
Encryption at Rest in Dgraph and Badger
We built “Encryption at Rest” in Badger v2. Encryption is complex, but important. With this b ...
Learn more

If you have been following us, you may know that we released Badger a few months ago. Badger is a simple, efficient, and persistent key-value store, written in a hipster language. Even though it is not at v1.0 yet, we have already received a great response from the community. As of writing, Badger has 2350 stars on Github, and there have been lots of discussions online since the release announcement.
Our launch post contained benchmarks evaluating Badger against RocksDB. RocksDB was the store we were using before we decided to replace it and write our own, so it made sense to benchmark against it. However, a lot of people have been curious about how Badger fares against stores like LMDB and BoltDB.
In the launch post, we had mentioned that recent improvements to SSDs might make B+-trees a viable option for high write throughput. Also, the reason B+ trees are considered good for reads is that they have low read amplification. Badger’s design also provides for a significantly lower read amplification compared to other LSM tree based key-value stores. So, we decided it was worth benchmarking Badger against these stores.
It will be helpful if you have read our earlier post from when we launched Badger, but it is not required.
Based on our benchmarks, Badger is at least 1.7✕-22.3✕ faster than LMDB and BoltDB when doing random writes. Sorted range iteration is a bit slower when value size is small, but as value sizes increase, Badger is 4✕-111✕ times faster. On the flip side, Badger is currently up to 1.9✕ slower when doing random reads.
Thus, Badger’s unique design significantly outperforms these stores on write throughput and iteration latency, while being only slightly slower when it comes to random reads.
BoltDB started out as a port of LMDB to Go but has somewhat diverged since then. While LMDB heavily focuses on raw performance, Bolt has focused on simplicity and ease of use. However, they both share the same design, so describing LMDB should be sufficient.
LMDB provides a key-value stored using B+ trees. It has ACID semantics and support for transactions. It does not do any background work and has a crash resilient design that uses MVCC instead of locking. This means readers operate on an isolated snapshot of the database and don’t block. The codebase is quite small and portable, so LMDB runs across multiple platforms including Android, BSD, and Solaris. This talk by Howard Chu at Databaseology 2015 goes into much more details about LMDB’s design.
It is generally understood that B+ tree based stores are ideal for workloads which are read intensive.
Badger belongs to a family of key-value stores that are characterized by a design that uses a log-structured merge-tree (LSM tree). Popular stores in this category include LevelDB and RocksDB.
LSM tree based stores provide high write performance by sequentially writing key-value pairs in memory in the foreground, and then arranging them in multi-tiered levels on disk in the background. This approach is not without tradeoffs though. Values are written multiple times when arranging them in the tree (known as write amplification) and a single read might need to read multiple levels in the LSM tree before finding a value (known as read amplification).
Badger’s design is based on a paper titled ‘WiscKey: Separating Keys from Values in SSD-conscious Storage’ (referred to as the WISCKEY paper from now on). Here is an excerpt from the paper touching on the key design aspects:
“To realize an SSD-optimized key-value store, WiscKey includes four critical ideas. First, WiscKey separates keys from values, keeping only keys in the LSM-tree and the values in a separate log file. Second, to deal with unsorted values (which necessitate random access during range queries), WiscKey uses the parallel random-read characteristic of SSD devices. Third, WiscKey utilizes unique crash-consistency and garbage collection techniques to efficiently manage the value log. Finally, WiscKey optimizes performance by removing the LSM-tree log without sacrificing consistency, thus reducing system-call overhead from small writes.”
Badger’s design reduces both the read and write amplification seen in other LSM tree based stores. Keys tend to be much smaller in size than values, so by separating keys from values and prefix-diffing the keys, Badger significantly reduces the size of LSM tree. Badger does not acquire any global mutex locks, allowing reads to happen concurrently while writes are going on, to achieve a high read-write throughput. It is very crash resilient, as we tested and explained in this blog post.
While there are differences in implementation, design details are available in the paper. It also contains a good overview of LSM trees and databases using them.
The benchmarking setup was identical to the one we used when benchmarking Badger against RocksDB. Therefore the numbers should be comparable as well. We have made many optimizations, fixes, and improvements to Badger since, which should reflect in the numbers below.
To benchmark the stores, we measured 4 things:
We performed benchmarks on 3 different data sets, varying the number of keys and the value size (in bytes) associated with the keys.
| Value Size (bytes) | Num Keys (Each Key = 22 bytes) | |
|---|---|---|
| Data Set 1 | 128 | 250M |
| Data Set 2 | 1024 (1kb) | 75M |
| Data Set 3 | 16384 (16kb) | 5M |
All benchmarks were done on a dedicated AWS EC2 i3.large instance (us-east-2 region) running Ubuntu Server 16.04 LTS (HVM) with 16GB RAM. This instance comes with a locally mounted 470GB SSD drive. The benchmarks were performed on data stored on the local SSD, which provides 100K IOPS with 4KB block sizes. Note that the root and home directories are mounted on EBS storage which has very low IOPS.
We deliberately chose an instance with RAM size (16GB) lesser than the data set sizes. This provides a good setup for benchmarking and is representative of our use-cases for Badger, where data sizes are several times the size of RAM available.
We used the lmdb-go bindings to LMDB, which comes with its own embedded copy of the lmdb C source code. It is the most up to date binding available in Go and is well documented.
Thanks to Howard Chu for looking at the benchmarking code for lmdb-go. He
helped us tune the code, and also pointed
out that we should be using lmdb.NoReadahead flag
in our benchmarks when data size is larger than RAM.
We ran into a couple of issues with LMDB APIs:
Several hours into populating data into LMDB for one of our benchmarks, we suddenly saw a crash. After investigation, we realized that LMDB needs a configuration value for the maximum map size of the database. This needs to be determined upfront while opening the database. LMDB will not expand automatically as data size increases. To get around it, we set it to a calculated large number and re-populated the data.
During our initial benchmarking runs, the hit ratio (found vs. miss) and hence
read performance of LMDB was significantly affected by the value of
GOMAXPROCS. We could not figure out why this was happening. This issue got
compounded by an oversight in our code which was correctly handling error
inside the view transaction, but not outside it. A few days into this issue,
we fixed the error handling and realized that a large number of reads were
failing, because the maximum number of concurrent readers had to be set
explicitly, using the SetMaxReaders API function. From a
Go perspective, this is strange. This would require tracking how many
concurrent reads are going on at a given moment, and restrict them to a
pre-specified number. In a highly concurrent Go based system like Dgraph, this
would be a severe limitation. We got around the limitation by setting the
maximum number of readers to a number based on the benchmarks.
While none of these limitations are deal breakers, they do present unfamiliar obstacles for a Go programmer using LMDB. In comparison, BoltDB and Badger do not require you to specify a maximum map size, or a maximum number of readers in advance.
We used the BoltDB source hosted on Github. Note that there is a fork of BoltDB, called bbolt maintained by CoreOS. However, we decided to stick to the original version which is considered complete by its maintainer. We did not run into any issues when using BoltDB APIs. They are clean and well documented.
We ran the benchmarks against code in Badger repo on Github, at commit 64df7f5. This included a significant change in the way we read the value log, where we switched from using standard file I/O to memory-mapping the files before reading. We will cover this in more detail in the sections below.
All the benchmarking code and results are available on Github in the badger-bench repo. To make the benchmarks transparent and repeatable, we have recorded all the steps in detail in our benchmarking log.
Numbers and charts can also be found in this spreadsheet.
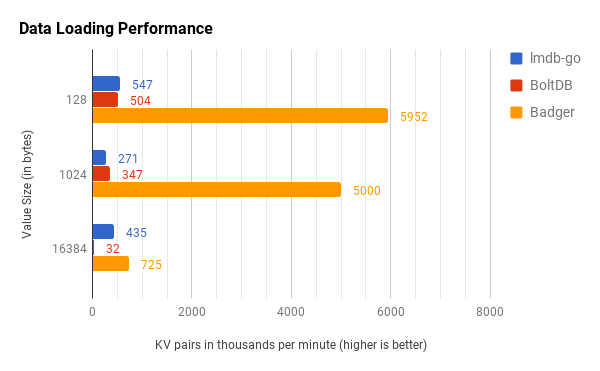
The results of this benchmark are pretty unequivocal. Badger is significantly faster than both LMDB and BoltDB in loading data. The factor of speedup ranges from 1.7✕ to 22.3✕. Bolt DB degrades pretty badly in the 16kb data set with a throughput of only 32000 key-value pairs a minute.
B+ trees do not have very good write performance, and these benchmarks support that claim. Writing KV pairs randomly to Bolt or LMDB leads to a lot of random seeks on the disk. Badger, on the other hand, writes to an LSM tree where all writes are sequential. Moreover, the actual values are written in a log elsewhere using sequential writes. This leads to much better disk utilization and throughput.
Some additional technical notes:
Badger provides an API method called BatchSet which
batches up a series of writes to the value log. This can significantly speed
up bulk-loading. BoltDB and lmdb-go do not have an equivalent API.
BoltDB provides an API method called Batch(), which can be
used to achieve some concurrency while writing to it. The results
above are using this call, but we did not notice a very significant
difference for this specific benchmark.
lmdb-go has a limitation in its API when it comes to writing to the
store using multiple goroutines. Here is what the API docs
say: Write transactions (those created without the
Readonly flag) must be created in a goroutine that has been locked to its
thread by calling the function runtime.LockOSThread. Furthermore all
methods on such transactions must be called from the goroutine which created
them. This is a fundamental limitation of LMDB even when using the NoTLS
flag (which the package always uses).

We did not notice any patterns w.r.t. final data set sizes among the stores. Bolt and LMDB store data in one large file and keys and values are stored together. Badger stores data in two different kinds of files: one for LSM data which contains keys and pointer to values, and value log files which contain the actual values.
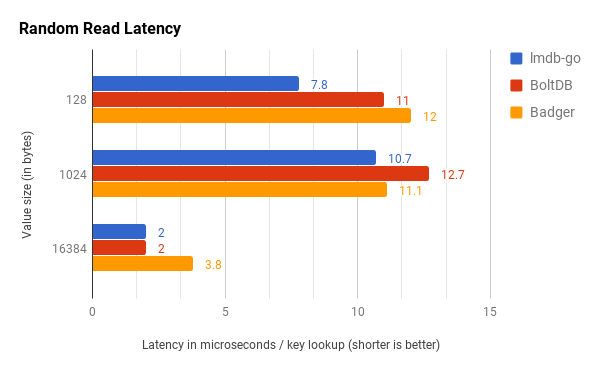
LMDB has the lowest read latencies across all the data sets. Badger goes neck-to-neck against LMDB in 1kB value, but in other values are up to 2x slow. BoltDB, on the other hand, has lower latencies than Badger for the 128B and 16kB datasets but shows higher latency in the 1kB data set.
We were pleasantly surprised by these results. Badger holds pretty well against both the stores, never performing particularly worse than others, and at least in one instance, beating BoltDB. This is a particularly important feat because random key lookup is the weakest spot for LSM based KV stores. LSM-tree suffers from read-amplification. It needs to look for the key in multiple places before returning.
Badger’s design handles read amplification in two ways. It first significantly reduces the size of LSM tree by separating keys from values, and secondly, minimizes the latency by keeping the (much smaller) LSM tree entirely in RAM. This makes Badger much faster than other LSM-tree based key-value stores like RocksDB and a lot more competitive with B+-trees.
Note that LMDB was slower in our initial benchmarks before Howard Chu pointed
out that we should be setting the
lmdb.NoReadahead flag when opening the store. This got us thinking, and we
realized that this could apply to Badger as well. We already had a feature
request to memory-map the value log files. We decided to give that a
shot, and also disabled readahead using the madvise system
call. When we ran the benchmarks for the 16kB dataset after this change, we
were able to reduce the latency from 22µs to 3.8µs.
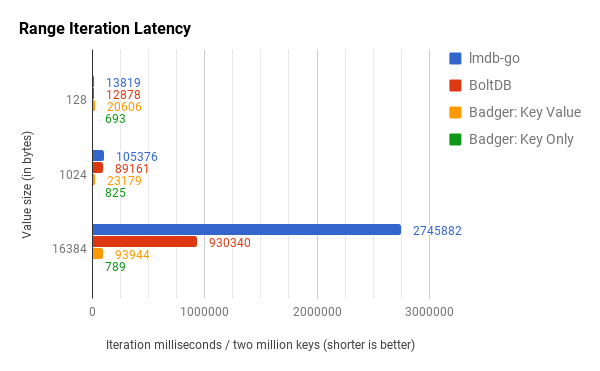
For the data store with 128B value size, Badger is about 1.5✕-1.6✕ slower than lmdb-go and BoltDB. However, Badger’s performance improves as value sizes get bigger. Badger is anywhere between 4✕-111✕ times faster when iterating over data stores with 1kb and 16kb value size. Badger’s design allows it to prefetch values in the background during iteration. This is controlled by an option and is enabled by default. The WISCKEY paper touches upon this:
“To make range queries efficient, WiscKey leverages the parallel I/O characteristic of SSD devices to prefetch values from the vLog during range queries. The underlying idea is that, with SSDs, only keys require special attention for efficient retrieval. So long as keys are retrieved efficiently, range queries can use parallel random reads for efficiently retrieving values.”
In our launch post, we mentioned that there were shortcomings with iteration in Badger because we were unable to realize the high SSD IOPS via Go. After much discussion and digging, we realized that setting GOMAXPROCS to a high enough number (say 128), allows us to realize the high IOPS, making Badger significantly faster for key-value iterations.
Badger’s iterator API also allows what we call key-only iteration. In this mode, we iterate only over the LSM tree and do not read the values in the value log files at all. This means that most of the time, iterations do not touch the disk and happen blazingly fast. This functionality is unique to Badger among all the other key-value stores compared.
Key-only iterations are very useful in various applications which only need to iterate over keys, for splitting tablets or estimating data sizes based on key prefixes. At Dgraph, we use them to estimate the size of tablets, run filters and only retrieve values for a much smaller subset of keys.
LMDB implementation in Go outperformed both BoltDB and Badger in terms of random read latency, but was significantly slower for sorted range iteration and had several mind-boggling API limitations. If you have a random read intensive workload, LMDB Go might be a suitable store for you.
BoltDB didn’t really stand apart in any of the four criteria. It was the slowest in data loading, fell well behind Badger in sorted range iteration (though outperformed LMDB), and gave conflicting results w.r.t. random key lookup. However, it did have a clean and well-documented APIs and supports ACID transactions.
One of the big reasons we wrote Badger was that we were having difficulty understanding the behavior of Cgo APIs accessing RocksDB from within Go. Using a store written in pure Go allows better visibility into what’s going on using Go’s profiling tools. It also allows more convenient control over concurrent operations using Go’s native support for goroutines. So BoltDB and Badger might be better choices over LMDB in this scenario.
Badger significantly outperformed its competition in both write throughput and sorted range iteration. It performed slightly worse in random key lookup but did not deteriorate in performance as badly as competition did in other categories. For a workload which has a mix of reads and writes in any proportion (even 90-10), Badger is a clear choice.
At this point, the biggest aim for Badger is to stabilize the API and bring it past v1.0. Various projects like IPFS use Badger, and there’s an outstanding Github issue to integrate Badger with Bleve.
Also, we are considering adding transactional support into Badger. So, if you think it would be useful to you, let us know.
In this post, we have done a comprehensive survey of how Badger compares against two popular options for key-value stores in Go. Badger is still quite new, and we are excited about what lies ahead for the project.
We put months of effort into ensuring the benchmarks were impartial, correctly set up and executed. Many a times this process was laborious and frustrating, but we were excited about the possibility of learning a few things from other key-value stores and improving Badger; which we did. These benchmarks make us even more convinced of the effort that Dgraph team has put into building Badger from scratch. We have built a solid offering not only to be used within Dgraph, but for anyone looking for a key-value store in Go.
We would love to hear from you regarding what you think we should be focusing on in the future. If you have any comments or questions, please head to discuss.dgraph.io.
