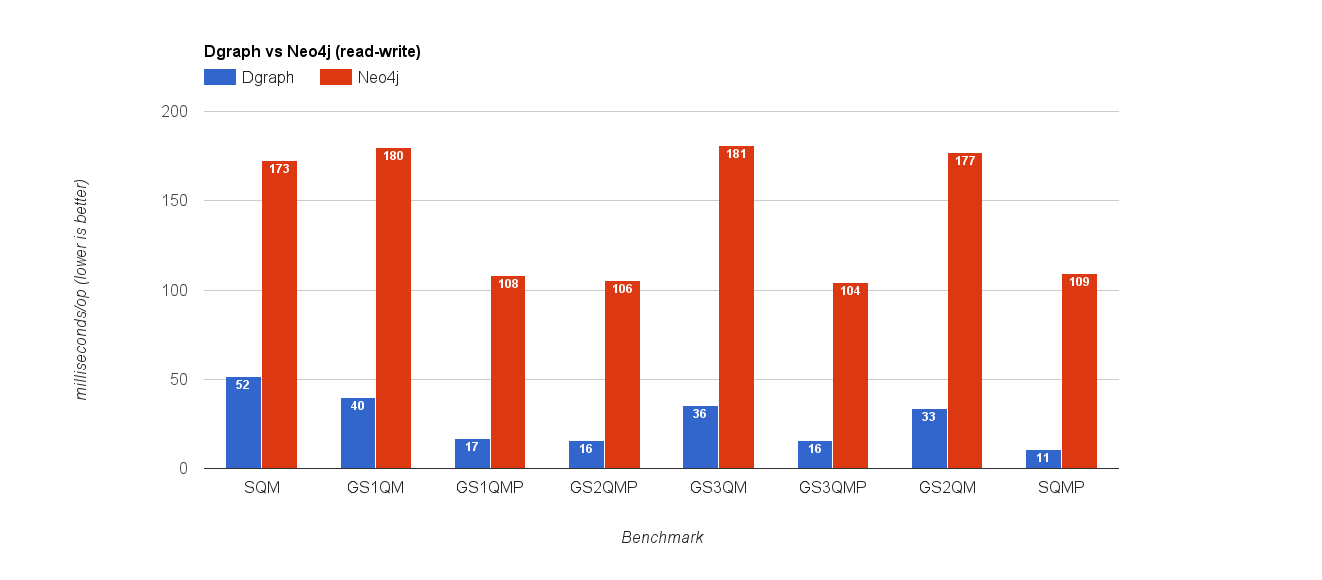
For intertwined reads and writes, Dgraph is at least 3x to 6x faster.
We can see that Neo4j is even slower with query caching on because they have to do the extra work of cache invalidation on writes. Dgraph was designed to achieve low latency querying with real world use cases, where reads are typically followed by writes and vice-versa, and the performance benefits show in the numbers.
Not just that, Neo4j takes up much more memory. At the start of the benchmarks Dgraph consumed around 20 MB which increased to 600 MB at the end. In comparison, Neo4j was already consuming 550 MB at the start which increased to 3.2 GB at the end of the benchmarks.
Dgraph consumes 5x lesser memory compared to Neo4j and is at least 3x faster for intertwined reads and writes.
We talked about performance and issues. Now, let’s see how does Dgraph compare against Neo4j regarding features.
| Feature | Dgraph | Neo4j |
|---|---|---|
| Production Features | Highly available, Consistent, Fault tolerant | Master-slave architecture (only full data replicas) |
| Data Sharding | Yes. Data sharded and replicated across servers, using consensus for writes. | No data sharding. |
| Horizontal Scalability | Yes. Add servers to cluster on the fly to distribute data better. | Supports only full data replicas |
| Transactional Model | Linearizability aka Atomic Consistency | ACID transactions |
| Backups | Hot backups in RDF format available using the HTTP interface | Hot full and incremental backups available only as part of paid enterprise edition |
| HTTP API for queries and mutations | Yes | Yes |
| Communication using clients over binary protocol | Yes, using grpc | Yes, using bolt protocol |
| Bulk loading of graph data | Yes, can load arbitrarily connected RDF data using dgraphloader | Only supports loading relational data in CSV format using the loader |
| Schema | Optional (supports int, float, string, bool, date, datetime and geo types) | Optional (supports byte, short, int, long, float, double, char and string types) |
| Geospatial Queries | Yes. Supports near, within, contains, intersects | No. Not part of core database |
| Query language | GraphQL like which responds in JSON | Cypher |
| Order by, limit, skip and filter queries | Yes | Yes |
| Authorization and authentication | SSL/TLS and auth token based security (support by v1.0) | Supports basic user authentication and authorization |
| Aggregation queries | Work in progress (support by v1.0) | Supports count(), sum(), avg(), distinct and other aggregation queries |
| Access Control Lists | Work in progress (support by v1.0) | Available based on roles as part of enterprise edition |
| Support for plugins and user defined functions | Work in progress (support by v1.0) | Yes |
| Browser interface for visualization | Work in progress (support by v1.0) | Yes |
Dgraph (2016) is a lot younger project than Neo4j (2007), so reaching feature parity quickly was a tough job.
Dgraph supports most of the functionality that one needs to get the job done; though it doesn’t have all the functionality one might want.
While Dgraph runs very well on our (Linux) Thinkpads, it is designed to be a graph database for production. As such, it allows the ability to shard and distribute data over many servers. Consistency and fault tolerance are baked deep into Dgraph , to the point where even our tests need to start a single-node Raft cluster. All the writes, irrespective of which replica they end up on, can be read back instantaneously, i.e. linearizable (work in progress, ETA v0.8). A few server crashes would not lose data or affect the end-user queries, making the system highly-available.
Such features have traditionally been a talk for NoSQL databases or Spanner, not for graph databases. But, we think any production system, on which the entire application stack is based, must stay up, perform and scale well. The system must be able to utilize the server running it well, process a lot of queries per second, and provide a consistent latency.
Also, given we’re building a graph database, the system should be able to handle arbitrarily dense interconnected data and complex queries. It should not be confined by pre-optimization of certain edges, or other tricks to make certain queries run fast.
The speed achieved should be due to a better design and across the entire spectrum.
Finally, running and maintaining such a system should be easy to the engineers. And that’s only possible if the system is as simple as it can be, and every piece of complexity introduced to the system is carefully weighted.
These are the principles which guide us towards building Dgraph. And we’re glad that in a short period, we’ve been able to achieve many of these. Now we leave it to you, our users to try out Dgraph, and let us know what you think.
Manish will be giving a talk about Dgraph at Gophercon India on 24-25th Feb. If you’re attending the conference, find him to talk about all things Dgraph.
Note: We are happy to accept feedback about any improvements to the loader or the benchmark tests to get better results for Neo4j.
If you haven’t already tried Dgraph , try out the 5 step tutorial to get started with Dgraph. Let us know what you think!

