{kind=link}

v24
Enhanced AI Capabilities with Vector Support & Optimized Caching Performance We are thrilled to announce ...
Learn more

In this article we explain our transition to GitHub Actions for our CI/CD needs at Dgraph Labs Inc. As a part of this effort we have built (in-house) & implemented a new architecture for “Dynamic AutoScaling of GitHub Runners” to power this setup.
In the past, our CI/CD was powered by a self-hosted on-prem
TeamCity setup - this turned out to be a little difficult to operate & manage in
a startup setting like ours. Transitioning to GitHub Actions & implementing our
new in-house built “Dynamic AutoScaling of GitHub Runners” - has helped us reduce our Compute Costs,
Maintenance Efforts & Configuration Time across our repositories for our
CI/CD efforts (with improved security).
Before we begin we would like to give you an overview of CI/CD & explain our needs for it at Dgraph Labs Inc.
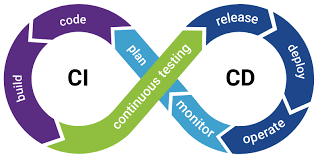
CI/CD DevOps Infinite Loop
image source credits
CI/CD is a two-step process that dramatically streamlines code development and delivery using the power of automation. CI (Continuous Integration) makes developer tasks around source code integration, testing and version control more efficient - so the software can get built with higher quality. CD (Continuous Deployment) automates software testing, release & deployment. CI/CD is often referred to as the DevOps Infinity Loop (as illustrated in the image above).
At Dgraph Labs Inc, we use CI/CD to facilitate our SDLC (Software Development Life Cycle) for our Dgraph Database and our Dgraph DBaaS (Cloud Offering) components. Like any tech company we want to minimize our bugs & deliver high quality products. The testing standards become strict for a Database company like ours, as a database becomes the most critical component of a software stack. To facilitate this, we follow the Practical Test Pyramid model along with other kinds of measurements instrumented into our CI/CD. To summarize, CI/CD helps us with:
CI/CD at Dgraph
Our CI/CD use-cases mostly revolve in the following areas: Building for Multi-Architectures (amd64/arm64), Testing (Unit/Integration & Load), Deployments, Security Audits, Code Linting, Benchmarking & CodeCoverage. We will cover some of these topics in our future blog posts.
As described above, Dgraph Labs Inc ran a self-managed on-prem TeamCity setup for CI/CD in the past. The setup looked similar to the image below.
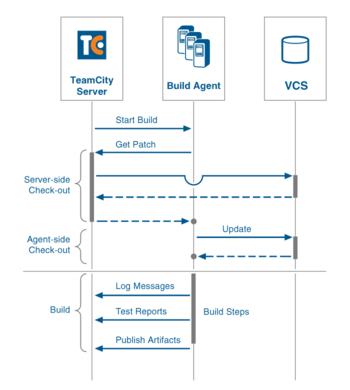
TeamCity Architecture
image source credits
This setup was quite difficult to manage, monitor & have a high-uptime for a small team like ours today. The work
infrastructure setup, ensuring right security posture and instrumenting observability on these systems. There were 3
issues here for us, and they were Compute Costs, Maintenance Efforts & Configuration Time.
Firstly, the Compute Costs was additive because we not only needed a Server & Agent Compute Machines, but we also needed
Observability Stack (& Instrumentation) for these critical systems. Secondly, the Maintenance Efforts on the issues we
encountered (like Security Patching, Upgrades, Disk-Issues, Inconsistent Test Results Reporting etc.) was taxing the
team and was taking time away from our development cycles. Lastly, the Configuration Time was also a problem for us
because the job configurations were outside our codebase (and in the Server), VCS configurations for new repo’s needed
instrumentation & we had to write our custom install/cleanups for basic setup tasks in the job definitions.
As a result, Compute Costs ⬆⬆, Maintenance Efforts
⬆⬆ & Configuration Time ⬆⬆ were all high. This led us
to re-think how we can transition to a new system that solved these issues and offered Public & Private repositories
support.
NOTE: TeamCity is a great product. As explained above time & easy-of-use
were driving factors that made us transition out.
Our research led us to GitHub Actions. Given that we were already on GitHub for our VCS, this made us explore this further. We were quite content with what it had to offer, as it came with immediate benefits. Notable architecture differences were around how there was a fully managed Server (unlike the previous setup) & how GitHub semi-managed the Runners (a.k.a. Agents). Below we show an example CD run for multi-architecture release for Dgraph Labs Inc on GitHub Actions.
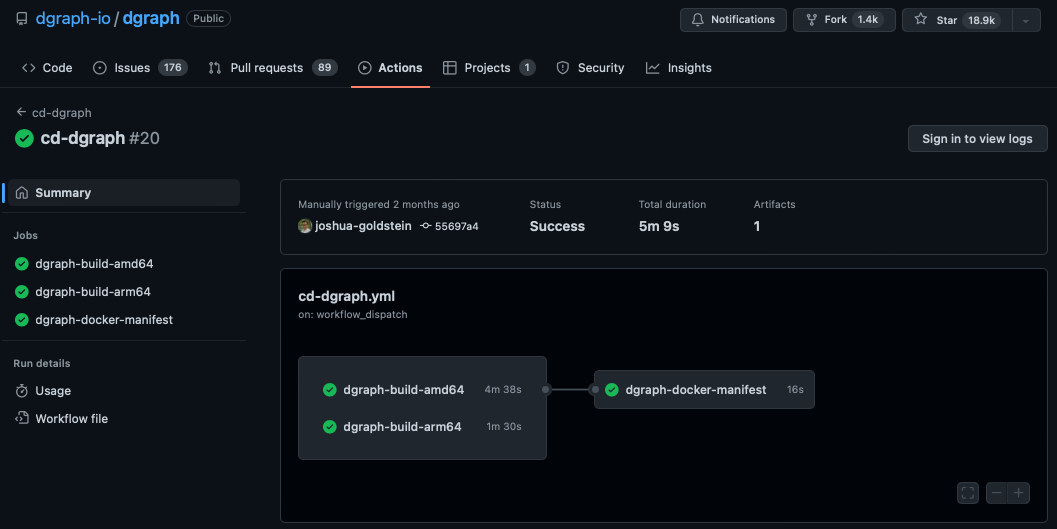
GitHub Actions CD steps for Dgraph
(everything well integrated to GitHub eco-system)
Firstly, the Compute Costs were lower because we only manage the
Self-Hosted Runners. We made
use of the free
GitHub-hosted runners
wherever possible. For jobs that required higher resource specs, we had the option to run them on higher resources using
Self-Hosted Runners. Secondly,
the Maintenance Costs reduced because we had fewer components to manage. Although, GitHub had done a great job
in simplifying the Runner setup steps - it still needed manual management - this was still a concern. Lastly,
the Configuration Time reduced drastically because of the Action Marketplace, which
provided pre-templated tasks to perform pre-setup and post-cleanup on the Runners. And with this transition, the code &
job definitions lived together (unlike our old setup).
As a result, our Compute Costs ⬆ reduced, Maintenance Efforts
⬆ reduced & Configuration Time ⬇ was a
great win. There was still some room to improve here, because we were manually attaching & detaching Runners on a need
basis. There was another problem here - the “Idle Runners” - it was leading to wasted resource spends.
As described in the previous step, our problems were limited to Compute Costs (idle runners) & Maintenance Efforts
(manual Runner attach/detach). We started exploring potential solutions for “Dynamic AutoScaling of GitHub
Runners”. There were 2 solutions we found, which were ARC &
Philips-Scalable-Runner. The
ARC was specific to container eco-system and did not apply to
us. The Philips-Scalable-Runner had
too many components
to facilitate this. So this led us to building our in-house solution.
Our design needed to solve these:
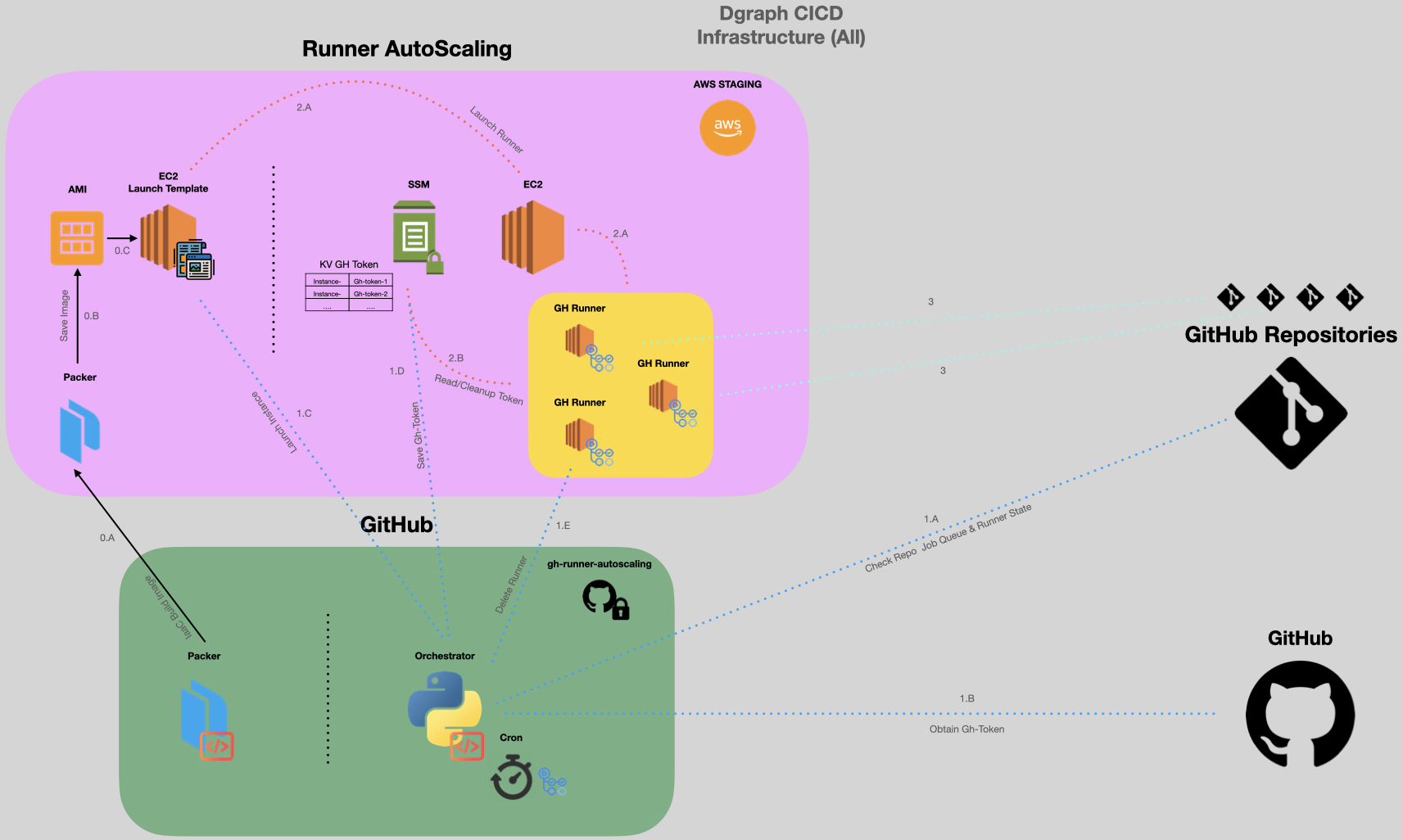
Dynamic AutoScaling of GitHub Runners
There are 3 logical pieces in this architecture, and they are:
VM Images, We bake custom AMI’s with a
specialized startup script in them. The startup script that we bake into the image, has a logic to connect to the
SSM Parameter Store & read its configuration
at startup. When the AMI comes up as an
EC2 instance, it will read its config from
SSM Parameter Store & self-configure itself to
GitHub to service our Jobs.SSM, we use SSM Parameter Store as a way to store Runner configurations.
This is essentially a KV store for configs. We store the Runner configurations as Values with the
EC2 Instance as the Key deliminator.Orchestrator, This is essentially our Controller (written in Python). The Orchestrator
monitors GitHub events. It has logic to Scale Up or Down based on the Job Queue &
available Runner count dynamically. This has hooks to GitHub &
AWS (SSM Parameter Store &
EC2) to facilitate this process. In the Scale Up phase, the Orchestrator will create an
SSM Parameter Store entry and follow it up by creating an
EC2 using the AMI
(through the Launch-Templates). In the Scale Down phase, the Orchestrator will delete the
SSM Parameter Store entry and follow it up by a deletion operation on the
created EC2 instance.Note: We are considering to Open Source this project. For that reason we have only given an overview and skipped the full implementation details. If you are interested to discuss further, do hit us up. We would love to partner.
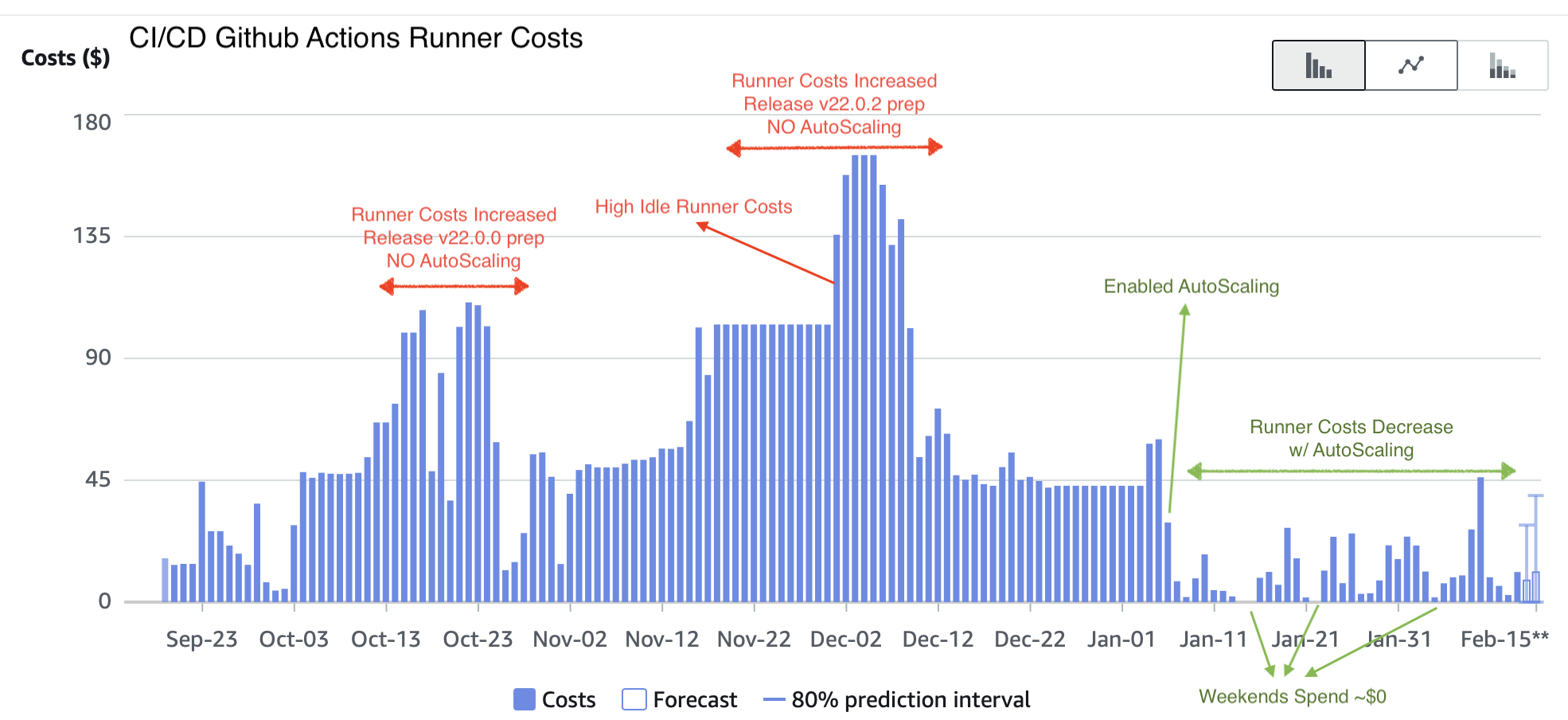
CI/CD Cost Graph
We enabled “Dynamic AutoScaling of GitHub Runners” on 2023-Jan-06. And we have seen drastic reduction in our spends
since then. Not only has it saved us money, it has also saved us Engineering time by eliminating Maintenance Efforts.
The “Idle Runner” problem was real, and it would have affected us in different ways had we not addressed.
~$0 (as it’s a break day)~87%)~$63.36/day (or $1,900.8/month) ⬆⬆~$8.12/day (or ~$243.6/month) ⬇⬇~$1.2/PR for dgraph-io/dgraph repositoryNOTE: We will continue to see more savings over time (as the savings compound here).
To conclude, the table shows our OKRs and how we went about solving for these. The last column is where we are today in our journey.
| OKRs | Old Setup TeamCity |
New Setup Github Actions |
New Setup GitHub Actions w/ AutoScaling |
|---|---|---|---|
Compute Costs |
⬆⬆ | ⬆ | ⬇ |
Maintenance Costs |
⬆⬆ | ⬆ | ⬇ |
Configuration Time Costs |
⬆⬆ | ⬇ | ⬇ |
On behalf of the project team, I would like to express our gratitude to all the internal contributors who have played a crucial role in bringing this project to fruition. Their dedication and hard work have been instrumental in making this idea a reality.
A special thanks goes to Kevin for his efforts in implementing and testing the initial concept. His efforts ensured that our vision could be transformed into a tangible execution.
We would also like to acknowledge the contributions of Aditya (co-author), Anurag, Dilip & Joshua. Their valuable insights, expertise, and collaboration have greatly enriched the project.
