
Crashes can occur for many different reasons and can manifest themselves in many different forms. A program can experience a segfault or uncaught exception. If it’s running on Linux, a kernel panic could occur. If on Windows, a STOP error could occur, displaying the infamous BSOD. Even then, crashes aren’t the only thing you have to worry about. The UPS could fail (or be absent), or the power could go out. Someone could be walking through the data center and trip over a power cord. In short, any program can terminate prematurely and unexpectedly.
When a database crashes, what happens to your data? If your database has a high level of crash resilience, your data is safe. The database can be started up again, and you’re pretty much good to go. You might have to rerun the last few mutations you made before the crash, but for the most part, your data is still intact. But what about databases with low levels of crash resilience? I hope you make regular backups, because your database might not even start up.
At Dgraph Labs, current efforts are being spent ramping up towards a 1.0 version of our flagship product, Dgraph. Dgraph is already very stable, but we want to go the extra mile and make it robust and rock solid, even under rare and unlikely scenarios.
Dgraph relies on Badger (our key value store) to persist its data. This is an obvious place to look when it comes to making the whole system resilient against crashes. This blog post will explore the area of crash resilience. It will look at a tool called ALICE, and how we used it to improve the crash resilience of Badger.
Badger contains a write ahead value log, which is replayed when Badger starts up. You can read more about the internals of Badger here.
The design of Badger is based on a paper titled WiscKey: Separating Keys from Values in SSD-conscious Storage. This paper discusses a property of modern file systems that aids in creating crash resilient systems:
[There is] an interesting property of modern file systems (such as ext4, btrfs, and xfs). … Consider a file that contains [a] sequence of bytes … and the user appends … to it. If a crash happens, … only some prefix of the appended bytes will be added to the end of the file. … It is not possible for random bytes or a non-prefix subset of the appended bytes to be added to the file.
We wanted to use this interesting file system property to improve Badger. Specifically, to increase the crash resilience of the value log.
We decided to add an entry checksum to each value log entry. The idea was that this would enable us to detect short appends during log file replay so that we could truncate the value log at the end of the last good entry and continue with the normal start up procedure.
This task was one of the first things that I worked on when I started at Dgraph Labs a couple of weeks ago.
After adding checksums to Badger, I started looking at papers from the same authors as the WiscKey paper. I came a cross a paper titled All File Systems Are Not Created Equal: On the Complexity of Crafting Crash-Consistent Applications. This paper describes a tool called ALICE (Application-Level Intelligent Crash Explorer), written by the authors. ALICE discovers crash vulnerabilities in programs. A crash vulnerability is a bug in a program that manifests itself when the program starts up after a system crash. The main use of ALICE is to help programmers make their programs more robust and resilient to crashes. ALICE will be explained in greater detail later in this blog post.
ALICE helped identify two different crash vulnerabilities in Badger and even hinted towards how those vulnerabilities could be fixed. Despite having minimal experience with the Badger code base, I was able to identify and implement those fixes. This is a testament to the usefulness of ALICE as a tool (although the simplicity of the Badger codebase helped a lot here!).
I learned a lot about file systems and Linux system calls while working with ALICE. Some things I already intuitively knew, but other things were totally surprising.
Say you have a file named f on disk. It contains the sequence of bytes ABC.
You then have a C program that operates on the file. The intent of the file is
to change the content to 12345. The program isn’t crash resilient though;
under certain crash scenarios, the file could end up having content other
than ABC or 12345.
01 int fd = open("f", O_RDWR | O_TRUNC, 0644);
02 write(fd, "12345", 5);
03 close(fd);
# Boilerplate and error checking left out for brevity.
So if the program crashes part way through, what possible states could the file
f be in? For each of the following possible states, think about whether the
state is possible or not.
f contains ABC.f contains 12345.f is now empty.f is missing from disk.f contains 123.f contains ABC$9.Take a few seconds and think about the possible states before reading on.
Alright! Let’s go through the possibility of the states.
States 1 and 2 are not only possible, they’re intended. They’re the only allowable states if the program is to be 100% resilient to crashes. State 1 can occur if the program crashes before opening the file. State 2 can occur if the crash occurs after the close.
State 3 is possible. It can occur if the program crashes after the call to
open but before the write call is persisted to disk. Note that the
O_TRUNC flag truncates the file to zero length when the file is opened.
State 4 is not possible. The file f will always exist on disk in some form.
State 5 is possible. Writes are not atomic and can be batched up in arbitrary sized chunks (although the size is usually much larger than a few bytes).
State 6 is a strange case, but surprisingly, possible! How does that happen? It appears as though garbage data was appended to the file!
This disk state is possible because writes are sometimes executed as two parallel operations.
If a crash occurs at precisely the wrong time, the change to the file size may be persisted to disk without the additional data being written.
This even happens in modern file systems such as ext4 (although only in writeback mode). So if you’re the author of a program that writes to files and you care about crash resilience, this is something you should design your program around.
So how can we get around these problems? A common idiom is to create a temporary file, write the new content to it, then rename it to the old file. But…
01 int fd = open("tmp", O_RDWR | O_CREAT | O_TRUNC, 0644);
02 write(fd, "12345", 5);
03 close(fd);
04 rename("tmp", "f");
There are some crash states where the
file f contains content other than ABC or 12345. Below are the same set
crash states as before. Again, think about whether each crash
state is possible or not.
f contains ABC.f contains 12345.f is now empty.f is missing from disk.f contains 123.f contains ABC$9.Pause for a moment to consider the possible states before reading on.
Okay! Let’s go through the different possibilities.
States 1 and 2 are still possible. That’s good, it means we don’t have a regression.
State 3 is still possible. It can occur when rename on line 4 persists to
disk before the write on line 2 (and the crash occurs before the write
persists). The calls to write and rename are not guaranteed to persist in
order.
Notably, the close doesn’t force the file contents to be persisted to disk.
There is a common misconception among programmers that closing a file flushes
to disk, but this is not true. This is the behaviour for C as well as some
higher level languages such as Go and
Python.
From the man page:
A successful close does not guarantee that the data has been successfully saved to disk, as the kernel defers writes. It is not common for a file system to flush the buffers when the stream is closed. If you need to be sure that the data is physically stored use fsync(2). (It will depend on the disk hardware at this point.)
State 4 is not possible. This is because rename is atomic, so there will
never be a case where f is missing from disk.
State 5 is possible; after crashing the file may contain only 123. The first
part of the write on line 2 could persist, then the file could be renamed. If
the crash occurs before the final part of the write persists, then 123 would
be the result.
State 6 could also occur. This is similar to state 5. The rename may be persisted before the write. The write may only partially persist before the crash, leaving the file size updated without the data being written.
Notice that the set of bad crash states is the same as before… So in a certain sense, the program has become more complicated but can still break in the same ways. Not to fear though, with one small tweak we can fix everything!
We need one more system call to fix the program. Remember how close doesn’t
flush the file content to disk? The man page gave an important hint, fsync!
fsync flushes all pending writes through any buffers and persists them to
physical disk. It’s a blocking call, and doesn’t return until the data is
completely persisted. There are equivalents in higher level languages. In Go
it’s File.Sync, and in Python it’s
os.fsync.
So how does it help? Let’s alter the program again. It’s the same as before,
except that we use fsync after the write.
01 int fd = open("tmp", O_RDWR | O_CREAT | O_TRUNC, 0644);
02 write(fd, "12345", 5);
03 fsync(fd);
04 close(fd);
05 rename("tmp", "f");
Now we’re getting somewhere! The temp file is created and has 12345 written
to it. The sync causes the data to be persisted to disk. Only then is the file
renamed. The file f cannot end up empty since the write now has to
persist before the rename. For the same reason, the file can’t end up with
123 or ABC$9. No matter how the program crashes, f will always either
contain ABC or 12345. Neat!
In simple programs like the ones above, it’s possible to identify and fix crash resilience problems manually, so long as you understand all of the limitations and guarantees that file systems provide. For large programs like Badger, it’s much more difficult. Luckily, the process becomes easier with the aid of tooling.
ALICE is one such tool that can help find crash vulnerabilities. You still need to understand the limitations and guarantees of the file system to use the tool, but it does do most of the heavy lifting when it comes to the identification of problems.
So how does it work?
ALICE works by executing a workload (supplied by the user). This starts up the application-under-test and makes it perform various operations. ALICE records the system calls made by the program, including the details of all file system manipulations. Using the record of those system calls, it is able to create all of the possible crash states that could occur. To do this, it takes into consideration all of the legal reorderings of the file system manipulations made by the program-under-test. For each crash states, ALICE runs a checker (also supplied by the user). The checker tests to see if the crash state is permissible i.e. the program-under-test can start up, recover from the crash, and continue from where it left off.
So what does this look like for the ABC -> 12345 example?
The workload is just the program that changes the content of the file (we start with the incorrect attempt at the program):
int main()
{
int fd = open("f", O_RDWR | O_TRUNC, 0666); // assert(fd > 0);
int ret = write(fd, "12345", 5); // assert(ret == 5);
ret = close(fd); // assert(ret == 0);
}
What about the checker? It simply checks the consistency constraints that we expect the program to maintain. It can be written in any language, e.g. Python:
import os
import sys
crashed_state_directory = sys.argv[1]
os.chdir(crashed_state_directory)
assert open('f').read() in ['ABC', '12345']
When ALICE is run, its output indicates that there are some crash vulnerabilities:

The output indicates that there is a problem if the file is truncated, but not appended to.
When we run the second version of the program, we get a different report from ALICE.
int main() {
int fd = open("tmp", O_RDWR | O_CREAT | O_TRUNC, 0666); // assert(fd > 0);
int ret = write(fd, "12345", 5); // assert(ret == 5);
ret = close(fd); // assert(ret == 0);
ret = rename("tmp", "f"); // assert(ret == 0);
}
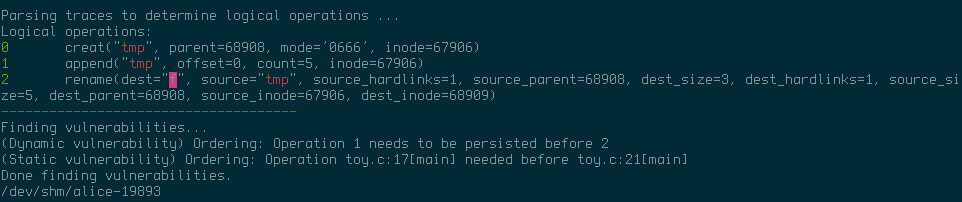
This time, ALICE indicates that the ordering of system calls is not guaranteed. Specifically, the rename may persist before the append.
Once the problem with the program is fixed (the fsync call added), ALICE
reports that there are no errors:
int main() {
int fd = open("tmp", O_RDWR | O_CREAT | O_TRUNC, 0666); // assert(fd > 0);
int ret = write(fd, "12345", 5); // assert(ret == 5);
ret = fsync(fd); // assert(ret == 0);
ret = close(fd); // assert(ret == 0);
ret = rename("tmp", "f"); // assert(ret == 0);
}

Excellent! The program is now free of crash vulnerabilities.
As part of their research, the authors of ALICE checked various key value stores and databases for crash vulnerabilities. We decided to put Badger through the same paces. There were two main motivations for this:
The workload and checker are a little bit more complicated for Badger. The workload inserts some key/value pairs, then updates them several times. The checker then ensures that Badger can start up after the simulated crash.
In order to test as many code paths in Badger as possible, we needed the workload to trigger both LSM tree compaction and a value log garbage collection. LSM tree compactions are necessary to allow the high write throughput possible with the design. Value log garbage collection rewrites value log files to reclaim disk space, discarding stale entries in the process.
In order to coax Badger into performing both of the above, Badger’s parameters are set up so that it will aggressively trigger them, even for small data writes.
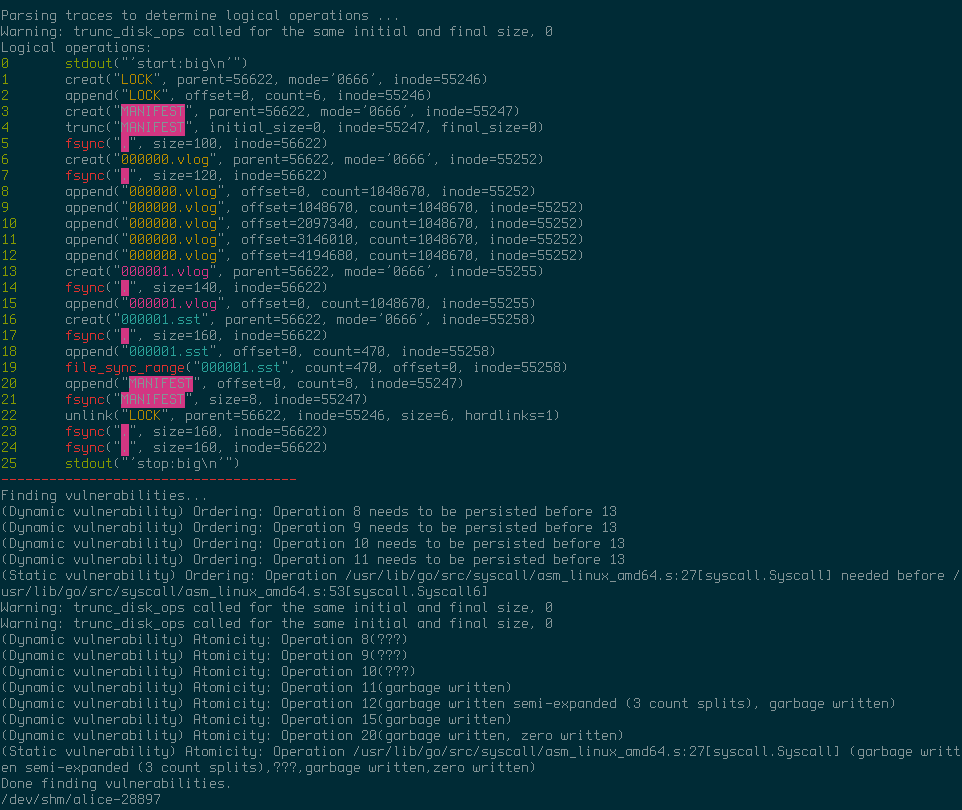
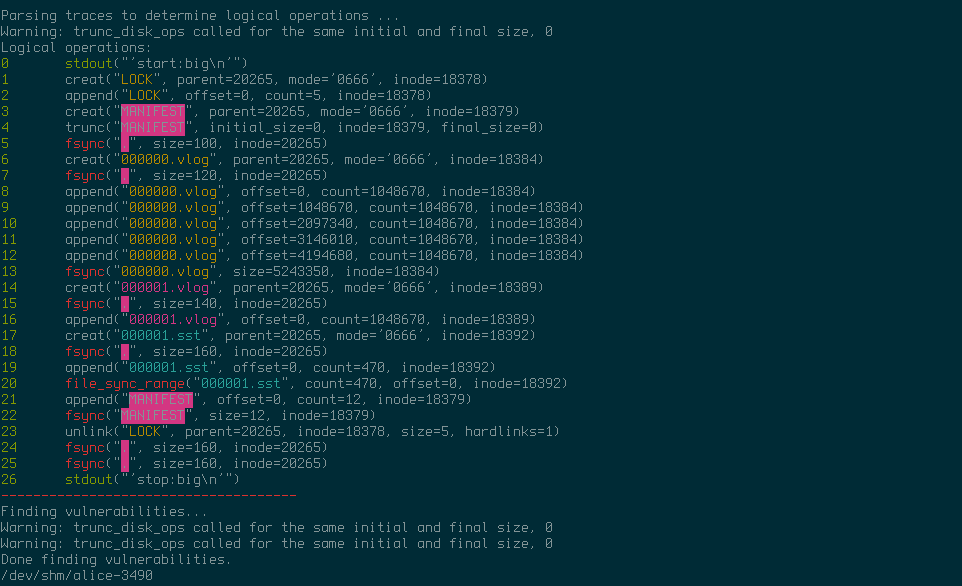
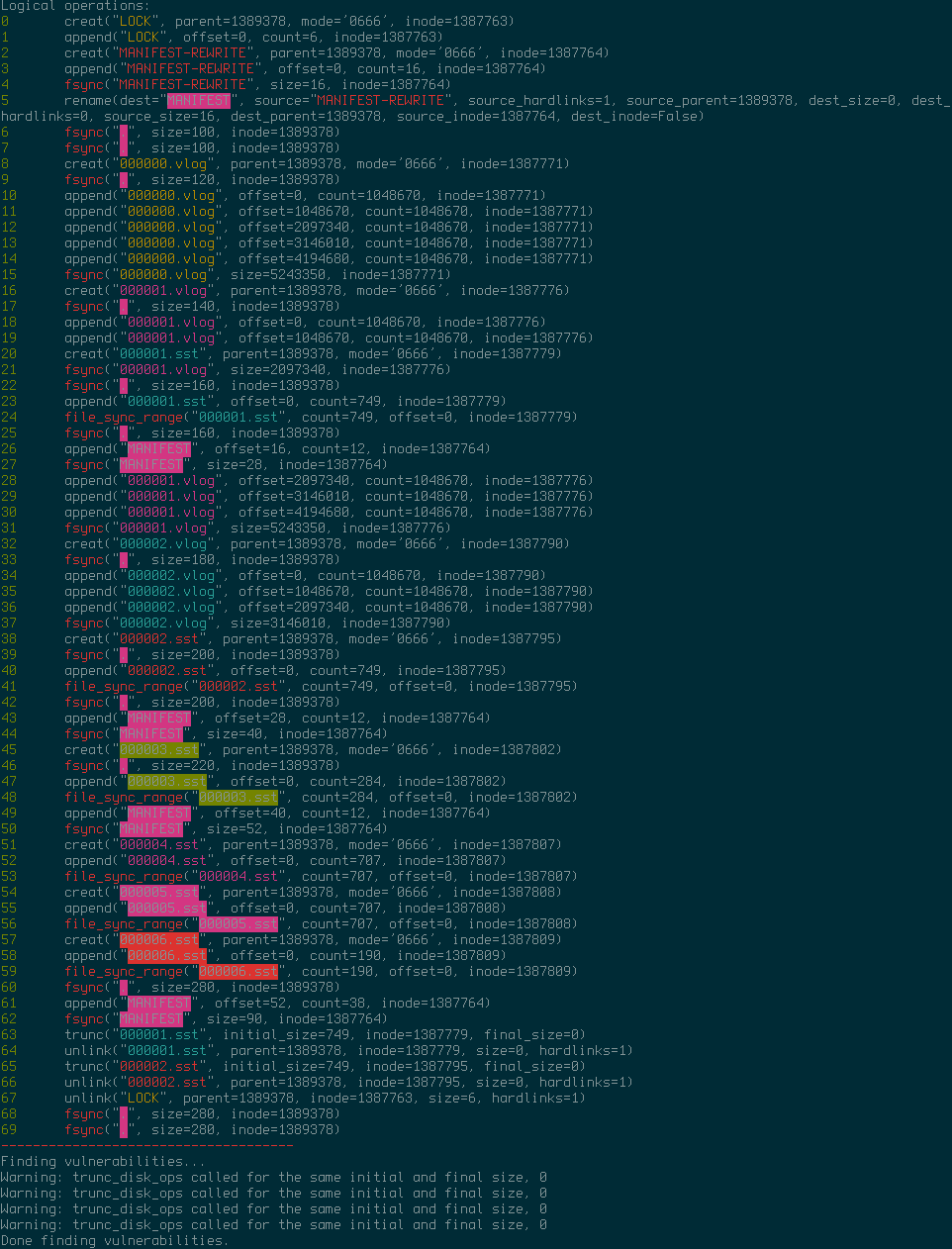
When ALICE was first run over Badger, the output indicated quite a few problems:
Triggering value log garbage collection:
Triggering LSM tree compaction:
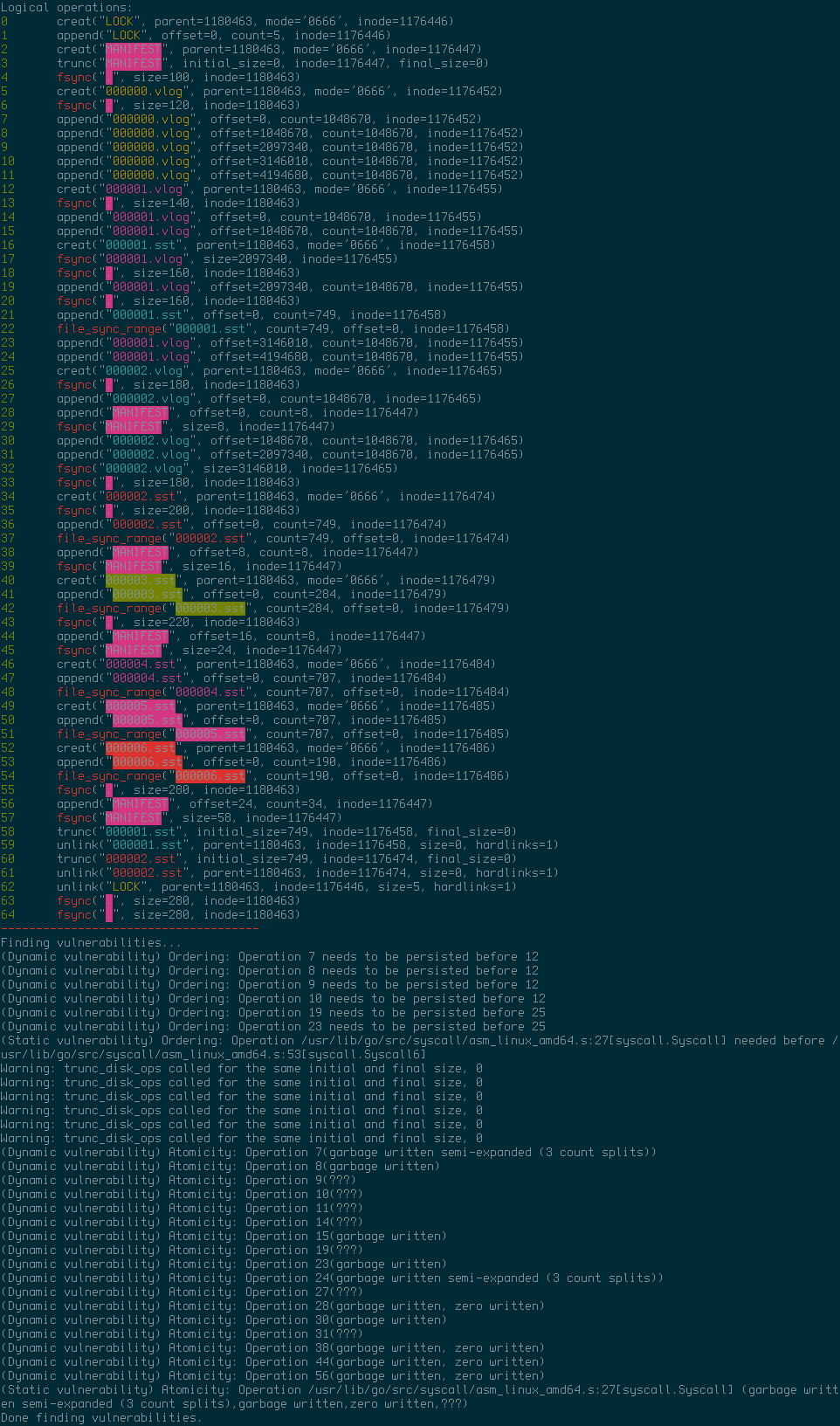
The long list of problems from the output only corresponds to two different vulnerabilities, which are discussed in detail in the next sections.
To put two crash vulnerabilities into perspective, we can compare to the number of vulnerabilities that were found by the ALICE authors in other programs, as documented in the paper.
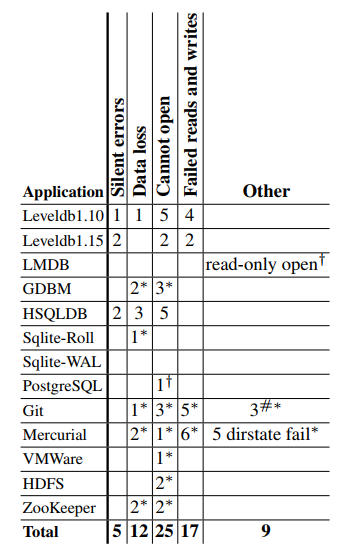
Badger does considerably better than some other database style applications, even those that are backed by large organisations, e.g.:
Another thing to note is that at Dgraph Labs, we’re actively seeking out resources to make our products the best that they can be. When you’re writing world class software, behaving reactively and waiting for the bug reports to roll in, just isn’t an option!
So what does the ALICE output mean, and how does it translate into actual crash vulnerabilities?
When Badger appends to a value log file,
it just does a normal appending write. As seen previously, a crash during or
shortly after an append can result in the file containing some garbage data.
In the ALICE output:


ALICE is able to generate crash states containing garbage by artificially injecting garbage bytes into the ends of the recorded writes.
This is a little bit confusing though. Recall that this was a known problem that was previously ‘solved’ by adding a checksum to the end of each value log entry. While replaying a value log, if an entry’s checksum doesn’t match up, we assume that the value log is corrupted and truncate it. So why are garbage writes causing crashes in Badger? They should just be discarded.
Unfortunately, ALICE doesn’t give any clues. It doesn’t show the output of the checker, it just indicates that it failed. I had to hack the ALICE source code to leave the crash states on disk, rather than cleaning them up at the end of its execution. I could then iterate over the crash states myself, manually checking how Badger reacts when it starts up.
Once I did this, it was obvious what the problem was. For some crash states, Badger terminated with an out of memory error. The stack traces indicated the problem was occurring in the value log replay code.
The vulnerability occurs when the key and value lengths in a value log entry header contain garbage data. These lengths are used to figure out how to read the key and value. A 4-byte integer’s largest value is ~4 billion, causing a worst case memory allocation of 8GB (4GB for each of the key and value). This can cause the process to go out of memory, resulting in Badger refusing to start.
Since we expect that keys will always be smaller than 1MB and values will always be smaller than 1GB (these are generous bounds), we can simply cap the allowable size of keys and values. If the header indicates that the key or value is bigger than its bound, we know the entry is corrupt (and avoid a memory allocation based on bad data). But what if the header is corrupt but the key and value lengths are within their bounds? In that case, we can still detect the corruption using the checksum.
Once a corrupt entry is detected, we can truncate the value log at that point.
The relevant pull request is here.
The value log is actually made up of many smaller value log files. When an individual value log file gets too big, a new one is created. The value log (conceptually the concatenation of all of the value log files) then continues in the new value log file. Meanwhile, Badger maintains a head pointer, corresponding to the offset in value log, uptil which everything has been persisted to disk on the LSM tree.
When Badger starts up, it picks the latest value of head from the persisted portion of the LSM tree, and replays the entries from value log from that offset onwards to bring them back into LSM tree (for more details about how this works, see the original paper).
The ALICE output indicates that there is a problem around the transition from
one value log file (*.vlog) to the next:


When Badger starts up, all of the
*vlog are first opened:
vlog file is opened in read/write mode. This is the vlog file
that will be appended to when the key value store is mutated.vlog files are opened in read-only mode. They are only used
for value lookups.The value log is then replayed from the head persisted in the LSM tree. When a
corrupt entry in a vlog file is found during replay, that file is truncated
so that it contains only good entries. This is normally fine, because the
corrupt file is expected to be the latest one (since it would have been
appended to last before the crash).
This isn’t always the case though…
The problem occurs when the content of 000001.vlog is persisted to disk
before the content of 000000.vlog. 000001.vlog will be the latest value log
file (opened as read/write), but 000000.vlog (opened as read-only) may have
corrupt entries. The result is that we try to truncate a file that is opened in
read-only mode.
This vulnerability only occurs when
Badger is configured with
SyncWrites=false. This is a mode that trades off increased write performance
for the chance that if Badger crashes,
some small amount of recently written data may be lost. However, the
vulnerability does leave Badger unable
to restart which is unacceptable.
There are a few different possible fixes here. We went for a simple fix: always
sync the current vlog file before starting a new
one. That way, the nth value log
file is always persisted completely before the n+1th is written.
After we fixed the problems that ALICE reported, running ALICE again shows no crash vulnerabilities for Badger. Awesome!
Triggering value log garbage collection:
Triggering LSM tree compaction:
Here at Dgraph Labs, we really care about making our products as robust as possible, even under unlikely and rare scenarios such as system crashes. We want to stay ahead of the curve when it comes to rock solid stability. Proactively finding and fixing bugs before they are reported in production is a major part of that.
If you own and maintain software that interacts directly with files, we recommend that you give ALICE a try. Also, if you need a rock solid and performant key-value store, you know where to look!
