
Encryption at Rest in Dgraph and Badger
We built “Encryption at Rest” in Badger v2. Encryption is complex, but important. With this b ...
Learn more

When we started working on Badger, the aim was to keep things stupid simple. We needed to get rid of Cgo from Dgraph codebase, while also building something which can perform really well. We wanted to create it for ourselves and the broader Go community. Go has been a language of choice for many databases, and providing a performant native Go key-value store seemed like a win for everyone.
As Badger is gaining popularity, we see the limitations of our initial choices. The choice to not add transactions caused issues for many users. In fact, that’s something we are witnessing in Dgraph as well. So, we decided to support transactions in Badger (and successively in Dgraph).
For a good design, we spent time reading through six popular papers on the subject. In particular, Yabandeh’s A Critique of Snapshot Isolation provided a sound basis for allowing execution of transactions concurrently, delivering serializable snapshot isolation, avoiding write-skews. While this paper is designed for distributed systems, its applicability extends to any single node system wanting to support concurrent transactional execution.
Transactions in Badger execute concurrently. When they start, they pick up a read timestamp from an in-memory oracle. Badger now supports MVCC, so all reads are done based on this timestamp. As reads are performed, we store a fingerprint of the key (fingerprint instead of the key to save space. In a very rare case, this can lead to a false negative conflict detection, aborting a transaction, requiring a retry). In a read-only transaction, we avoid tracking reads altogether. This prevents a memory blowup if you are taking a snapshot or backup of Badger.
As writes are performed in the transaction, we maintain an internal cache of these writes within the transaction. Thus, any follow up reads on the same key by this transaction would see this write. But, other transactions won’t, providing Isolation and Consistency.
Finally, when Commit is called, we send our read fingerprints to Oracle and ask for a commit timestamp. Oracle will check if the read rows have since been updated (row commit ts > txn read ts). If so, it would return a conflict, and the transaction would abort. This is indicated by Commit method returning an ErrConflict error.
If no conflict were detected, Oracle would assign a new unique commit timestamp, and update a local in-memory commit map with all the written keys’ fingerprints and this commit timestamp. Thus, any future commits would be checked against these updates for conflict detection. Note that even if the transaction fails later (due to a write to disk failure), having this commit record in memory doesn’t cause any logical issues.
At this point, each key is suffixed with the commit timestamp, to provide multiversion concurrency control. Thus, Badger won’t overwrite any data.
Once we have a commit timestamp, the writes from this and other transactions are queued in a channel, batched up, and written to value log. Once value log write is successful, we are assured of Durability. In case of a crash, a value log replay would be able to pick up these transactions.
Once written to value log, the LSM tree would be updated, making these writes visible to future transactions. If writing to value log fails, however, the writes won’t make it to LSM tree, and the transaction is abandoned. Because LSM tree wasn’t updated, the writes won’t be visible to any other transaction, thus ensuring Atomicity.
Oracle keeps track of commit-pending transactions in a min heap. Once the transaction is successfully committed, Oracle would advance its read timestamp. Any new transactions would now start from this version.
This particular strategy is different from Yabandeh’s paper, where typically locks are acquired upfront on the keys which are written. Given Badger isn’t a distributed database and isn’t marred by the unreliability of network, we could simplify the implementation considerably by using a min heap to update read timestamp.
To quickly benchmark the performance of Badger writes, we wrote 1M key-value pairs, values being of different sizes. We set synchronous writes to true. We ran this for Badger, Bolt, and LMDB.
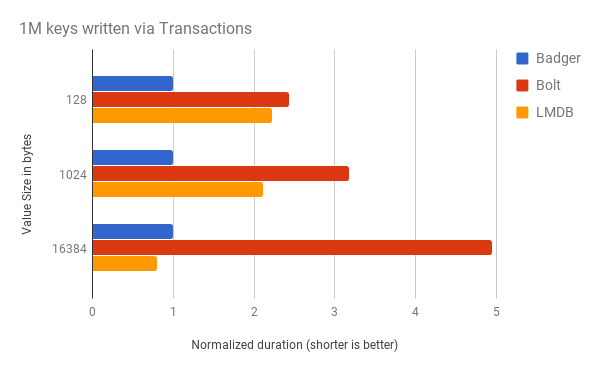
In absolute numbers, Badger wrote 1M keys with 128B and 1kB value in 10 and 16 seconds. For 16kB values, Badger took 1m20s to write 1M keys.
Badger’s write throughput using ACID transactions was at least 2-5x faster than Bolt. Compared to LMDB, Badger was 2x quicker in two of the three test cases.
You can see the spreadsheet here, and the benchmark log here.
This is a huge API change in Badger. In fact, we ripped up all the existing APIs from KV struct, into the new Txn struct. While doing so, we also got rid of certain APIs like CompareAndSet and SetIfAbsent, which are no longer required given transactions. At the same time, we’re renamed Badger.KV to Badger.DB, which at this point, Badger is. An ACID compliant database providing concurrent transactions and serializable snapshot isolation.
We hope you enjoy these changes and use Badger in your project!
